Chapter 9
(More CREOLE) Plugins [#]
For the previous reader was none other than myself. I had already read this book long ago.
The old sickness has me in its grip again: amnesia in litteris, the total loss of literary memory. I am overcome by a wave of resignation at the vanity of all striving for knowledge, all striving of any kind. Why read at all? Why read this book a second time, since I know that very soon not even a shadow of a recollection will remain of it? Why do anything at all, when all things fall apart? Why live, when one must die? And I clap the lovely book shut, stand up, and slink back, vanquished, demolished, to place it again among the mass of anonymous and forgotten volumes lined up on the shelf.
…
But perhaps - I think, to console myself - perhaps reading (like life) is not a matter of being shunted on to some track or abruptly off it. Maybe reading is an act by which consciousness is changed in such an imperceptible manner that the reader is not even aware of it. The reader suffering from amnesia in litteris is most definitely changed by his reading, but without noticing it, necause as he reads, those critical faculties of his brain that could tell him that change is occurring are changing as well. And for one who is himself a writer, the sickness may conceivably be a blessing, indeed a necessary precondition, since it protects him against that crippling awe which every great work of literature creates, and because it allows him to sustain a wholly uncomplicated relationship to plagiarism, without which nothing original can be created.
Three Stories and a Reflection, Patrick Suskind, 1995 (pp. 82, 86).
This chapter describes additional CREOLE resources which do not form part of ANNIE.
9.1 Document Reset [#]
The document reset resource enables the document to be reset to its original state, by removing all the annotation sets and their contents, apart from the one containing the document format analysis (Original Markups). An optional parameter, keepOriginalMarkupsAS, allows users to decide whether to keep the Original Markups AS or not while reseting the document. This resource is normally added to the beginning of an application, so that a document is reset before an application is rerun on that document.
9.2 Verb Group Chunker [#]
The rule-based verb chunker is based on a number of grammars of English [Cobuild 99, Azar 89]. We have developed 68 rules for the identification of non recursive verb groups. The rules cover finite (’is investigating’), non-finite (’to investigate’), participles (’investigated’), and special verb constructs (’is going to investigate’). All the forms may include adverbials and negatives. The rules have been implemented in JAPE. The finite state analyser produces an annotation of type ’VG’ with features and values that encode syntactic information (’type’, ’tense’, ’voice’, ’neg’, etc.). The rules use the output of the POS tagger as well as information about the identity of the tokens (e.g. the token ’might’ is used to identify modals).
The grammar for verb group identification can be loaded as a Jape grammar into the GATE architecture and can be used in any application: the module is domain independent.
9.3 Noun Phrase Chunker [#]
The NP Chunker application is a Java implementation of the Ramshaw and Marcus BaseNP chunker (in fact the files in the resources directory are taken straight from their original distribution) which attempts to insert brackets marking noun phrases in text which has been marked with POS tags in the same format as the output of Eric Brill’s transformational tagger. The output from this version should be identical to the output of the oringinal C++/Perl version released by Ramshaw and Marcus.
For more information about baseNP structures and the use of tranformation-based learning to derive them, see [Ramshaw & Marcus 95].
9.3.1 Differences from the Original
The major difference is the assumption is made that if a POS tag is is not in the mapping file then it is tagged as ’I’. The original version simply failed if an unknown POS tag was encountered. When using the GATE wrapper the chunk tag can be changed from ’I’ to any other legal tag (B or O).
9.3.2 Using the Chunker
The Chunker requires the Creole plugin ”NP_Chunking” to be loaded. The two loadtime parameters are simply urls pointing at the POS tag dictionary and the rules file, which should be set automatically.
The chunker requires the following PRs to have been run first: tokeniser, sentence splitter, POS tagger.
9.4 OntoText Gazetteer [#]
The OntoText Gazetteer is a Natural Gazetteer, implemented from the OntoText Lab (http://www.ontotext.com/). Its implementaion is based on simple lookup in several java.util.HashMap, and is inspired by the strange idea of Atanas Kiryakov, that searching in HashMaps will be faster than a search in a Finite State Machine (FSM).
Here follows a description of the algorithm that lies behind this implementation:
Every phrase i.e. every list entry is separated into several parts. The parts are determined by the whitespaces lying among them. e.g. the phrase : ”form is emptiness” has three parts : form, is & emptiness. There is also a list of HashMaps: mapsList which has as many elements as the longest (in terms of ”count of parts”) phrase in the lists. So the first part of a phrase is placed in the first map. The first part + space + second part is placed in the second map, etc. The full phrase is placed in the appropriate map, and a reference to a Lookup object is attached to it.
On first sight it seems that this algorithm is certainly much more memory-consuming than a finite state machine (FSM) with the parts of the phrases as transitions, but this is actually not so important since the average length of the phrases (in parts) in the lists is 1.1. On the other hand, one advantage of the algorithm is that, although unconventional, on average it takes four times less memory and works three times faster than an optimized FSM implementation.
The lookup part is implemented in execute() so a lot of tokenization takes place there. After defining the candidates for phrase-parts, we build a candidate phrase and try to look it up in the maps (in which map again depends on the count of parts in the current candidate phrase).
9.4.1 Prerequisites
The phrases to be recognised should be listed in a set of files, one for each type of occurrence (as for the standard gazetteer).
The gazetteer is built with the information from a file that contains the set of lists (which are files as well) and the associated type for each list. The file defining the set of lists should have the following syntax: each list definition should be written on its own line and should contain:
- the file name (required)
- the major type (required)
- the minor type (optional)
- the language(s) (optional)
The elements of each definition are separated by ”:”. The following is an example of a valid definition:
personmale.lst:person:male:english
|
Each file named in the lists definition file is just a list containing one entry per line.
When this gazetter is run over some input text (a GATE document) it will generate annotations of type Lookup having the attributes specified in the definition file.
9.4.2 Setup
In order to use this gazetteer from within GATE the following should reside in the creole setup file (creole.xml):
<RESOURCE>
<NAME>OntoText Gazetteer</NAME> <CLASS>com.ontotext.gate.gazetteer.NaturalGazetteer</CLASS> <COMMENT>A list lookup component. for documentation please refer to (www.ontotext.com/gate/gazetteer/documentation/index.html). For licence information please refer to (www.ontotext.com/gate/gazetteer/documentation/licence.ontotext.html) or to licence.ontotext.html in the lib folder of GATE</COMMENT> <PARAMETER NAME="document" RUNTIME="true" COMMENT="The document to be processed">gate.Document</PARAMETER> <PARAMETER NAME="annotationSetName" RUNTIME="true" COMMENT="The annotation set to be used for the generated annotations" OPTIONAL="true">java.lang.String</PARAMETER> <PARAMETER NAME="listsURL" DEFAULT="gate:/creole/gazeteer/default/lists.def" COMMENT="The URL to the file with list of lists" SUFFIXES="def">java.net.URL</PARAMETER> <PARAMETER DEFAULT="UTF-8" NAME="encoding" COMMENT="The encoding used for reading the definitions">java.lang.String</PARAMETER> <PARAMETER DEFAULT="true" NAME="caseSensitive" COMMENT="Should this gazetteer diferentiate on case. Currently the Gazetteer works only in case sensitive mode.">java.lang.Boolean</PARAMETER> <ICON>shefGazetteer.gif</ICON> </RESOURCE> |
9.5 Flexible Gazetteer [#]
The Flexible Gazetteer provides users with the flexibility to choose their own customized input and an external Gazetteer. For example, the user might want to replace words in the text with their base forms (which is an output of the Morphological Analyser) or to segment a Chinese text (using the Chinese Tokeniser) before running the Gazetteer on the Chinese text.
The Flexible Gazetteer performs lookup over a document based on the values of an arbitrary feature of an arbitrary annotation type, by using an externally provided gazetteer. It is important to use an external gazetteer as this allows the use of any type of gazetteer (e.g. an Ontological gazetteer).
Input to the Flexible Gazetteer:
Runtime parameters:
- Document – the document to be processed
- inputAnnotationSetName The annotationSet where the Flexible Gazetteer should search for the AnnotationType.feature specified in the inputFeatureNames.
- outputAnnotationSetName The AnnotationSet where Lookup annotations should
be placed.
Creation time parameters:
- inputFeatureNames – when selected, these feature values are used to replace the corresponding original text. A temporary document is created from the values of the specified features on the specified annotation types. For example: for Token.string the temporary document will have the same content as the original one but all the SpaceToken annotations will have been replaced by single spaces.
- gazetteerInst – the actual gazetteer instance, which should run over a temporary document. This generates the Lookup annotations with features. This must be an instance of gate.creole.gazetteer.Gazetteer which has already been created.
Once the external gazetteer has annotated text with Lookup annotations, Lookup annotations on the temporary document are converted to Lookup annotations on the original document. Finally the temporary document is deleted.
9.6 Gazetteer List Collector [#]
The gazetteer list collector collects occurrences of entities directly from a set of annotated training texts, and populates gazetteer lists with the entities. The entity types and structure of the gazetteer lists are defined as necessary by the user. Once the lists have been collected, a semantic grammar can be used to find the same entities in new texts.
An empty list must be created first for each annotation type, if no list exists already. The set of lists must be loaded into GATE before the PR can be run. If a list already exists, the list will simply be augmented with any new entries. The list collector will only collect one occurrence of each entry: it first checks that the entry is not present already before adding a new one.
There are 4 runtime parameters:
- annotationTypes: a list of the annotation types that should be collected
- gazetteer: the gazetteer where the results will be stored (this must be already loaded in GATE)
- markupASname: the annotation set from which the annotation types should be collected
- theLanguage: sets the language feature of the gazetteer lists to be created to the appropriate language (in the case where lists are collected for different languages)
Figure 9.1 shows a screenshot of a set of lists collected automatically for the Hindi language. It contains 4 lists: Person, Organisation, Location and a list of stopwords. Each list has a majorType whose value is the type of list, a minorType ”inferred” (since the lists have been inferred from the text), and the language ”Hindi”.
|
|
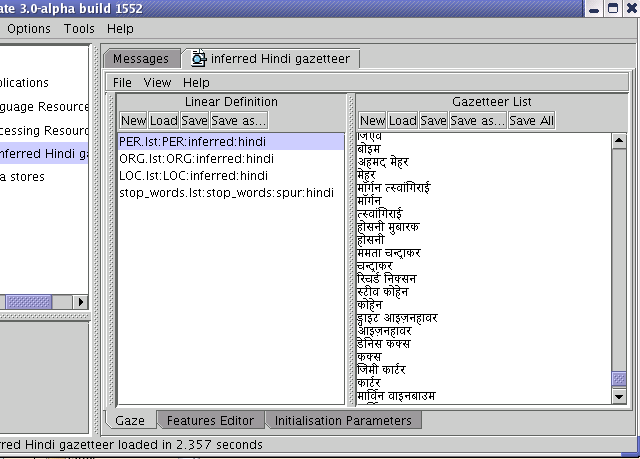
The list collector also has a facility to split the Person names that it collects into their individual tokens, so that it adds both the entire name to the list, and adds each of the tokens to the list (i.e. each of the first names, and the surname) as a separate entry. When the grammar annotates Persons, it can require them to be at least 2 tokens or 2 consecutive Person Lookups. In this way, new Person names can be recognised by combining a known first name with a known surname, even if they were not in the training corpus. Where only a single token is found that matches, an Unknown entity is generated, which can later be matched with an existing longer name via the orthomatcher component which performs orthographic coreference between named entities. This same procedure can also be used for other entity types. For example, parts of Organisation names can be combined together in different ways. The facility for splitting Person names is hardcoded in the file gate/src/gate/creole/GazetteerListsCollector.java and is commented.
9.7 Tree Tagger [#]
The TreeTagger is a language-independent part-of-speech tagger, which currently supports English, French, German, Spanish, Italian and Bulgarian (although the latter two are not available in GATE). It is integrated with GATE using a GATE CREOLE wrapper, originally designed by the CLaC lab (Computational Linguistics at Concordia), Concordia University, Montreal (http://www.cs.concordia.ca/CLAC).
The GATE wrapper calls TreeTagger as an external program, passing gate Tokens as input, and adding two new features to them, which hold the features as described below:
- Features of the TreeTaggerToken:
- category: the part-of-speech tag of the token;
- lemma: the lemma of the token
- Runtime parameters:
- document: the document to be processed
- treeTaggerBinary: a URL indicating the location of a (language-specific) GATE TreeTagger wrapper shell script. Note that the scripts used by GATE are different from the original TreeTagger scripts (in cmd), since the latter perform their own tokenisation, whereas the GATE scripts rely on Token annotations as they have been computed by a Tokeniser component. The GATE scripts reside in plugins/TreeTagger/resources. Currently available are command scripts for German, French, and Spanish.
- encoding: The character encoding to use when passing data to and from the tagger. This must be ISO-8859-1 to work with the standard TreeTagger distribution – do not change it unless you know what you are doing.
- failOnUnmappableChar: What to do if a character is encountered in the document which cannot be represented in the selected encoding. If the parameter is true (the default), unmappable characters cause the wrapper to throw an exception and fail. If set to false, unmappable characters are replaced by question marks when the document is passed to the tagger. This is useful if your documents are largely OK but contain the odd character from outside the Latin-1 range.
- Requirement: The TreeTagger, which is available from
http://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger/DecisionTreeTagger.html,
must be correctly installed on the same machine as GATE. It must be installed in a directory
that does not contain any spaces in its path, otherwise the scripts will fail. Once the
TreeTagger is installed, the first two lines of the shell script may need to be modified to
indicate the installed location of the bin and lib directories of the tagger, as shown
below:
# THESE VARIABLES HAVE TO BE SET:
BIN=/usr/local/clactools/TreeTagger/bin
LIB=/usr/local/clactools/TreeTagger/lib
The TreeTagger plugin works on any platform that supports the tree tagger tool, including Linux, Mac OS X and Windows, but the GATE-specific scripts require a POSIX-style Bourne shell with the gawk, tr and grep commands, plus Perl for the Spanish tagger. For Windows this means that you will need to install the appropriate parts of the Cygwin environment from http://www.cygwin.com and set the system property treetagger.sh.path to contain the path to your sh.exe (typically C:\cygwin\bin\sh.exe). If this property is set, the TreeTagger plugin runs the shell given in the property and passes the tagger script as its first argument; without the property, the plugin will attempt to run the shell script directly, which fails on Windows with a cryptic “error=193”. For the GATE GUI, put the following line in build.properties (see section 3.3, and note the extra backslash before each backslash and colon in the path):
run.treetagger.sh.path: C\:\\cygwin\\bin\\sh.exe
|
Figure 9.2 shows a screenshot of a French document processed with the TreeTagger.
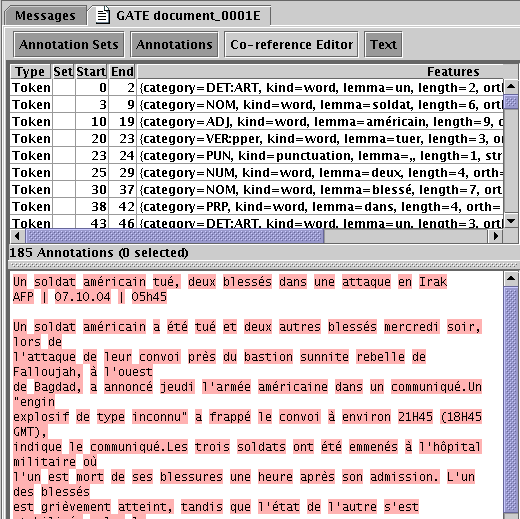
9.7.1 POS tags
For English the POS tagset is a slightly modified version of the Penn Treebank tagset, where the second letter of the tags for verbs distinguishes between ”be” verbs (B), ”have” verbs (H) and other verbs (V).
The tagsets for French, German, Italian, Spanish and Bulgarian can be found in the original TreeTagger documenation at http://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger/DecisionTreeTagger.html..
9.8 Stemmer [#]
The stemmer plugin consists of a set of stemmers PRs for the following 11 European languages: Danish, Dutch, English, Finnish, French, German, Italian, Norwegian, Portuguese, Russian, Spanish and Swedish. These take the form of wrappers for the Snowball stemmers freely available from http://snowball.tartarus.org. Each Token is annotated with a new feature ”stem”, with the stem for that word as its value. The stemmers should be run as other PRs, on a document that has been tokenised.
9.8.1 Algorithms
The stemmers are based on the Porter stemmer for English [Porter 80], with rules implemented in Snowball e.g.
define Step_1a as
( [substring] among ( ’sses’ (<-’ss’) ’ies’ (<-’i’) ’ss’ () ’s’ (delete) ) |
9.9 GATE Morphological Analyzer [#]
The Morphological Analyser PR can be found in the Tools plugin. It takes as input a tokenized GATE document. Considering one token and its part of speech tag, one at a time, it identifies its lemma and an affix. These values are than added as features on the Token annotation. Morpher is based on certain regular expression rules. These rules were originally implemented by Kevin Humphreys in GATE1 in a programming language called Flex. Morpher has a capability to interepret these rules with an extension of allowing users to add new rules or modify the existing ones based on their requirements. In order to allow these operations with as little effort as possible, we changed the way these rules are written. More information on how to write these rules is explained later in Section 9.9.1.
Two types of parameters, Init-time and run-time, are required to instantiate and execute the PR.
- rulesFile (Init-time) The rule file has several regular expression patterns. Each pattern has two parts, L.H.S. and R.H.S. L.H.S. defines the regular expression and R.H.S. the function name to be called when the pattern matches with the word under consideration. Please see 9.9.1 for more information on rule file.
- caseSensitive (init-time) By default, all tokens under consideration are converted into lowercase to identify their lemma and affix. If the user selects caseSensitive to be true, words are no longer converted into lowercase.
- document (run-time) Here the document must be an instance of a GATE document.
- affixFeatureName Name of the feature that should hold the affix value.
- rootFeatureName Name of the feature that should hold the root value.
- annotationSetName Name of the annotationSet that contains Tokens.
- considerPOSTag Each rule in the rule file has a separate tag, which specifies which rule to consider with what part-of-speech tag. If this option is set to false, all rules are considered and matched with all words. This option is very useful. For example if the word under consideration is ”singing”. ”singing” can be used as a noun as well as a verb. In the case where it is identified as a verb, the lemma of the same would be ”sing” and the affix ”ing”, but otherwise there would not be any affix.
9.9.1 Rule File [#]
GATE provides a default rule file, called default.rul, which is available under the gate/plugins/Tools/morph/resources directory. The rule file has two sections.
- Variables
- Rules
Variables
The user can define various types of variables under the section defineVars. These variables can be used as part of the regular expressions in rules. There are three types of variables:
- Range With this type of variable, theuser can specify the range of characters. e.g. A ==> [-a-z0-9]
- Set With this type of variable, user can also specify a set of characters, where one character at a time from this set is used as a value for the given variable. When this variable is used in any regular expression, all values are tried one by one to generate the string which is compared with thecontents of the document. e.g. A ==> [abcdqurs09123]
- Strings Where in the two types explained above, variables can hold only one character from the given set or range at a time, this allows specifying strings as possibilities for the variable. e.g. A ==> ”bb” OR ”cc” OR ”dd”
Rules
All rules are declared under the section defineRules. Every rule has two parts, LHS and RHS. The LHS specifies the regular expresssion and the RHS the function to be called when the LHS matches with the given word. ”==>” is used as delimeter between the LHS and RHS.
The LHS has the following syntax:
< ” * ”—”verb”—”noun” >< regularexpression >.
User can specify which rule to be considered when the word is identified as ”verb” or ”noun”. ”*” indicates that the rule should be considered for all part-of-speech tags. If the part-of-speech should be used to decide if the rule should be considered or not can be enabled or disabled by setting the value of considerPOSTags option. Combination of any string along with any of the variables declared under the defineVars section and also the Klene operators, ”+” and ”*”, can be used to generate the regular expressions. Below we give few examples of L.H.S. expressions.
- <verb>”bias”
- <verb>”canvas”{ESEDING} ”ESEDING” is a variable defined under the defineVars section. Note: variables are enclosed with ”{” and ”}”.
- <noun>({A}*”metre”) ”A” is a variable followed by the Klene operator ”*”, which means ”A” can occur zero or more times.
- <noun>({A}+”itis”) ”A” is a variable followed by the Klene operator ”+”, which means ”A” can occur one or more times.
- < * >”aches” ”< * >” indicates that the rule should be considered for all part-of-speech tags.
On the RHS of the rule, the user has to specify one of the functions from those listed below. These rules are hard-coded in the Morph PR in GATE and are invoked if the regular expression on the LHS matches with any particular word.
- stem(n, string, affix) Here,
- n = number of characters to be truncated from the end of the string.
- string = the string that should be concatenated after the word to produce the root.
- affix = affix of the word
- irreg_stem(root, affix) Here,
- root = root of the word
- affix = affix of the word
- null_stem() This means words are themselves the base forms and should not be analyzed.
- semi_reg_stem(n,string) semir_reg_stem function is used with the regular expressions that end with any of the {EDING} or {ESEDING} variables defined under the variable section. If the regular expression matches with the given word, this function is invoked, which returns the value of variable (i.e. {EDING} or {ESEDING}) as an affix. To find a lemma of the word, it removes the n characters from the back of the word and adds the string at the end of the word.
9.10 MiniPar Parser [#]
MiniPar is a shallow parser. In its shipped version, it takes one sentence as an input and determines the dependency relationships between the words of a sentence. It parses the sentence and brings out the information such as:
- the lemma of the word;
- the part of speech of the word;
- the head modified by this word;
- name of the dependency relationship between this word and the head;
- the lemma of the head.
In the version of MiniPar integrated in GATE, it generates annotations of type“DepTreeNode” and the annotations of type “[relation]” that exists between the head and the child node. The document is required to have annotations of type “Sentence”, where each annotation consists of a string of the sentence.
Minipar takes one sentence at a time as an input and generates the tokens of type “DepTreeNode”. Later it assigns relation between these tokens. Each DepTreeNode consists of feature called “word”: this is the actual text of the word.
For each and every annotation of type “[Rel]”, where ‘Rel’ is obj, pred etc. This is the name of the dependency relationship between the child word and the head word (see Section 9.10.5). Every “[Rel]” annotation is assigned four features:
- child_word: this is the text of the child annotation;
- child_id: IDs of the annotations which modify the current word (if any).
- head_word: this is the text of the head annotation;
- head_id: ID of the annotation modified by the child word (if any);
Figure 9.3 shows a MiniPar annotated document in GATE.
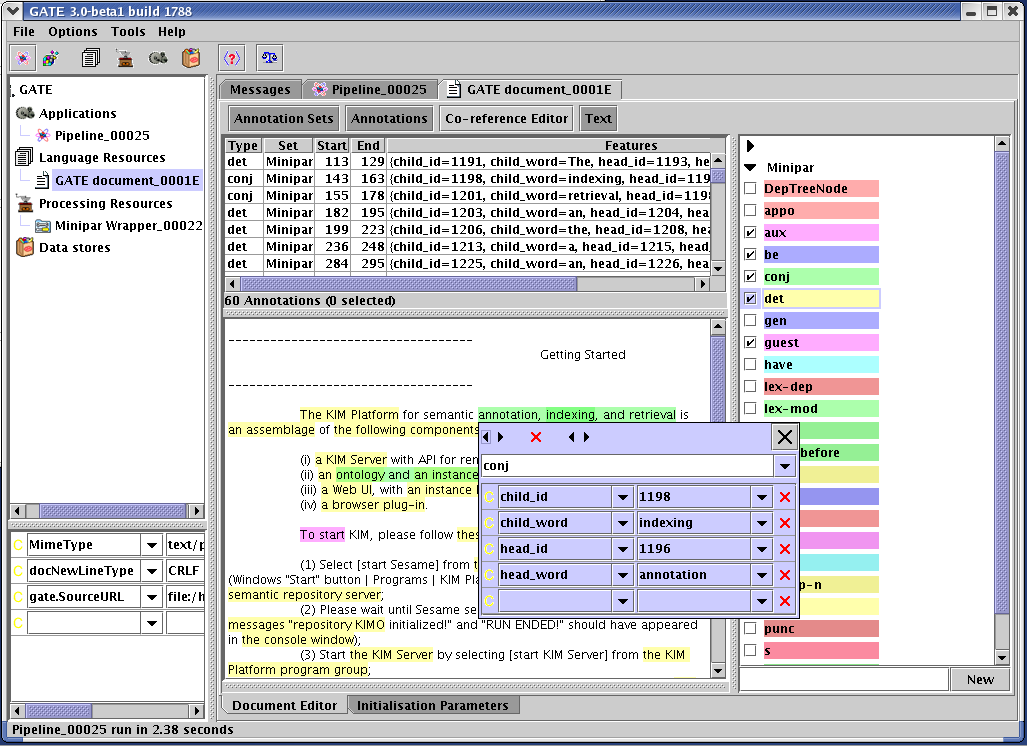
9.10.1 Platform Supported
MiniPar in GATE is supported for the Linux and Windows operating systems. Trying to instantiate this PR on any other OS will generate the ResourceInstantiationException.
9.10.2 Resources
MiniPar in GATE is shipped with four basic resources:
- MiniparWrapper.jar: this is a JAVA Wrapper for MiniPar;
- creole.XML: this defines the required parameters for MiniPar Wrapper;
- minipar.linux: this is a modified version of pdemo.cpp.
- minipar-windows.exe : this is a modified version of pdemo.cpp compiled to work on windows.
9.10.3 Parameters
The MiniPar wrapper takes six parameters:
- annotationTypeName: new annotations are created with this type, default is ”DepTreeNode”;
- annotationInputSetName: annotations of Sentence type are provided as an input to MiniPar and are taken from the given annotationSet;
- annotationOutputSetName: All annotations created by Minipar Wrapper are stored under the given annotationOutputSet;
- document: the GATE document to process;
- miniparBinary: location of the MiniPar Binary file (i.e. either minipar.linux or minipar-windows.exe. These files are available under gate/plugins/minipar/ directory);
- miniparDataDir: location of the ”data” directory under the installation directory of MINIPAR. default is ”%MINIPAR_HOME%/data”.
9.10.4 Prerequisites
The MiniPar wrapper requires the MiniPar library to be available on the underlying Linux/Windows machine. It can be downloaded from the MiniPar homepage.
9.10.5 Grammatical Relationships [#]
appo "ACME president, --appo-> P.W. Buckman"
aux "should <-aux-- resign" be "is <-be-- sleeping" c "that <-c-- John loves Mary" comp1 first complement det "the <-det ‘-- hat" gen "Jane’s <-gen-- uncle" i the relationship between a C clause and its I clause inv-aux inverted auxiliary: "Will <-inv-aux-- you stop it?" inv-be inverted be: "Is <-inv-be-- she sleeping" inv-have inverted have: "Have <-inv-have-- you slept" mod the relationship between a word and its adjunct modifier pnmod post nominal modifier p-spec specifier of prepositional phrases pcomp-c clausal complement of prepositions pcomp-n nominal complement of prepositions post post determiner pre pre determiner pred predicate of a clause rel relative clause vrel passive verb modifier of nouns wha, whn, whp: wh-elements at C-spec positions obj object of verbs obj2 second object of ditransitive verbs subj subject of verbs s surface subjec |
9.11 RASP Parser [#]
RASP (Robust Accurate Statistical Parsing) is a robust parsing system for English, developed by the Natural Language and Computational Linguistics group at the University of Sussex.
This plugin, developed by DigitalPebble, provides four wrapper PRs that call the RASP modules as external programs, as well as a JAPE component that translates the output of the ANNIE POS Tagger (section 8.5).
- RASP2 Tokenizer
- This PR requires Sentence annotations and creates Token annotations with a string feature. Note that sentence-splitting must be carried out before tokenization; the the RegEx Sentence Splitter (see section 8.4) is suitable for this. (Alternatively, you can use the ANNIE Tokenizer (section 8.1) and then the ANNIE Sentence Splitter (section 8.3); their output is compatible with the other PRs in this plugin).
- RASP2 POS Tagger
- This requires Token annotations and creates WordForm annotations with pos, probability, and string features.
- RASP2 Morphological Analyser
- This requires WordForm annotations (from the POS Tagger) and adds lemma and suffix features.
- RASP2 Parser
- This requires the preceding annotation types and creates multiple Dependency annotations to represent a parse of each sentence.
- RASP POS Converter
- This PR requires Token annotations with a category feature as produced by the ANNIE POS Tagger (see section 8.5 and creates WordForm annotations in the RASP Format. The ANNIE POS Tagger and this Converter can together be used as a substitute for the RASP2 POS Tagger.
Here are some examples of corpus pipelines that can be correctly constructed with these PRs.
- RegEx Sentence Splitter
- RASP2 Tokenizer
- RASP2 POS Tagger
- RASP2 Morphological Analyser
- RASP2 Parser
- RegEx Sentence Splitter
- RASP2 Tokenizer
- ANNIE POS Tagger
- RASP POS Converter
- RASP2 Morphological Analyser
- RASP2 Parser
- ANNIE Tokenizer
- ANNIE Sentence Splitter
- RASP2 POS Tagger
- RASP2 Morphological Analyser
- RASP2 Parser
- ANNIE Tokenizer
- ANNIE Sentence Splitter
- ANNIE POS Tagger
- RASP POS Converter
- RASP2 Morphological Analyser
- RASP2 Parser
Futher documentation is included in the directory gate/plugins/rasp/doc/.
The RASP package, which provides the external programs, is available from the RASP web page.
RASP is only supported for Linux operating systems. Trying to run it on any other operating systems will generate an exception with the message: “The RASP cannot be run on any other operating systems except Linux.”
It must be correctly installed on the same machine as GATE, and must be installed in a directory whose path does not contain any spaces (this is a requirement of the RASP scripts as well as the wrapper). Before trying to run scripts for the first time, edit rasp.sh and rasp_parse.sh to set the correct value for the shell variable RASP, which should be the file system pathname where you have installed the RASP tools (for example, RASP=/opt/RASP or RASP=/usr/local/RASP. You will need to enter the same path for the initialization parameter raspHome for the POS Tagger, Morphological Analyser, and Parser PRs.
(On some systems the arch command used in the scripts is not available; a work-around is to comment that line out and add arch=’ix86_linux’, for example.)
(The previous version of the RASP plugin can now be found in plugins/Obsolete/rasp.)
9.12 SUPPLE Parser (formerly BuChart) [#]
The BuChart parser has been removed and replaced by SUPPLE: The Sheffield University Prolog Parser for Language Engineering. If you have an application which uses BuChart and wish to upgrade to a later version of GATE than 3.1 you must upgrade your application to use SUPPLE.
SUPPLE is a bottom-up parser that constructs syntax trees and logical forms for English sentences. The parser is complete in the sense that every analysis licensed by the grammar is produced. In the current version only the ’best’ parse is selected at the end of the parsing process. The English grammar is implemented as an attribute-value context free grammar which consists of subgrammars for noun phrases (NP), verb phrases (VP), prepositional phrases (PP), relative phrases (R) and sentences (S). The semantics associated with each grammar rule allow the parser to produce logical forms composed of unary predicates to denote entities and events (e.g., chase(e1), run(e2)) and binary predicates for properties (e.g. lsubj(e1,e2)). Constants (e.g., e1, e2) are used to represent entity and event identifiers. The GATE SUPPLE Wrapper stores syntactic infomation produced by the parser in the gate document in the form of parse annotations containing a bracketed representation of the parse; and semantics annotations that contains the logical forms produced by the parser. It also produces SyntaxTreeNode annotations that allow viewing of the parse tree for a sentence (see section 9.12.4).
9.12.1 Requirements
The SUPPLE parser is written in Prolog, so you will need a Prolog interpreter to run the parser. A copy of PrologCafe (http://kaminari.scitec.kobe-u.ac.jp/PrologCafe/), a pure Java Prolog implementation, is provided in the distribution. This should work on any platform but it is not particularly fast. SUPPLE also supports the open-source SWI Prolog (http://www.swi-prolog.org) and the commercially licenced SICStus prolog (http://www.sics.se/sicstus, SUPPLE supports versions 3 and 4), which are available for Windows, Mac OS X, Linux and other Unix variants. For anything more than the simplest cases we recommend installing one of these instead of using PrologCafe.
9.12.2 Building SUPPLE
The SUPPLE plugin must be compiled before it can be used, so you will require a suitable Java SDK (GATE itself requires only the JRE to run). To build SUPPLE, first edit the file build.xml in the SUPPLE directory under plugins, and adjust the user-configurable options at the top of the file to match your environment. In particular, if you are using SWI or SICStus Prolog, you will need to change the swi.executable or sicstus.executable property to the correct name for your system. Once this is done, you can build the plugin by opening a command prompt or shell, going to the SUPPLE directory and runing:
../../bin/ant swi
|
(on Windows, use ..\..\bin\ant). For PrologCafe or SICStus, replace swi with plcafe or sicstus as appropriate.
9.12.3 Running the parser in GATE
In order to parse a document you will need to construct an application that has:
- tokeniser
- splitter
- POS-tagger
- Morphology
- SUPPLE Parser with parameters
mapping file (config/mapping.config)
feature table file (config/feature_table.config)
parser file (supple.plcafe or supple.sicstus or supple.swi)
prolog implementation (shef.nlp.supple.prolog.PrologCafe, shef.nlp.supple.prolog.SICStusProlog3, shef.nlp.supple.prolog.SICStusProlog4, shef.nlp.supple.prolog.SWIProlog or shef.nlp.supple.prolog.SWIJavaProlog1).
You can take a look at build.xml to see examples of invocation for the different implementations.
Note that prior to GATE 3.1, the parser file parameter was of type java.io.File. From 3.1 it is of type java.net.URL. If you have a saved application (.gapp file) from before GATE 3.1 which includes SUPPLE it will need to be updated to work with the new version. Instructions on how to do this can be found in the README file in the SUPPLE plugin directory.
9.12.4 Viewing the parse tree [#]
GATE provides a syntax tree viewer in the Tools plugin which can display the parse tree generated by SUPPLE for a sentence. To use the tree viewer, be sure that the Tools plugin is loaded, then open a document that has been processed with SUPPLE and view its Sentence annotations. Right-click on the relevant Sentence annotation in the annotations table and select “Edit with syntax tree viewer”. This viewer can also be used with the constituency output of the Stanford Parser PR (section 9.13).
9.12.5 System properties [#]
The SICStusProlog (3 and 4) and SWIProlog implementations work by calling the native prolog executable, passing data back and forth in temporary files. The location of the prolog executable is specified by a system property:
- for SICStus: supple.sicstus.executable - default is to look for sicstus.exe (Windows) or sicstus (other platforms) on the PATH.
- for SWI: supple.swi.executable - default is to look for plcon.exe (Windows) or swipl (other platforms) on the PATH.
If your prolog is installed under a different name, you should specify the correct name in the relevant system property. For example, when installed from the source distribution, the Unix version of SWI prolog is typically installed as pl, most binary packages install it as swipl, though some use the name swi-prolog. You can also use the properties to specify the full path to prolog (e.g. /opt/swi-prolog/bin/pl) if it is not on your default PATH.
For details of how to pass system properties to the GATE GUI, see the end of section 3.3.
9.12.6 Configuration files [#]
Two files are used to pass information from GATE to the SUPPLE parser: the mapping file and
the feature table file.
Mapping file
The mapping file specifies how annotations produced using Gate are to be passed to the parser. The file is composed of a number of pairs of lines, the first line in a pair specifies a Gate annotation we want to pass to the parser. It includes the AnnotationSet (or default), the AnnotationType, and a number of features and values that depend on the AnnotationType. The second line of the pair specifies how to encode the Gate annotation in a SUPPLE syntactic category, this line also includes a number of features and values. As an example consider the mapping:
Gate;AnnotationType=Token;category=DT;string=&S
SUPPLE;category=dt;m_root=&S;s_form=&S |
It specifies how a determinant (’DT’) will be translated into a category ’dt’ for the parser. The construct ’&S’ is used to represent a variable that will be instantiated to the appropriate value during the mapping process. More specifically a token like ’The’ recognised as a DT by the POS-tagging will be mapped into the following category:
dt(s_form:’The’,m_root:’The’,m_affix:’_’,text:’_’).
|
As another example consider the mapping:
Gate;AnnotationType=Lookup;majorType=person_first;minorType=female;string=&S
SUPPLE;category=list_np;s_form=&S;ne_tag=person;ne_type=person_first;gender=female |
It specified that an annotation of type ’Lookup’ in Gate is mapped into a category ’list_np’ with specific features and values. More specifically a token like ’Mary’ identified in Gate as a Lookup will be mapped into the following SUPPLE category:
list_np(s_form:’Mary’,m_root:’_’,m_affix:’_’,
text:’_’,ne_tag:’person’,ne_type:’person_first’,gender:’female’). |
Feature table [#]
The feature table file specifies SUPPLE ’lexical’ categories and its features. As an example an entry in this file is:
n;s_form;m_root;m_affix;text;person;number
|
which specifies which features and in which order a noun category should be writen. In this case:
n(s_form:...,m_root:...,m_affix:...,text:...,person:...,number:....).
|
9.12.7 Parser and Grammar [#]
The parser builds a semantic representation compositionally, and a ‘best parse’ algorithm is applied to each final chart, providing a partial parse if no complete sentence span can be constructed. The parser uses a feature valued grammar. Each Category entry has the form:
Category(Feature1:Value1,...,FeatureN:ValueN)
|
where the number and type of features is dependent on the category type (see Section 6.1). All categories will have the features s_form (surface form) and m_root (morphological root); nominal and verbal categories will also have person and number features; verbal categories will also have tense and vform features; and adjectival categories will have a degree feature. The list_np category has the same features as other nominal categories plus ne_tag and ne_type.
Syntactic rules are specifed in Prolog with the predicate rule(LHS,RHS) where LHS is a syntactic category and RHS is a list of syntactic categories. A rule such as BNP_HEAD ⇒ N (“a basic noun phrase head is composed of a noun”) is writen as follows:
rule(bnp_head(sem:E^[[R,E],[number,E,N]],number:N),
[n(m_root:R,number:N)]). |
where the feature ’sem’ is used to construct the semantics while the parser processes input, and E, R, and N are variables tobe instantiated during parsing.
The full grammar of this distribution can be found in the prolog/grammar directory, the file load.pl specifies which grammars are used by the parser. The grammars are compiled when the system is built and the compied version is used for parsing.
9.12.8 Mapping Named Entities
SUPPLE has a prolog grammar which deals with named entities, the only information required is the Lookup annotations produced by Gate, which are specified in the mapping file. However, you may want to pass named entities identified with your own Jape grammars in Gate. This can be done using a special syntactic category provided with this distribution. The category sem_cat is used as a bridge between Gate named entities and the SUPPLE grammar. An example of how to use it (provided in the mapping file) is:
Gate;AnnotationType=Date;string=&S
SUPPLE;category=sem_cat;type=Date;text=&S;kind=date;name=&S |
which maps a named entity ’Date’ into a syntactic category ’sem_cat’. A grammar file called semantic_rules.pl is provided to map sem_cat into the appropriate syntactic category expected by the phrasal rules. The following rule for example:
rule(ne_np(s_form:F,sem:X^[[name,X,NAME],[KIND,X]]),[
sem_cat(s_form:F,text:TEXT,type:’Date’,kind:KIND,name:NAME)]). |
is used to parse a ’Date’ into a named entity in SUPPLE which in turn will be parsed into a noun phrase.
9.12.9 Upgrading from BuChart to SUPPLE
In theory upgrading from BuChart to SUPPLE should be relatively straightforward. Basically any instance of BuChart needs to be replaced by SUPPLE. Specific changes which must be made are:
- The compiled parser files are now supple.swi, supple.sicstus, or supple.plcafe
- The GATE wrapper parameter buchartFile is now SUPPLEFile, and it is now of type java.net.URL rather than java.io.File. Details of how to compensate for this in existing saved applications are given in the SUPPLE README file.
- The Prolog wrappers now start shef.nlp.supple.prolog instead of shef.nlp.buchart.prolog
- The mapping.conf file now has lines starting SUPPLE; instead of Buchart;
- Most importantly the main wrapper class is now called nlp.shef.supple.SUPPLE
Making these changes to existing code should be trivial and allow application to benefit from future improvements to SUPPLE.
9.13 Stanford Parser [#]
The Stanford Parser is a probabilistic parsing system implemented in Java by Stanford University’s Natural Language Processing Group. Data files are available from Stanford for parsing Arabic, Chinese, English, and German.
This plugin, developed by the GATE team, provides a PR (gate.stanford.Parser) that acts as a wrapper around the Stanford Parser (version 1.6) and translates GATE annotations to and from the data structures of the parser itself. The plugin is supplied with the unmodified jar file and one English data file obtained from Stanford. Stanford’s software itself is subject to the full GPL.
The parser itself can be trained on other corpora and languages, as documented on the website, but this plugin does not provide a means of doing so. (Trained data files are not compatible between different versions of the parser.)
Creating multiple instances of this PR in the same JVM with different trained data files does not work—the PRs can be instantiated, but runtime errors will almost certainly occur.
9.13.1 Input requirements
Documents to be processed by the Parser PR must already have Sentence and Token annotations, such as those produced by either ANNIE Sentence Splitter (sections 8.3 and 8.4) and the ANNIE English Tokeniser (section 8.1).
If the reusePosTags parameter is true, then the Token annotations must have category features with compatible POS tags. The tags produced by the ANNIE POS Tagger are compatible with Stanford’s parser data files for English (which also use the Penn treebank tagset).
9.13.2 Initialization parameters
- parserFile
- the path to the trained data file; the default value points to the English data file2 included with the GATE distribution. You can also use other files downloaded from the Stanford Parser website or produced by training the parser.
- mappingFile
- the optional path to a mapping file: a flat, two-column file which the wrapper can use to “translate” tags. A sample file is included.3 By default this value is null and mapping is ignored.
- tlppClass
- an implementation of TreebankLangParserParams, used by the parser itself to extract the dependency relations from the constituency structures. The default value is compatible with the English data file supplied. Please refer to the Stanford NLP Group’s documentation and the parser’s javadoc for a further explanation.
9.13.3 Runtime parameters
- annotationSetName
- the name of the annotationSet used for input (Token and Sentence annotations) and output (SyntaxTreeNode and Dependency annotations, and category and dependencies features added to Tokens).
- debug
- a boolean value which controls the verbosity of the wrapper’s output.
- reusePosTags
- if true, the wrapper will read category features (produced by an earlier POS-tagging PR) from the Token annotations and force the parser to use them.
- useMapping
- if this is true and a mapping file was loaded when the PR was initialized, the POS and syntactic tags produced by the parser will be translated using that file. If no mapping file was loaded, this parameter is ignored.
The following boolean parameters switch on and off the various types of output that the parser can produce. Any or all of them can be true, but if all are false the PR will simply print a warning to save time (instead of running the parser).
- addPosTags
- if this is true, the wrapper will add category features to the Token annotations.
- addConstituentAnnotations
- if true, the wrapper will mark the syntactic constituents with SyntaxTreeNode annotations that are compatible with the Syntax Tree Viewer (see section 9.12.4).
- addDependencyAnnotations
- if true, the wrapper will add Dependency annotations to indicate the dependency relations in the sentence.
- addDependencyFeatures
- if true, the wrapper will add dependencies features to the Token annotations to indicate the dependency relations in the sentence.
The parser will derive the dependency structures only if either or both of the dependency output options is enabled, so if you do not need the dependency analysis, you can disable both of them and the PR will run faster.
Two sample GATE applications for English are included in the plugins/Stanford directory: sample_parser_en.gapp runs the Regex Sentence Splitter and ANNIE Tokenizer and then this PR to annotate constituency and dependency structures, whereas sample_pos+parser_en.gapp also runs the ANNIE POS Tagger and makes the parser re-use its POS tags.
9.14 Montreal Transducer [#]
Many of the key features introduced in the Montreal Transducer (MT) have now been ported in some form into the standard JAPE transducer. If you are considering using the MT, you should first check the documentation for the standard transducer in chapter 7 to see if that is suitable for your needs. Being such a core part of GATE, the standard JAPE transducer is likely to be more stable and bugs will be fixed more rapidly than with the MT.
The Montreal Transducer is an improved Jape Transducer, developed by Luc Plamondon, Université de Montréal. It is intended to make grammar authoring easier by providing a more flexible version of the JAPE language and it also fixes a few bugs. Full details of the transducer can be found at http://www.iro.umontreal.ca/ plamondl/mtltransducer/. We summarise the main features below.
9.14.1 Main Improvements
- While only == constraints were allowed on annotation attributes, the grammar now accepts constraints such as {MyAnnot.attrib != value}, {MyAnnot.attrib > value}, {MyAnnot.attrib < value}, {MyAnnot.attrib = value} and {MyAnnot.attrib ! value} (a similar feature has now been incorporated in the standard JAPE transducer, see section 7.1)
- The grammar now accepts negated constraints such as {!MyAnnot} (true if no annotation starting from current node has the MyAnnot type) and {!MyAnnot.attrib == value} (true if {MyAnnot.attrib == value} fails), where the == constraint can be any other operator (this feature has now been incorporated into the standard transducer, see section 7.4)
- Because the transducer compiles rules at run-time, the classpath must include the transducer jar file (unless the transducer is bundled in the GATE jar file). The Montreal Transducer updates the classpath automatically when it is initialised.
9.14.2 Main Bug fixes
- Constraints on more than one annotation types for a same node now work. For example, {MyAnnot1, MyAnnot2} was allowed by the Jape Transducer but not implemented yet (this is also supported by the standard transducer)
- The * and + Kleene operators were not greedy when they occurred inside a rule (the standard transducer still behaves this way). The document region parsed by a rule is correct but ambiguous labels inside the rule were not resolved the expected way. In the following rule for example, a node that would match both constraints should be part of the ”:titles” label and not ”:names” because the first + is expected to be greedy:
({Lookup.majorType == title})+:titles ({Token.orth == upperInitial})*:names
|
9.15 Language Plugins [#]
There are plugins available for processing the following languages: French, German, Spanish, Italian, Chinese, Arabic, Romanian, Hindi and Cebuano. Some of the applications are quite basic and just contain some useful processing resources to get you started when developing a full application. Others (Cebuano and Hindi) are more like toy systems built as part of an exercise in language portability.
Note that if you wish to use individual language processing resources without loading the whole application, you will need to load the relevant plugin for that language in most cases. The plugins all follow the same kind of format. Load the plugin using the plugin manager, and the relevant resources will be available in the Processing Resources set.
Some plugins just contain a list of resources which can be added ad hoc to other applications. For example, the Italian plugin simply contains a lexicon which can be used to replace the English lexicon in the default English POS tagger: this will provide a reasonable basic POS tagger for Italian.
In most cases you will also find a directory in the relevant plugin directory called data which contains some sample texts (in some cases, these are annotated with NEs).
9.15.1 French Plugin [#]
The French plugin contains two applications for NE recognition: one which includes the TreeTagger for POS tagging in French (french+tagger.gapp) , and one which does not (french.gapp). Simply load the application required from the plugins/french directory. You do not need to load the plugin itself from the plugins menu. Note that the TreeTagger must first be installed and set up correctly (see Section 9.7 for details). Check that the runtime parameters are set correctly for your TreeTagger in your application. The applications both contain resources for tokenisation, sentence splitting, gazetteer lookup, NE recognition (via JAPE grammars) and orthographic coreference. Note that they are not intended to produce high quality results, they are simply a starting point for a developer working on French. Some sample texts are contained in the plugins/french/data directory.
9.15.2 German Plugin [#]
The German plugin contains two applications for NE recognition: one which includes the TreeTagger for POS tagging in German (german+tagger.gapp) , and one which does not (german.gapp). Simply load the application required from the plugins/german/resources directory. You do not need to load the plugin itself from the plugins menu. Note that the TreeTagger must first be installed and set up correctly (see Section 9.7 for details). Check that the runtime parameters are set correctly for your TreeTagger in your application. The applications both contain resources for tokenisation, sentence splitting, gazetteer lookup, compound analysis, NE recognition (via JAPE grammars) and orthographic coreference. Some sample texts are contained in the plugins/german/data directory. We are grateful to Fabio Ciravegna and the Dot.KOM project for use of some of the components for the German plugin.
9.15.3 Romanian Plugin [#]
The Romanian plugin contains an application for Romanian NE recognition (romanian.gapp). Simply load the application from the plugins/romanian/resources directory. You do not need to load the plugin itself from the plugins menu. The application contains resources for tokenisation, gazetteer lookup, NE recognition (via JAPE grammars) and orthographic coreference. Some sample texts are contained in the plugins/romanian/corpus directory.
9.15.4 Arabic Plugin [#]
The Arabic plugin contains a simple application for Arabic NE recognition (arabic.gapp). Simply load the application from the plugins/arabic/resources directory. You do not need to load the plugin itself from the plugins menu. The application contains resources for tokenisation, gazetteer lookup, NE recognition (via JAPE grammars) and orthographic coreference. Note that there are two types of gazetteer used in this application: one which was derived automatically from training data (Arabic inferred gazetteer), and one which was created manually. Note that there are some other applications included which perform quite specific tasks (but can generally be ignored). For example, arabic-for-bbn.gapp and arabic-for-muse.gapp make use of a very specific set of training data and convert the result to a special format. There is also an application to collect new gazetteer lists from training data (arabic_lists_collector.gapp). For details of the gazetteer list collector please see Section 9.6.
9.15.5 Chinese Plugin [#]
The Chinese plugin contains a simple application for Chinese NE recognition (chinese.gapp). Simply load the application from the plugins/chinese/resources directory. You do not need to load the plugin itself from the plugins menu. The application contains resources for tokenisation, gazetteer lookup, NE recognition (via JAPE grammars) and orthographic coreference. The application makes use of some gazetteer lists (and a grammar to process them) derived automatically from training data, as well as regular hand-crafted gazetteer lists. There are also applications (listscollector.gapp, adj_collector.gapp and nounperson_collector.gapp) to create such lists, and various other application to perform special tasks such as coreference evaluation (coreference_eval.gapp) and converting the output to a different format (ace-to-muse.gapp).
9.16 Chemistry Tagger [#]
This GATE module is designed to tag a number of chemistry items in running text. Currently the tagger tags compound formulas (e.g. SO2, H2O, H2SO4 ...) ions (e.g. Fe3+, Cl-) and element names and symbols (e.g. Sodium and Na). Limited support for compound names is also provided (e.g. sulphur dioxide) but only when followed by a compound formula (in parenthesis or commas).
9.16.1 Using the tagger
The Tagger requires the Creole plugin ”Chemistry_Tagger” to be loaded. It requires the following PRs to have been run first: tokeniser and sentence splitter. There are four init parameters giving the locations of the two gazetteer list definitions, the element mapping file and the JAPE grammar used by the tagger (in previous versions of the tagger these files were fixed and loaded from inside the ChemTagger.jar file). Unless you know what you are doing you should accept the default values.
The annotations added to documents are ”ChemicalCompound”, ”ChemicalIon” and ”ChemicalElement” (currently they are always placed in the default annotation set).
9.17 Flexible Exporter [#]
The Flexible Exporter enables the user to save a document (or corpus) in its original format with added annotations. The user can select the name of the annotation set from which these annotations are to be found, which annotations from this set are to be included, whether features are to be included, and various renaming options such as renaming the annotations and the file.
At load time, the following parameters can be set for the flexible exporter:
- includeFeatures - if set to true, features are included with the annotations exported; if false (the default status), they are not.
- useSuffixForDumpFiles - if set to true (the default status), the output files have the suffix defined in suffixForDumpFiles; if false, no suffix is defined, and the output file simply overwrites the existing file (but see the outputFileUrl runtime parameter for an alternative).
- suffixForDumpFiles - this defines the suffix if useSuffixForDumpFiles is set to true. By default the suffix is .gate.
The following runtime parameters can also be set (after the file has been selected for the application):
- annotationSetName - this enables the user to specify the name of the annotation set which contains the annotations to be exported. If no annotation set is defined, it will use the Default annotation set.
- annotationTypes - this contains a list of the annotations to be exported. By default it is set to Person, Location and Date.
- dumpTypes - this contains a list of names for the exported annotations. If the annotation name is to remain the same, this list should be identical to the list in annotationTypes. The list of annotation names must be in the same order as the corresponding annotation types in annotationTypes.
- outputDirectoryUrl - this enables the user to specify the export directory where the file is exported with its original name and an extension (provided as a parameter) appended at the end of filename. Note that you can also save a whole corpus in one go.
9.18 Annotation Set Transfer [#]
The Annotation Set Transfer allows copying or moving annotations to a new annotation set if they lie between the beginning and the end of an annotation of a particular type (the covering annotation). For example, this can be used when a user only wants to run a processing resource over a specific part of a document, such as the Body of an HTML document. The user specifies the name of the annotation set and the annotation which covers the part of the document they wish to transfer, and the name of the new annotation set. All the other annotations corresponding to the matched text will be transferred to the new annotation set. For example, we might wish to perform named entity recognition on the body of an HTML text, but not on the headers. After tokenising and performing gazetteer lookup on the whole text, we would use the Annotation Set Transfer to transfer those annotations (created by the tokeniser and gazetteer) into a new annotation set, and then run the remaining NE resources, such as the semantic tagger and coreference modules, on them.
The Annotation Set Transfer has no loadtime parameters. It has the following runtime parameters:
- inputASName - this defines the annotation set from which annotations will be transferred (copied or moved). If nothing is specified, the Default annotation set will be used.
- outputASName - this defines the annotation set to which the annotations will be transferred. This default value for this parameter is ”Filtered”. If it is left blank the Default annotation set will be used.
- tagASName - this defines the annotation set which contains the annotation covering the relevant part of the document to be transferred. This default value for this parameter is ”Original markups”. If it is left blank the Default annotation set will be used.
- textTagName - this defines the type of the annotation covering the annotations to be transferred. The default value for this parameter is ”BODY”. If this is left blank, then all annotations from the inputASName annotation set will be transferred. If more than one covering annotation is found, the annotation covered by each of them will be transferrred. If no covering annotation is found, the processing depends on the copyAllUnlessFound parameter (see below).
- copyAnnotations - this specifies whether the annotations should be moved or copied. The default value false will move annotations, removing them from the inputASName annotation set. If set to true the annotations will be copied.
- transferAllUnlessFound - this specifies what should happen if no covering annotation is found. The default value is true. In this case, all annotations will be copied or moved (depending on the setting of parameter copyAnnotations) if no covering annotation is found. If set to false, no annotation will be copied or moved.
For example, suppose we wish to perform named entity recognition on only the text covered by the BODY annotation from the Original Markups annotation set in an HTML document. We have to run the gazetteer and tokeniser on the entire document, because since these resources do not depend on any other annotations, we cannot specify an input annotation set for them to use. We therefore transfer these annotations to a new annotation set (Filtered) and then perform the NE recognition over these annotations, by specifying this annotation set as the input annotation set for all the following resources. In this example, we would set the following parameters (assuming that the annotations from the tokenise and gazetteer are initially placed in the Default annotation set).
- inputASName: Default
- outputASName: Filtered
- tagASName: Original markups
- textTagName: BODY
- copyAnnotations: true or false (depending on whether we want to keep the Token and Lookup annotations in the Default annotation set)
- copyAllUnlessFound: true
9.19 Information Retrieval in GATE [#]
GATE comes with a full-featured Information Retrieval (IR) subsystem that allows queries to be performed against GATE corpora. This combination of IE and IR means that documents can be retrieved from the corpora not only based on their textual content but also according to their features or annotations. For example, a search over the Person annotations for ”Bush” will return documents with higher relevance, compared to a search in the content for the string ”bush”. The current implementation is based on the most popular open source full-text search engine - Lucene (available at http://jakarta.apache.org/lucene/) but other implementations may be added in the future.
An Information Retrieval system is most often considered a system that accepts as input a set of documents (corpus) and a query (combination of search terms) and returns as input only those documents from the corpus which are considered as relevant according to the query. Usually, in addition to the documents, a proper relevance measure (score) is returned for each document. There exist many relevance metrics, but usually documents which are considered more relevant, according to the query, are scored higher.
Figure 9.4 shows the results from running a query against an indexed corpus in GATE.
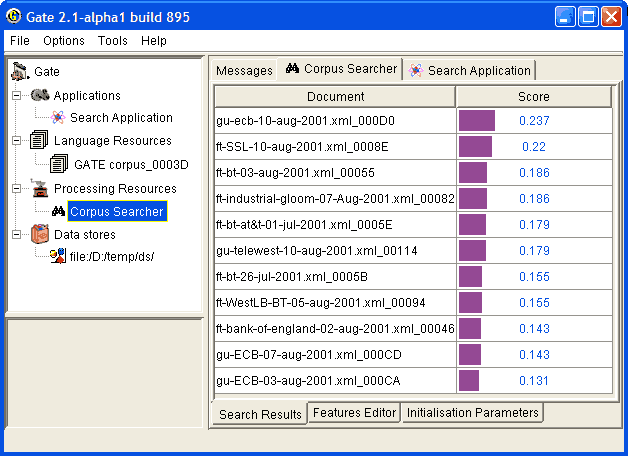
Information Retrieval systems usually perform some preprocessing one the input corpus in order to create the document-term matrix for the corpus. A document-term matrix is usually presented as:
|
|
where doci is a document from the corpus, termj is a word that is considered as important and representative for the document and wi,j is the weight assigned to the term in the document. There are many ways to define the term weight functions, but most often it depends on the term frequency in the document and in the whole corpus (i.e. the local and the global frequency). Note that the machine learning plugin described in Chapter 11 can produce such document-term matrix (for detailed description of the matrix produced see Section 11.5.4).
Note that not all of the words appearing in the document are considered terms. There are many words (called ”stop-words”) which are ignored, since they are observed too often and are not representative enough. Such words are articles, conjunctions, etc. During the preprocessing phase which identifies such words, usually a form of stemming is performed in order to minimize the number of terms and to improve the retrieval recall. Various forms of the same word (e.g. ”play”, ”playing” and ”played”) are considered identical and multiple occurrences of the same term (probably ”play”) will be observed.
It is recommended that the user reads the relevant Information Retrieval literature for a detailed explanation of stop words, stemming and term weighting.
IR systems, in a way similar to IE systems, are evaluated with the help of the precision and recall measures (see Section 13.4 for more details).
9.19.1 Using the IR functionality in GATE
In order to run queries against a corpus, the latter should be ”indexed”. The indexing process first processes the documents in order to identify the terms and their weights (stemming is performed too) and then creates the proper structures on the local filesystem. These file structures contain indexes that will be used by Lucene (the underlying IR engine) for the retrieval.
Once the corpus is indexed, queries may be run against it. Subsequently the index may be removed and then the structures on the local filesytem are removed too. Once the index is removed, queries cannot be run against the corpus.
Indexing the corpus
In order to index a corpus, the latter should be stored in a serial datastore. In other words, the IR functionality is unavailable for corpora that are transient or stored in a RDBMS datastores (though support for the lattr may be added in the future).
To index the corpus, follow these steps:
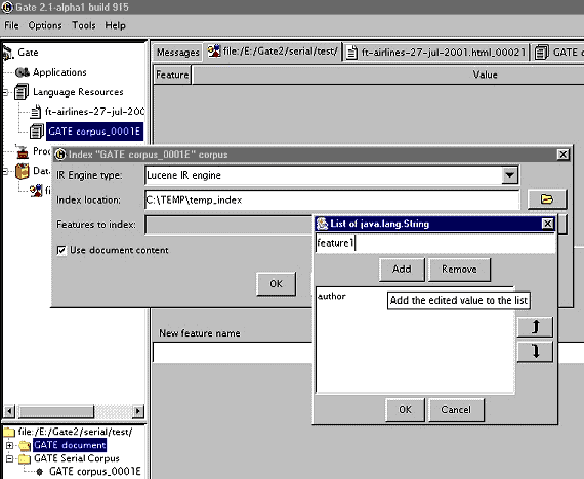
- Select the corpus from the resource tree (top-left pane) and from the context menu (right button click) choose ”Index Corpus”. A dialogue appears that allows you to specify the index properties.
- In the index properties dialogue, specify the underlying IR system to be used (only Lucene is supported at present), the directory that will contain the index structures, and the set of properties that will be indexed such as document features, content, etc (the same properties will be indexed for each document in the corpus).
- Once the corpus in indexed, you may start running queries against it. Note that the directory specified for the index data should exist and be empty. Otherwise an error will occur during the index creation.
Querying the corpus
To query the corpus, follow these steps:
- Create a SearchPR processing resource. All the parameters of SearchPR are runtime so theyare set later.
- Create a pipeline application containing the SearchPR.
- Set the following SearchPR parameters:
- The corpus that will be queried.
- The query that will be executed.
- The maximum number of documents returned.
A query looks like the following:
{+/-}field1:term1 {+/-}field2:term2 ? {+/-}fieldN:termNwhere field is the name of a index field, such as the one specified at index creation (the document content field is body) and term is a term that should appear in the field.
For example the query:
+body:government +author:CNNwill inspect the document content for the term ”government” (together with variations such as ”governments” etc.) and the index field named ”author” for the term ”CNN”. The ”author” field is specified at index creation time, and is either a document feature or another document property.
- After the SearchPR is initialized, running the application executes the specified query over the specified corpus.
- Finally, the results are displayed (see fig.1) after a double-click on the SearchPR processing resource.
Removing the index
An index for a corpus may be removed at any time from the ”Remove Index” option of the context menu for the indexed corpus (right button click).
9.19.2 Using the IR API
The IR API within GATE makes it possible for corpora to be indexed, queried and results returned from any Java application, without using the GATE GUI. The following sample indexes a corpus, runs a query against it and then removes the index.
// open a serial data store SerialDataStore sds = Factory.openDataStore("gate.persist.SerialDataStore", "/tmp/datastore1"); sds.open(); //set an AUTHOR feature for the test document Document doc0 = Factory.newDocument(new URL("/tmp/documents/doc0.html")); doc0.getFeatures().put("author","John Smit"); Corpus corp0 = Factory.newCorpus("TestCorpus"); corp0.add(doc0); //store the corpus in the serial datastore Corpus serialCorpus = (Corpus) sds.adopt(corp0,null); sds.sync(serialCorpus); //index the corpus - the content and the AUTHOR feature IndexedCorpus indexedCorpus = (IndexedCorpus) serialCorpus; DefaultIndexDefinition did = new DefaultIndexDefinition(); did.setIrEngineClassName(gate.creole.ir.lucene. LuceneIREngine.class.getName()); did.setIndexLocation("/tmp/index1"); did.addIndexField(new IndexField("content", new DocumentContentReader(), false)); did.addIndexField(new IndexField("author", null, false)); indexedCorpus.setIndexDefinition(did); indexedCorpus.getIndexManager().createIndex(); //the corpus is now indexed //search the corpus Search search = new LuceneSearch(); search.setCorpus(ic); QueryResultList res = search.search("+content:government +author:John"); //get the results Iterator it = res.getQueryResults(); while (it.hasNext()) { QueryResult qr = (QueryResult) it.next(); System.out.println("DOCUMENT_ID="+ qr.getDocumentID() +", scrore="+qr.getScore()); } |
9.20 Crawler [#]
The crawler plugin enables GATE to be used for a corpus that is built using a web crawl. The crawler itself is Websphinx.This is a JAVA based multi-threaded web crawler that can be customized for any application. In order to use this plugin it may be required that the websphinx.jar file be added in the required libraries in JBuilder.
The basic idea is to be able to specify a source URL and a depth to build the initial corpus upon which further processing could be done. The PR itself provides a number of helpful features to set various parameters of the crawl.
9.20.1 Using the Crawler PR
In order to use the processing resource you first need to load the plugin using the plugin manager. Then load the crawler from the list of processing resources. Once the crawler is initialized, the PR automatically creates a corpus named crawl where all the documents from the web crawl will be stored. In order to use the crawler, create a simple pipeline (note: do not create a corpus pipeline) and add the crawl PR to the pipeline.
Once the crawl PR is created there will be a number of parameters that can be set based on the PR required (see also Figure 9.6).
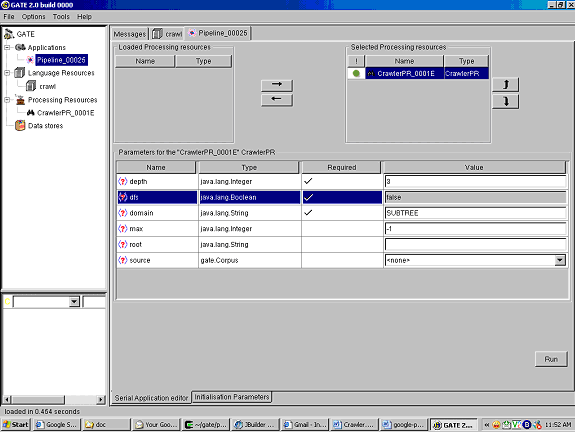
- depth: the depth to which the crawl should proceed.
- dfs / bfs: dfs if true bfs if false
- Dfs : the crawler uses the depth first strategy for the crawl.
- Visits the nodes in dfs order until the specified depth limit is reached.
- Bfs: the crawler used the breadth first strategy for the crawl.
- Visits the nodes on bfs order until the specified depth limit is reached.
- Dfs : the crawler uses the depth first strategy for the crawl.
- domain
- SUBTREE: Crawler visits only the descendents of the page specified as the root for the crawl.
- WEB: Crawler visits all the pages on the web.
- SERVER: Crawler visits only the pages that are present on the server where the root page is located.
- max number of pages to be fetched
- root the starting URL to be used for the crawl to begin
- source is the corpus to be used that contains the documents from which the crawl must begin. Source is useful when the documents are fetched first from the google PR and then need to be crawled to expand the web graph further. At any time either the source or the root needs to be set.
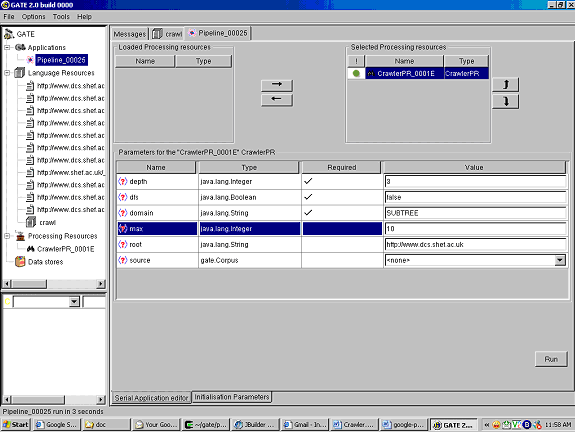
Once the parameters are set, the crawl can be run and the documents fetched are added to the corpus crawl. Figure 9.7 shows the crawled pages added to the corpus.
9.21 Google Plugin [#]
The Google API is now integrated with GATE, and can be used as a PR-based plugin. This plugin allows the user to query Google and build the document corpus that contains the search results returned by Google for the query. There is a limit of 1000 queries per day as set by Google. For more information about the Google API please refer to http://www.google.com/apis/. In order to use the Google PR, you need to register with Google to obtain a license key.
The Google PR can be used for a number of different application scenarios. For example, one use case is where a user wants to find out what are the different named entities that can be associated with a particular individual. In this example, the user could build the collection of documents by querying Google and then running ANNIE over the collection. This would annotate the results and show what are the different Organization, Location and other entities that can be associated with the query.
9.21.1 Using the GooglePR
In order to use the PR, you first need to load the plugin using the plugin manager. Once the PR is loaded, it can be initialized by creating an instance of a new PR. Here you need to specify the Google API License key. Please use the license key assigned to you by registering with Google.
Once the Google PR is initialized, it can be placed in a pipeline or a conditional pipeline application. This pipeline would contain the instance of the Google PR just initialized as above. There are a number of parameters to be set at runtime:
- corpus: The corpus used by the plugin to add or append documents from the Web.
- corpusAppendMode: If set to true, will append documents to the corpus. If set to false, will remove preexisting documents from the corpus, before adding the documents newly fetched by the PR
- limit: A limit on the results returned by the search. Default set to 10.
- pagesToExclude: This is an optional parameter. It is a list with URLs not to be included in the search.
- query: The query sent to Google. It is in the format accepted by Google.
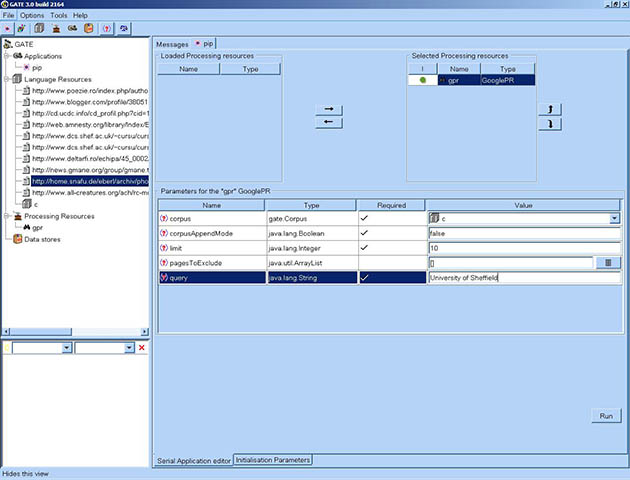
Once the required parameters are set we can run the pipeline. This will then download all the URLs in the results and create a document for each. These documents would be added to the corpus as shown in Figure 9.8.
9.22 Yahoo Plugin [#]
The Yahoo API is now integrated with GATE, and can be used as a PR-based plugin. This plugin allows the user to query Yahoo and build the document corpus that contains the search results returned by Yahoo for the query. For more information about the Yahoo API please refer to http://developer.yahoo.com/search/. In order to use the Yahoo PR, you need to obtain an application ID.
The Yahoo PR can be used for a number of different application scenarios. For example, one use case is where a user wants to find out what are the different named entities that can be associated with a particular individual. In this example, the user could build the collection of documents by querying Yahoo and then running ANNIE over the collection. This would annotate the results and show what are the different Organization, Location and other entities that can be associated with the query.
9.22.1 Using the YahooPR
In order to use the PR, you first need to load the plugin using the plugin manager. Once the PR is loaded, it can be initialized by creating an instance of a new PR. Here you need to specify the Yahoo Application ID. Please use the license key assigned to you by registering with Yahoo.
Once the Yahoo PR is initialized, it can be placed in a pipeline or a conditional pipeline application. This pipeline would contain the instance of the Yahoo PR just initialized as above. There are a number of parameters to be set at runtime:
- corpus: The corpus used by the plugin to add or append documents from the Web.
- corpusAppendMode: If set to true, will append documents to the corpus. If set to false, will remove preexisting documents from the corpus, before adding the documents newly fetched by the PR
- limit: A limit on the results returned by the search. Default set to 10.
- pagesToExclude: This is an optional parameter. It is a list with URLs not to be included in the search.
- query: The query sent to Yahoo. It is in the format accepted by Yahoo.
Once the required parameters are set we can run the pipeline. This will then download all the URLs in the results and create a document for each. These documents would be added to the corpus.
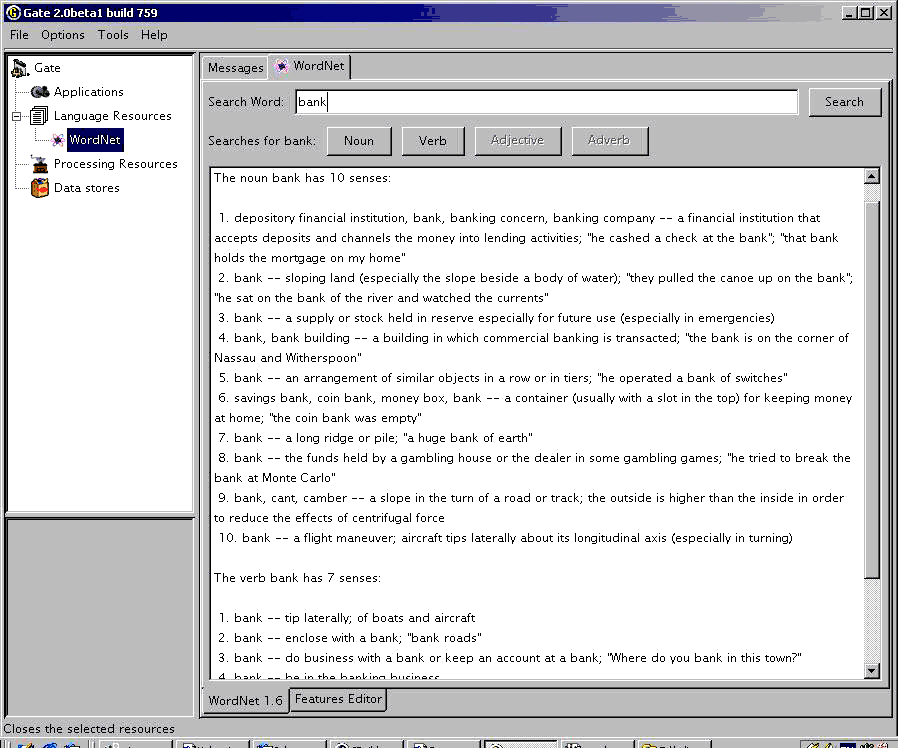
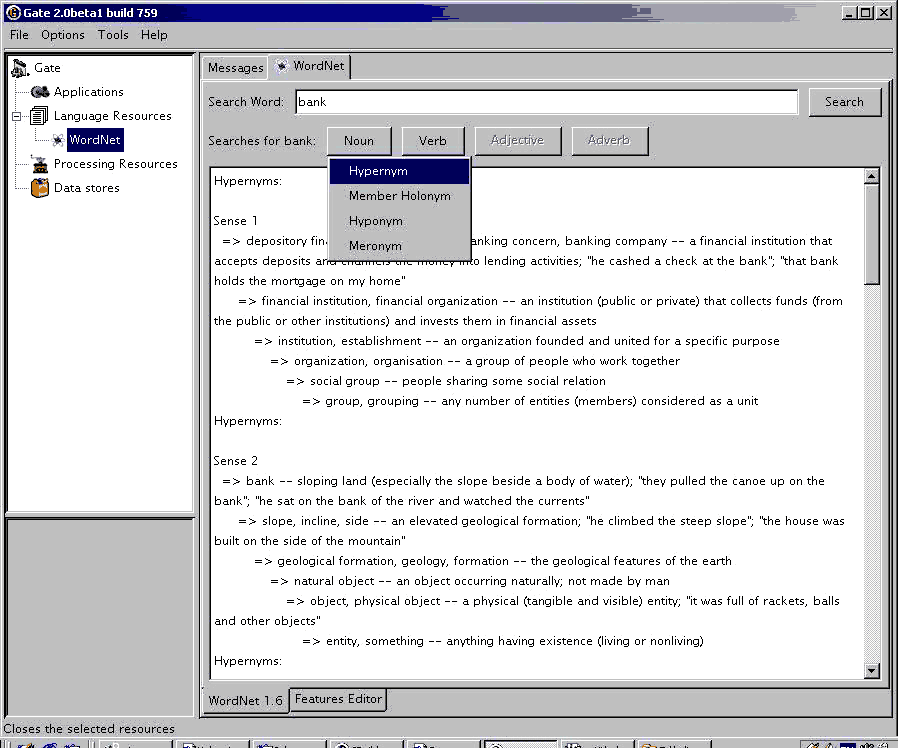
9.23 WordNet in GATE [#]
At present GATE supports only WordNet 1.6, so in order to use WordNet in GATE, you must first install WordNet 1.6 on your computer. WordNet is available at http://wordnet.princeton.edu/. The next step is to configure GATE to work with your local WordNet installation. Since GATE relies on the Java WordNet Library (JWNL) for WordNet access, this step consists of providing one special xml file that is used internally by JWNL. This file describes the location of your local copy of the WordNet 1.6 index files. An example of this wn-config.xml file is shown below:
<?xml version="1.0" encoding="UTF-8"?> <jwnl_properties language="en"> <version publisher="Princeton" number="1.6" language="en"/> <dictionary class="net.didion.jwnl.dictionary.FileBackedDictionary"> <param name="morphological_processor" value="net.didion.jwnl.dictionary.DefaultMorphologicalProcessor"/> <param name="file_manager" value="net.didion.jwnl.dictionary.file_manager.FileManagerImpl"> <param name="file_type" value="net.didion.jwnl.princeton.file.PrincetonRandomAccessDictionaryFile"/> <param name="dictionary_path" value="e:\wn16\dict"/> </param> </dictionary> <dictionary_element_factory class="net.didion.jwnl.princeton.data.PrincetonWN16DictionaryElementFactory"/> <resource class="PrincetonResource"/> </jwnl_properties> |
All you have to do is to replace the value of the dictionary_path parameter to point to your local installation of WordNet 1.6.
After configuring GATE to use WordNet, you can start using the built-in WordNet browser or API. In GATE, load the WordNet plugin via the plugins menu. Then load WordNet by selecting it from the set of available language resources. Set the value of the parameter to the path of the xml properties file which describes the WordNet location (wn-config).
Once Word Net is loaded in GATE, the well-known interface of WordNet will appear. You can search Word Net by typing a word in the box next to to the label “SearchWord”’ and then pressing “Search”. All the senses of the word will be displayed in the window below. Buttons for the possible parts of speech for this word will also be activated at this point. For instance, for the word “play”, the buttons “Noun”, “Verb” and “Adjective” are activated. Pressing one of these buttons will activate a menu with hyponyms, hypernyms, meronyms for nouns or verb groups, and cause for verbs, etc. Selecting an item from the menu will display the results in the window below.
More information about WordNet can be found at http://www.cogsci.princeton.edu/wn/index.shtml
More information about the JWNL library can be found at http://sourceforge.net/projects/jwordnet
An example of using the WordNet API in GATE is available on the GATE examples page at http://gate.ac.uk/GateExamples/doc/index.html
9.23.1 The WordNet API
GATE offers a set of classes that can be used to access the WordNet 1.6 Lexical Base. The implementation of the GATE API for WordNet is based on Java WordNet Library (JWNL). There are just a few basic classes, as shown in Figure 9.11. Details about the properties and methods of the interfaces/classes comprising the API can be obtained from the JavaDoc. Below is a brief overview of the interfaces:
- WordNet: the main WordNet class. Provides methods for getting the synsets of a lemma, for accessing the unique beginners, etc.
- Word: offers access to the word’s lemma and senses
- WordSense: gives access to the synset, the word, POS and lexical relations.
- Synset: gives acess to the word senses (synonyms) in the synset, the semantic relations, POS etc.
- Verb: gives access to the verb frames (not working properly at present)
- Adjective: gives access to the adj. position (attributive, predicative, etc.).
- Relation: abstract relation such as type, symbol, inverse relation, set of POS tags, etc. to which it is applicable.
- LexicalRelation
- SemanticRelation
- VerbFrame
9.24 Machine Learning in GATE [#]
Note: A brand new machine learning layer specifically targetted at NLP tasks including text classification, chunk learning (e.g. for named entity recognition) and relation learning has been added to GATE. See chapter 11 for more details.
9.24.1 ML Generalities
This section describes the use of Machine Learning (ML) algorithms in GATE.
An ML algorithm ”learns” about a phenomenon by looking at a set of occurrences of that phenomenon that are used as examples. Based on these, a model is built that can be used to predict characteristics of future (and unforeseen) examples of the phenomenon.
Classification is a particular example of machine learning in which the set of training examples is split into multiple subsets (classes) and the algorithm attempts to distribute the new examples into the existing classes.
This is the type of ML that is used in GATE and all further references to ML actually refer to classification.
Some definitions
- instance: an example of the studied phenomenon. An ML algorithm learns from a set of known instances, called a dataset.
- attribute: a characteristic of the instances. Each instance is defined by the values of its attributes. The set of possible attributes is well defined and is the same for all instances in a dataset.
- class: an attribute for which the values need to be found through the ML mechanism.
GATE-specific interpretation of the above definitions
- instance: an annotation. In order to use ML in GATE the users will need to choose the type of annotations used as instances. Token annotations are a good candidate for this, but any type of annotation could be used (e.g. things that were found by a previously run JAPE grammar).
- attribute: an attribute can be either:
- the presence (or absence) of a particular annotation type [partially] covering the instance annotation
- the value of a named feature of a particular annotation type.
The value of the attribute can refer to the current instance or to an instance situated at a specified location relative to the current instance.
- class: any attribute can be marked as class attribute.
An ML implementation has two modes of functioning: training and application. The training phase consists of building a model (e.g. statistical model, a decision tree, a rule set, etc.) from a dataset of already classified instances. During application, the model built while training is used to classify new instances.
There are ML algorithms which permit the incremental building of the model (e.g. the Updateable Classifiers in the WEKA library). These classifiers do not require the entire training dataset to build a model; the model improves with each new training instance that the algorithm is provided with.
9.24.2 The Machine Learning PR in GATE
Access to ML implementations is provided in GATE by the ”Machine Learning PR” that handles both the training and application of ML model on GATE documents. This PR is a Language Analyser so it can be used in all default types of GATE controllers.
In order to allow for more flexibility, all the configuration parameters for the ML PR are set through an external XML file and not through the normal PR parameterisation. The root element of the file needs to be called ”ML-CONFIG” and it contains two elements: ”DATASET” and ”ENGINE”. An example XML configuration file is given in Appendix E.
The DATASET element
The DATASET element defines the type of annotation to be used as instance and the set of attributes that characterise all the instances.
An ”INSTANCE-TYPE” element is used to select the annotation type to be used for instances, and the attributes are defined by a sequence of ”ATTRIBUTE” elements.
For example, if an ”INSTANCE-TYPE” has a ”Token” for value, there will one instance in the dataset per ”Token”. This also means that the positions (see below) are defined in relation to Tokens. The ”INSTANCE-TYPE” can be seen as the smallest unit to be taken into account for the Machine Learning.
An ATTRIBUTE element has the following sub-elements:
- NAME: the name of the attribute
- TYPE: the annotation type used to extract the attribute.
- FEATURE (optional): if present, the value of the attribute will be the value of the named feature on the annotation of specified type.
- POSITION: the position of the annotation used to extract the feature relative to the current instance annotation.
- VALUES(optional): includes a list of VALUE elements.
- <CLASS/>: an empty element used to mark the class attribute. There can only be one attribute marked as class in a dataset definition.
The VALUES being defined as XML entities, the characters <, > and & must be replaced by <, &rt; and &. It is recommended to write the XML configuration file in UTF-8 in order to have some uncommon character correctly parsed.
Semantically, there are three types of attributes:
- nominal attributes: both type and features are defined and a list of allowed values is provided;
- numeric: both type and features are defined but no list of allowed values is provided; it is assumed that the feature can be converted to a number (a double value).
- boolean: no feature or list of values is provided; the attribute will take one of the ”true” or ”false” values based on the presence (or absence) of the specified annotation type at the required position.
Figure 9.12 gives some examples of what the values of specified attributes would be in a situation when ”Token” annotations are used as instances.
An ATTRIBUTELIST element is similar to ATTRIBUTE except that it has no POSITION sub-element but a RANGE element. This will be converted into several ATTRIBUTELIST with position ranging from the value of the attribute ”from” to the value of the attribute ”to”. This can be used in order to avoid the duplication of ATTRIBUTE elements.
The ENGINE element
The ENGINE element defines which particular ML implementation will be used, and allows the setting of options for that particular implementation.
The ENGINE element has three sub-elements:
- WRAPPER: defines the class name for the ML implementation (or implementation wrapper). The specified class needs to extend gate.creole.ml.MLEngine.
- BATCH-MODE-CLASSIFICATION: this element is optional. If present (as an empty element <BATCH-MODE-CLASSIFICATION />), the training instances will be passed to the engine in a single batch. If absent, the instances are passed to the engine one at a time. Not every engine supports this option, but for those that do, it can greatly improve performance.
- OPTIONS: the contents of the OPTIONS element will be passed verbatim to the ML engine used.
9.24.3 The WEKA Wrapper
GATE provides a wrapper for the WEKA ML Library (http://www.cs.waikato.ac.nz/ml/weka/) in the form of the gate.creole.ml.weka.Wrapper class.
Options for the WEKA wrapper
The WEKA wrapper accepts the following options:
- CLASSIFIER: the class name for the classifier to be used.
- CLASSIFIER-OPTIONS: the options string as required for the classifier.
- CONFIDENCE-THRESHOLD: a double value. If the classifier can provide a probability distribution rather than a simple classification then all possible classifications that have a probability value larger or equal to the confidence threshold will be considered.
- DATASET-FILE: location of the weka arff file. This item is not mandatory, it is possible to specify the file using the saving option on the GUI.
9.24.4 Training an ML model with the ML PR and WEKA wrapper
The ML PR has a Boolean runtime parameter named ”training”. When the value of this parameter is set to true, the PR will collect a dataset of instances from the documents on which it is run. If the classifier used is an updatable classifier then the ML model will be built while collecting the dataset. If the selected classifier is not updatable, then the model will be built the first time a classification is attempted.
Training a model consists of designing a definition file for the ML PR, and creating an application containing an ML PR. When the application is run over a corpus, the dataset (and the model if possible) is built.
9.24.5 Applying a learnt model
Using the same ML PR, set the ”training” parameter to false and run your application.
Depending on the type of the attribute that is marked as class, different actions will be performed when a classification occurs:
- if the attribute is boolean, a new annotation of the specified type will be created with no features;
- if the attribute is nominal or numeric, a new annotation of the specified type will be created with the feature named in the attribute definition having the value predicted by the classifier.
Once a model is learnt, it can be saved and reloaded at a later time. The WEKA wrapper also provides an operation for saving only the dataset in the ARFF format, which can be used for experiments in the WEKA interface. This could be useful for determining the best algorithm to be used and the optimal options for the selected algorithm.
9.24.6 The MAXENT Wrapper [#]
GATE also provides a wrapper for the Open NLP MAXENT library (http://maxent.sourceforge.net/about.html). The MAXENT library provides an implementation of the maximum entropy learning algorithm, and can be accessed using the gate.creole.ml.maxent.MaxentWrapper class.
The MAXENT library requires all attributes except for the class attribute to be boolean, and that the class attribute be boolean or nominal. (It should be noted that, within maximum entropy terminology, the class attribute is called the ’outcome’.) Because the MAXENT library does not provide a specific format for data sets, there is no facility to save or load data sets separately from the model, but if there should be a need to do this, the WEKA wrapper can be used to collect the data.
Training a MAXENT model follows the same general procedure as for WEKA models, but the following difference should be noted. MAXENT models are not updateable, so the model will always be created and trained the first time a classification is attempted. The training of the model might take a considerable amount of time, depending on the amount of training data and the parameters of the model.
Options for the MAXENT Wrapper
- CUT-OFF: MAXENT features will only be included in the model if they occur at least this many times. (The default value of this parameter is zero.)
- ITERATIONS: The number of times the training procedure should iterate when finding the model’s parameters (default is 10). In general no more than about 100 iterations should be needed to train a model, and it is recommended that less are used during development to allow for shorter training times.
- CONFIDENCE-THRESHOLD: Same as for the WEKA wrapper (see above). However, if this parameter is not set, or is set to zero, the model will not use a confidence threshold, but will simply return the most likely classification.
- SMOOTHING: Use smoothing when training the model. Smoothing can improve the accuracy of the learned models, but it will result in longer training times, and training will use more memory. The size of the learned models will also be larger. Generally smoothing will only improve performance for those models trained from small data sets with a few outcomes. With larger data sets with lots of outcomes, it may make performance worse.
- SMOOTHING-OBSERVATION: When using smoothing, this will specify the number of times that trainer will imagine that it has seen features which it did not see (default value is 0.1).
- VERBOSE: If selected, this will cause the classifier to output more details of its operation during execution.
9.24.7 The SVM Light Wrapper [#]
From version 3.0, GATE provides a wrapper for the SVM Light ML system (http://svmlight.joachims.org). SVM Light is a support vector machine implementation, written in C, which is provided as a set of command line programs. The GATE wrapper takes care of the mundane work of converting the data structures between GATE and SVM Light formats, and calls the command line programs in the right sequence, passing the data back and forth in temporary files. The <WRAPPER> value for this engine is gate.creole.ml.svmlight.SVMLightWrapper.
The SVM Light binaries themselves are not distributed with GATE – you should download the version for your platform from http://svmlight.joachims.org and place svm_learn and svm_classify on your path.
Classifying documents using the SVMLightWrapper is a two phase procedure. In its first phase, SVMWrapper collects data from the pre-annotated documents and builds the SVM model using the collected data to classify the unseen documents in its second phase. Below we describe briefly an example of classifying the start time of the seminar in a corpus of email announcing seminars and provide more details later in the section.
Figure 9.13 explains step by step the process of collecting training data for the SVM classifier. GATE documents, which are pre-annotated with the annotations of type Class and feature type=’stime’, are used as the training data. In order to build the SVM model, we require start and end annotations for each stime annotation. We use pre-processor JAPE transduction script to mark the sTimeStart and sTimeEnd annotations on stime annotations. Following this step, the Machine Learning PR (SVMLightWrapper) with training mode set to true collects the training data from all training documents. GATE corpus pipeline, given a set of documents and PRs to execute on them, executes all PRs one by one only on one document at a time. Unless provided in a separate pipleline, it makes it impossible to send all training data (i.e. collected from all documents) altogether to the SVMWrapper using the same pipeline to build the SVM model. This results into the model not being built at the time of collecting training data. The state of the SVMWrapper can be saved to an external file once the training data is collected.

Before classifying any unseen document, SVM requires the SVM model to be available. In the absence of an up-to-date SVM model, SVMWrapper builds a new one using a command line SVM_learn utility and the training data collected from the training corpus. In other words, the first SVM model is built when user tries to classify the first document. At this point the user has an option to save the model somewhere on the external storage. This is in order to reload the model prior to classifying other documents and to avoid rebuilding of the SVM model everytime the user classifies a new set of documents. Once the model becomes available, SVMWrapper classifies the unseen documents which creates new sTimeStart and sTimeEnd annotations over the text. Finally, a post-processor JAPE transduction script is used to combine them into the sTime annotation. Figure 9.14 explains this process.
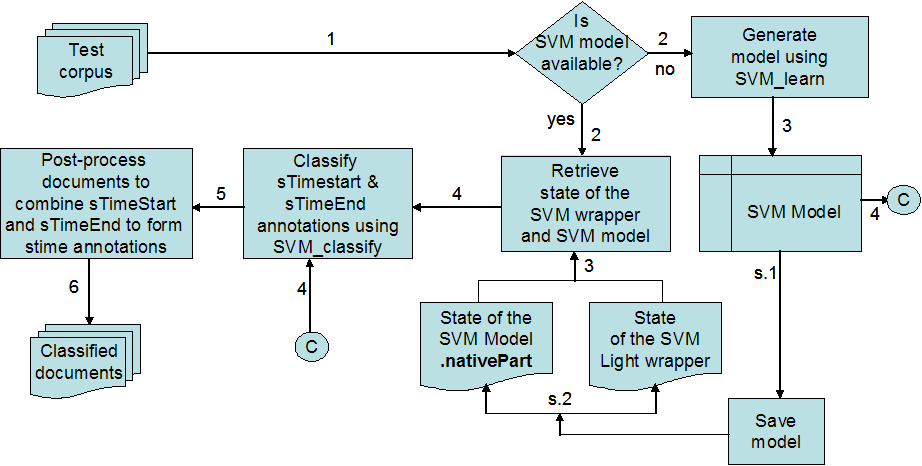
The wrapper allows support vector machines to be created which either do boolean classification or regression (estimation of numeric parameters), and so the class attribute can be boolean or numeric. Additionally, when learning a classifier, SVM Light supports transduction, whereby additional examples can be presented during training which do not have the value of the class attribute marked. Presenting such examples can, in some circumstances, greatly improve the performance of the classifier. To make use of this within GATE, the class attribute can be a three value nominal, in which case the first value specified for that nominal in the configuration file will be interpreted as true, the second as false and the third as unknown. Transduction will be used with any instances for which this attribute is set to the unknown value. It is also possible to use a two value nominal as the class attribute, in which case it will simply be interpreted as true or false.
The other attributes can be boolean, numeric or nominal, or any combination of these. If an attribute is nominal, each value of that attribute maps to a separate SVM Light feature. Each of these SVM Light features will be given the value 1 when the nominal attribute has the corresponding value, and will be omitted otherwise. If the value of the nominal is not specified in the configuration file or there is no value for an instance, then no feature will be added.
An extension to the basic functionality of SVM Light is that each attribute can receive a weighting. These weighting can be specified in the configuration file by adding <WEIGHTING> tags to the parts of the XML file specifying each attribute. The weighting for the attribute must be specified as a numeric value, and be placed between an opening <WEIGHTING> tag and a closing </WEIGHTING> one. Giving an attribute a greater weighting, will cause it to play a greater role in learning the model and classifying data. This is achieved by multiplying the value of the attribute by the weighting before creating the training or test data that is passed to SVM Light. Any attribute left without an explicitly specified weighting is given a default weighting of one. Support for these weightings is contained in the Machine Learning PR itself, and so is available to other wrappers, though at time of writing only the SVM Light wrapper makes use of weightings.
As with the MAXENT wrapper, SVM Light models are not updateable, so the model will be trained at the first classification attempt. The SVM Light wrapper supports <BATCH-MODE-CLASSIFICATION />, which should be used unless you have a very good reason not to.
The SVM Light wrapper allows both data sets and models to be loaded and saved to files in the same formats as those used by SVM Light when it is run from the command line. When a model is saved, a file will be created which contains information about the state of the SVM Light Wrapper, and which is needed to restore it when the model is loaded again. This file does not, however, contain any information about the SVM Light model itself. If an SVM Light model exists at the time of saving, and that model is up to date with respect to the current state of the training data, then it will be saved as a separate file, with the same name as the file containing information about the state of the wrapper, but with .NativePart appended to the filename. These files are in the standard SVM Light model format, and can be used with SVM Light when it is run from the command line. When a model is reloaded by GATE, both of these files must be available, and in the same directory, otherwise an error will result. However, if an up to date trained model does not exist at the time the model is saved, then only one file will be created upon saving, and only that file is required when the model is reloaded. So long as at least one training instance exists, it is possible to bring the model up to date at any point simply by classifying one or more instances (i.e. running the model with the training parameter set to false).
Options for the SVM Light engine
Only one <OPTIONS> subelement is currently supported:
- <CLASSIFIER-OPTIONS> a string of options to be passed to svm_learn on the command line. The only difference is that the user should not specify whether regression or classification is to be used, as the wrapper will detect this automatically, based on the type of the class attribute, and set the option accordingly.
9.25 MinorThird [#]
MinorThird is a collection of Java classes for storing text, annotating text, and learning to extract entities and categorize text. It was written primarily by William W. Cohen, a professor at Carnegie Mellon University in the Center for Automated Learning and Discovery, though contributions have been made by many other colleagues and students.
Minorthird’s toolkit of learning methods is integrated tightly with the tools for manually and programmatically annotating text. In Minorthird, a collection of documents are stored in a database called a ”TextBase”. Logical assertions about documents in a TextBase can be made, and stored in a special ”TextLabels” object. ”TextLabels” are a type of ”stand off annotation” — unlike XML markup (for instance), the annotations are completely independent of the text. This means that the text can be stored in its original form, and that many different types of (perhaps incompatible) annotations can be associated with the same TextBase.
Each TextLabels annotation asserts a category or property for a word, a document, or a subsequence of words. (In Minorthird, a sequence of adjacent words is called a ”span”.) As an example, these annotations might be produced by human labelers; they might be produced by a hand-writted program, or annotations by a learned program. TextLabels might encode syntactic properties (like shallow parses or part of speech tags) or semantic properties (like the functional role that entities play in a sentence). TextLabels can be nested, much like variable-binding environments can be nested in a programming language, which enables sets of hypothetical or temporary labels to be added in a local scope and then discarded.
Annotated TextBases are accessed in a single uniform way. However, they are stored in one of several schemes. A Minorthird ”repository” can be configured to hold a bunch of TextLabels and their associated TextBases.
Moderately complex hand-coded annotation programs can be implemented with a special-purpose annotation language called Mixup, which is part of Minorthird. Mixup is based on a the widely used notion of cascaded finite state transducers, but includes some powerful features, including a GUI debugging environment, escape to Java, and a kind of subroutine call mechanism. Mixup can also be used to generate features for learning algorithms, and all the text-based learning tools in Minorthird are closely integrated with Mixup. For instance, feature extractors used in a learned named-entity recognition package might call a Mixup program to perform initial preprocessing of text.
Minorthird contains a number of methods for learning to extract and label spans from a document, or learning to classify spans (based on their content or context within a document). A special case of classifying spans is classifying entire documents. Minorthird includes a number of state-of-the-art sequential learning methods (like conditional random fields, and discriminative training methods for training hidden Markov models).
One practical difficulty in using learning techniques to solve NLP problems is that the input to learners is the result of a complex chain of transformations, which begin with text and end with very low-level representations. Verifying the correctness of this chain of derivations can be difficult. To address this problem, Minorthird also includes a number of tools for visualizing transformed data and relating it to the text from which it was derived.
More information about MinorThird can be found at http://minorthird.sourceforge.net/.
9.26 MIAKT NLG Lexicon [#]
|
|
In order to lower the overhead of NLG lexicon development, we have created graphical tools for editing, storage, and maintenance of NLG lexicons, combined with a model which connects lexical entries to concepts and instances in the ontology. GATE also provides access to existing general-purpose lexicons such as WordNet and thus enables their use in NLG applications.
The structure of the NLG lexicons is similar to that of WordNet. Each lexical entry has a lemma, sense number, and syntactic information associated with it (e.g., part of speech, plural form). Each lexical entry also belongs to a synonym set or synset, which groups together all word senses which are synonymous. For example, as shown in Figure 9.15, the lemma “Magnetic Resonance Imaging scan” has one sense, its part of speech is noun, and it belongs to the synset containing also the first sense of the “MRI scan” lemma. Each synset also has a definition, which is shown in order to help the user when choosing the relevant synset for new word senses.
When the user adds a new lemma to the lexicon, it needs to be assigned to an existing synset. The editor also provides functionality for creating a new synset with part of speech and definition. (see Figure 9.16).
|
|
The advantage of a synset-based lexicon is that while there can be a one-to-one mapping between concepts and instances in the ontology and synsets, the generator can still use different lexicalisations by choosing them among those listed in the synset (e.g., MRI or Magnetic Resonance Imaging). In other words, synsets effectively correspond to concepts or instances in the ontology and their entries specify possible lexicalisations of these concepts/instances in natural language.
At present, the NLG lexicon encodes only synonymy, while other non-lexical relations present in WordNet like hypernymy and hyponymy (i.e., superclass and subclass relations) are instead derived from the ontology, using the mapping between the synsets and concepts/instances. The reason behind this architectural choice comes from the fact that ontology-based generators ultimately need to use the ontology as the knowledge source. In this framework, the role of the lexicon is to provide lexicalisations for the ontology classes and instances.
9.26.1 Complexity and Generality [#]
The lexicon model was kept as generic as possible by making it incorporate only minimal lexical information. Additional, generator-specific information can be stored in a hash table, where values can be retrieved by their name. Since these are generator specific, the current lexicon user interface does not support editing of this information, although it can be accessed and modified programmatically.
On the other hand, the NLG lexicon is based on synonym sets, so generators which subscribe to a different model of synonymy might be able to access GATE-based NLG lexicons only via a wrapper mapping between the two models.
Given that the lexicon structure follows the WordNet synset model, such a lexicon can potentially be used for language analysis, if the application only requires synonymy. Our NLG lexicon model does not support yet the richer set of relations in WordNet such as hypernymy, although it is possible to extend the current model with richer relations. Since we used the lexicon in conjunction with the ontology, such non-linguistic relations were instead taken from the ontology.
The NLG lexicon itself is also independent from the generator’s input knowledge and its format.
9.27 Kea - Automatic Keyphrase Detection [#]
Kea is a tool for automatic detection of key phrases developed at the University of Waikato in New Zealand. The home page of the project can be found at http://www.nzdl.org/Kea/.
This user guide section only deals with the aspects relating to the integration of Kea in GATE. For the inner workings of Kea, please visit the Kea web site and/or contact its authors.
In order to use Kea in GATE, the “Kea” plugin needs to be loaded using the plugins management console. After doing that, two new resource types are available for creation: the “KEA Keyphrase Extractor” (a processing resource) and the “KEA Corpus Importer” (a visual resource associated with the PR).
9.27.1 Using the “KEA Keyphrase Extractor” PR
Kea is based on machine learning and it needs to be trained before it can be used to extract keyphrases. In order to do this, a corpus is required where the documents are annotated with keyphrases. Corpora in the Kea format (where the text and keyphrases are in separate files with the same name but different extensions) can be imported into GATE using the “KEA Corpus Importer” tool. The usage of this tool is presented in a sub-section below.
Once an annotated corpus is obtained, the “KEA Keyphrase Extractor” PR can be used to build a model:
- load a “KEA Keyphrase Extractor”
- create a new “Corpus Pipeline” controller.
- set the corpus for the controller
- set the ‘trainingMode’ parameter for the PR to ‘true’
- run the application.
After these steps, the Kea PR contains a trained model. This can be used immediately by switching the ‘trainingMode’ parameter to ‘false’ and running the PR over the documents that need to be annotated with keyphrases. Another possiblity is to save the model for later use, by right-clicking on the PR name in the right hand side tree and choosing the ”Save model” option.
When a previously built model is availalbe, the training procedure does not need to be repeated, the exisiting model can be loaded in memory by selecting the “Load model” option in the PR’s pop-up menu.
The Kea PR uses several parameters as seen in Figure 9.17:
- document
- The document to be processed.
- inputAS
- The input annotation set. This parameter is only relevant when the PR is running in training mode and it specifies the annotation set containing the keyphrase annotations.
- outputAS
- The output annotation set. This parameter is only relevant when the PR is running in application mode (i.e. when the ‘trainingMode’ parameter is set to false) and it specifies the annotation set where the generated keyphrase annotations will be saved.
- minPhraseLength
- the minimum length (in number of words) for a keyphrase.
- minNumOccur
- the minimum number of occurences of a phrase for it to be a keyphrase.
- maxPhraseLength
- the maximum length of a keyphrase.
- phrasesToExtract
- how many different keyphrases should be generated.
- keyphraseAnnotationType
- the type of annotations used for keyphrases.
- dissallowInternalPeriods
- should internal periods be dissallowed.
- trainingMode
- if ‘true’ the PR is running in training mode; otherwise it is running in application mode.
- useKFrequency
- should the K-frequency be used.
9.27.2 Using Kea corpora
The authors of Kea provide on the project web page a few manually annotated corpora that can be used for training Kea. In order to do this from within GATE, these corpora need to be converted to the format used in GATE (i.e. GATE documents with annotations). This is possible using the “KEA Corpus Importer” tool which is available as a visual resource associated with the Kea PR. The importer tool can be made visible by double-clicking on the Kea PR’s name in the resources tree and then selecting the “KEA Corpus Importer” tab, see Figure 9.18.
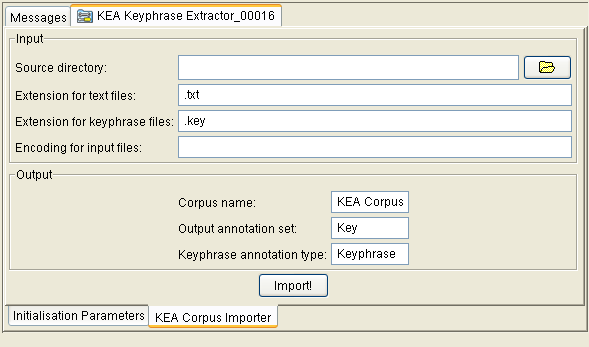
The tool will read files from a given directory, converting the text ones into GATE documents and the ones containing keyphrases into annotations over the documents.
The user needs to specify a few values:
- Source Directory
- the directory containing the text and key files. This can be typed in or selected by pressing the folder button next to the text field.
- Extension for text files
- the extension used for text fiels (by default .txt).
- Extension for keyphrase files
- the extension for the files listing keyphrases.
- Encoding for input files
- the encoding to be used when reading the files.
- Corpus name
- the name for the GATE corpus that will be created.
- Output annotaion set
- the name for the anntoation set that will contain the keyphrases read from the input files.
- Keyphrase annotation type
- the type for the generated annotations.
9.28 Ontotext JapeC Compiler [#]
Note: the JapeC compiler does not currently support the new JAPE language features introduced in July–September 2008. If you need to use negation, the @length and @string accessors, the contextual operators within and contains, or any comparison operators other than ==, then you will need to use the standard JAPE transducer instead of JapeC.
Japec is an alternative implementation of the JAPE language which works by compiling JAPE grammars into Java code. Compared to the standard implementation, these compiled grammars can be several times faster to run. At Ontotext, a modified version of the ANNIE sentence splitter using compiled grammars has been found to run up to five times as fast as the standard version. The compiler can be invoked manually from the command line, or used through the “Ontotext Japec Compiler” PR in the Jape_Compiler plugin.
The “Ontotext Japec Transducer” (com.ontotext.gate.japec.JapecTransducer) is a processing resource that is designed to be an alternative to the original Jape Transducer. You can simply replace gate.creole.Transducer with com.ontotext.gate.japec.JapecTransducer in your gate application and it should work as expected.
The Japec transducer takes the same parameters as the standard JAPE transducer:
- grammarURL
- the URL from which the grammar is to be loaded. Note that the Japec Transducer will only work on file: URLs. Also, the alternative binaryGrammarURL parameter of the standard transducer is not supported.
- encoding
- the character encoding used to load the grammars.
- ontology
- the ontology used for ontolog-aware transduction.
Its runtime parameters are likewise the same as those of the standard transducer:
- document
- the document to process.
- inputASName
- name of the AnnotationSet from which input annotations to the transducer are read.
- outputASName
- name of the AnnotationSet to which output annotations from the transducer are written.
The Japec compiler itself is written in Haskell. Compiled binaries are provided for Windows, Linux (x86) and Mac OS X (PowerPC), so no Haskell interpreter is required to run Japec on these platforms. For other platforms, or if you make changes to the compiler source code, you can build the compiler yourself using the Ant build file in the Jape_Compiler plugin directory. You will need to install the latest version of the Glasgow Haskell Compiler4 and associated libraries. The japec compiler can then be built by running:
../../bin/ant japec.clean japec
|
from the Jape_Compiler plugin directory.
9.29 ANNIC [#]
ANNIC (ANNotations-In-Context) is a full-featured annotation indexing and retrieval system. It is provided as part of an extension of the Serial Data-stores, called Searchable Serial Data-store (SSD).
ANNIC can index documents in any format supported by the GATE system (i.e., XML, HTML, RTF, e-mail, text, etc). Compared with other such query systems, it has additional features addressing issues such as extensive indexing of linguistic information associated with document content, independent of document format. It also allows indexing and extraction of information from overlapping annotations and features. Its advanced graphical user interface provides a graphical view of annotation markups over the text, along with an ability to build new queries interactively. In addition, ANNIC can be used as a first step in rule development for NLP systems as it enables the discovery and testing of patterns in corpora.
ANNIC is built on top of the Apache Lucene5 – a high performance full-featured search engine implemented in Java, which supports indexing and search of large document collections. Our choice of IR engine is due to the customisability of Lucene. For more details on how Lucene was modified to meet the requirements of indexing and querying annotations, please refer to [Aswani et al. 05].
As explained earlier, SSD is an extension of the serial data-store. In addition to the persist location, SSD asks user to provide some more information (explained later) that it uses to index the documents. Once the SSD has been initiated, user can add/remove documents/corpora to the SSD in a similar way it is done with other data-stores. When documents are added to the SSD, it automatically tries to index them. It updates the index whenever there is a change in any of the documents stored in the SSD and removes the document from the index if it is deleted from the SSD.
SSD has an advanced graphical interface that allows users to issue queries over the SSD. Below we explain the parameters required by SSD and how to instantiate it, how to use its graphical interface and how to use SSD from programmatically.
9.29.1 Instantiating SSD
Steps:
- Right click on “Data Stores” and select “Create datastore”.
- From a drop-down list select “Lucene Based Searchable DataStore”.
- Here, you will see an input window. Please provide these parameters:
- DataStore URL: Select an empty folder where the DS is created.
- Index Location: Select an empty folder. This is where the index will be created.
- Annotation Sets: Here, you can provide one or more annotation sets that you wish to index or exclude from being indexed. In order to be able to index the default annotation set, you must click on the edit list icon and add an empty field to the list. If there are no annotation sets provided, all the annotation sets in all documents are indexed. In addition to all annotation sets a new combined annotation set is created in memory which is a union of all annotations from all the annotation sets of the document being indexed. This set is also indexed in order to allow users to issue queries across various annotation sets.
- Base-Token Type: (e.g. Token or Key.Token) These are the basic tokens of any document. Your documents must have the annotations of Base-Token-Type in order to get indexed. These basic tokens are used for displaying contextual information while searching patterns in the corpus. In case of indexing more than one annotation set, user can specify the annotation set from which the tokens should be taken (e.g. Key.Token- annotations of type Token from the annotation set called Key). In case user does not provide any annotation set name (e.g. Token), the system searches in all the annotation sets to be indexed and the base-tokens from the first annotation set with the base token annotations are taken. Please note that the documents with no base-tokens are not indexed. However, if the ”create tokens automatically” option is selected, the SSD creates base-tokens automatically. Here, each string delimited with white space is considered as a token.
- Index Unit Type: (e.g. Sentence, Key.Sentence) This specifies the unit of Index. In other words, annotations lying within the boundaries of these annotations are indexed (e.g. in the case of “Sentences”, no annotations that are spanned across the boundaries of two sentences are considered for indexing). User can specify from which annotation set the index unit annotations should be considered. If user does not provide any annotation set, the SSD searches among all annotation sets for index units. If this field is left empty or SSD fails to locate index units, the entire document is considered as a single unit.
- Features: Finally, users can specify the annotation types and features that should be indexed or excluded from being indexed. (e.g. SpaceToken and Split). If user wants to exclude only a specific feature of a specific annotation type, he/she can specify it using a ’.’ separator between the annotation type and its feature (e.g. Person.matches).
- Click OK. If all parameters are OK, a new empty DS will be created.
- Create an empty corpus and save it to the SSD.
- Populate it with some documents. Each document added to the corpus and eventually to the SSD is indexed automatically. If the document does not have the required annotations, that document is skipped and not indexed.
9.29.2 Search GUI
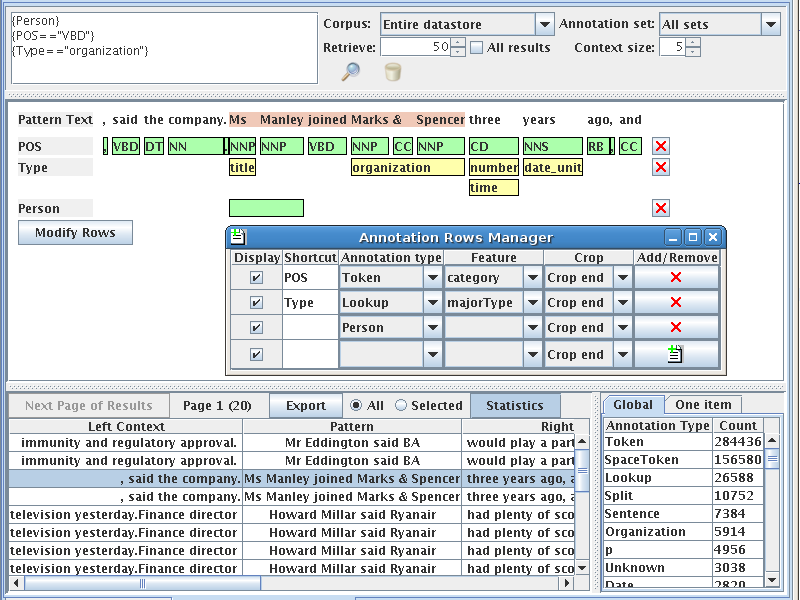
Overview
Figure 9.19 gives a snapshot of the GUI. The top section contains a text area to write a query, options to select the input data and the output format and two icons to execute and delete a query. The central section shows a graphical visualisation of annotations and values of the result selected in the bottom results table. You can also see the annotation rows manager window where you define which annotation type and feature to display in the central section. The bottom section contains the results table of the query, i.e. the text that matches the query with their left and right contexts, the annotation set and the document. The bottom section contains also a tabbed panes of statistics.
Syntax of queries
SSD enables you to formulate versatile queries using JAPE patterns. JAPE patterns support various query formats. Below we give a few examples of JAPE pattern clauses which can be used as SSD queries. Actual queries can also be a combination of one or more of the following pattern clauses:
- String
- {AnnotationType}
- {AnnotationType == String}
- {AnnotationType.feature == feature value}
- {AnnotationType1, AnnotationType2.feature == featureValue}
- {AnnotationType1.feature == featureValue, AnnotationType2.feature == featureValue}
JAPE patterns also support the | (OR) operator. For instance, {A} ({B}|{C}) is a pattern of two annotations where the first is an annotation of type A followed by the annotation of type either B or C. ANNIC supports two operators, + and *, to specify the number of times a particular annotation or a sub pattern should appear in the main query pattern. Here, ({A})+n means one and up to n occurrences of annotation {A} and ({A})*n means zero or up to n occurrences of annotation {A}.
Below we explain the steps to search in SDS.
- Double click on SSD. You will see an extra tab “Lucene DataStore Searcher”. Click on it to activate the searcher GUI.
- Here you can specify a query to search in your SSD. The query here is a L.H.S. part of the
JAPE grammar. Please refer to the following example queries:
- {Person} – This will return annotations of type Person from the SSD
- {Token.string == “Microsoft”} – This will return all occurrences of “Microsoft” from the SSD.
- {Person}({Token})*2{Organization} – Person followed by zero or upto two tokens followed by Organization.
- {Token.orth==“upperInitial”, Organization} – Token with feature orth with value set to “upperInitial” and which is also annotated as Organization.
Top section
A text-area located in the top left part of the GUI is used to input a query. You can copy/cut/paste with Control+C/X/V, undo/redo your changes with Control+Z/Y as usual. To add a new line, use Control+Enter combination keys.
Auto-completion shown on the figure 9.20 for annotation type is triggered when typing ’{’ and for feature when typing ’.’ after a valid annotation type. It shows only the annotation types and features related to the selected corpus and annotation set. If you right-click on an expression it will automatically select the shortest valid enclosing brace and if you click on a selection it will propose you to add quantifiers for allowing the expression to appear zero, one or more times.
To execute the query, click on the magnifying glass icon, use Enter key or Alt+Enter combination keys. To delete the query, click on the trash icon or use Alt+Backspace combination keys.
It is possible to have more than one corpus, each containing a different set of documents, stored in a single data-store. ANNIC, by providing a drop down box with a list of stored corpora, also allows searching within a specific (selected) corpus. Similarly a document can have more than one annotation set indexed and therefore ANNIC also provides a drop down box with a list of indexed annotation sets for the selected corpus.
A large corpus can have many hits for a given query. This may take a long time to refresh the GUI and may create inconvenience while browsing through patterns. ANNIC therefore allows you to specify a number of patterns that you wish to retrieve at once and provides a way to iterate through next pages with the Next Page of Results button. Due to technical complexities, it is not possible to visit a previous page. It is however possible to tick a check-box for retrieving all the results at the same time.
Central section
Annotation types and features to show can be selected from the annotation rows manager in clicking on the Modify Rows button in the central section. When you choose to show a feature of an annotation (e.g. feature category for annotation type Token), the central section shows colored rectangles where the annotation type are existing containing values of those features. When you choose to show only one annotation type in letting the feature column empty then all its features are displayed with empty rectangles that show their features values in a pop-up window when the mouse is over the rectangles.
Shortcuts are expression that stand for an ”AnnotationType.Feature” expression. For example, on the figure 9.19, the shortcut ”POS” stands for the expression ”Token.category”. The purpose is to make the query more readable.
When you left-clicks on any of the rectangles of the annotations rows, the respective query expression is placed at the caret position in the query text area or replace the selected expression, if any. You can also click on a word on the first line to add it to the query.
Bottom section
In the table of results, ANNIC shows each pattern retrieve from the last query executed on a row and provides a tool tip that shows the query that the selected pattern refers to.
Along with its left and right context texts, it also lists the names of the document and the annotation set that the patterns come from. When the focus changes from one row to another, the central section is updated accordingly. You can sort a table column in clicking on its header.
You can remove a result from the results table or open the document containing it in right-clicking on a result in the results table.
ANNIC provides an Export button to export in an HTML file all the results or only the selected results.
A statistics tabbed pane can be displayed on the bottom-right when clicking on the Statistics button. There is always a global statistics pane that list the count the occurrences of all annotation types for the selected corpus and annotation set.
Statistics can be obtain in 16 different ways for the datastore, matched spans of the query in the results, with or without contexts and for an annotation type, a annotation type + feature or an annotation type + feature + value. A second pane contains the one item statistics that you can add in right-clicking on a non empty rectangle or on the header of a row in the central section. You can sort a table column in clicking on its header.
9.29.3 Using SSD from your code
//how to instantiate a searchabledatastore =============================== // create an instance of datastore LuceneDataStoreImpl ds = (LuceneDataStoreImpl) Factory.createDataStore(‘‘gate.persist.LuceneDataStoreImpl’’, dsLocation); // we need to set Indexer Indexer indexer = new LuceneIndexer(new URL(indexLocation)); // set the parameters Map parameters = new HashMap(); // specify the index url parameters.put(Constants.INDEX_LOCATION_URL, new URL(indexLocation)); // specify the base token type // and specify that the tokens should be created automatically // if not found in the document parameters.put(Constants.BASE_TOKEN_ANNOTATION_TYPE, ‘‘Token’’); parameters.put(Constants.CREATE_TOKENS_AUTOMATICALLY, new Boolean(true)); // specify the index unit type parameters.put(Constants.INDEX_UNIT_ANNOTATION_TYPE, ‘‘Sentence’’); // specifying the annotation sets "Key" and "Default Annotation Set" // to be indexed List<String> setsToInclude = new ArrayList<String>(); setsToInclude.add("Key"); setsToInclude.add("<null>"); parameters.put(Constants.ANNOTATION_SETS_NAMES_TO_INCLUDE, setsToInclude); parameters.put(Constants.ANNOTATION_SETS_NAMES_TO_EXCLUDE, new ArrayList<String>()); // all features should be indexed parameters.put(Constants.FEATURES_TO_INCLUDE, new ArrayList<String>()); parameters.put(Constants.FEATURES_TO_EXCLUDE, new ArrayList<String>()); // set the indexer ds.setIndexer(indexer, parameters); // set the searcher ds.setSearcher(new LuceneSearcher()); //how to search in this datastore //====================== // obtain the searcher instance Searcher searcher = ds.getSearcher(); Map parameters = new HashMap(); // obtain the url of index String indexLocation = new File(((URL) ds.getIndexer().getParameters().get(Constants.INDEX_LOCATION_URL)) .getFile()).getAbsolutePath(); ArrayList indexLocations = new ArrayList(); indexLocations.add(indexLocation); // corpus2SearchIn = mention corpus name that was indexed here. // the annotation set to search in String annotationSet2SearchIn = "Key"; // set the parameter parameters.put(Constants.INDEX_LOCATIONS,indexLocations); parameters.put(Constants.CORPUS_ID, corpus2SearchIn); parameters.put(Constants.ANNOTATION_SET_ID, annotationSet); parameters.put(Constants.CONTEXT_WINDOW, contextWindow); parameters.put(Constants.NO_OF_PATTERNS, noOfPatterns); // search String query = ‘‘{Person}’’; Hit[] hits = searcher.search(query, parameters); |
9.30 Annotation Merging [#]
If we got annotations about the same subject on the same document from different annotators, we need to merge those annotations to form a unified annotations. The merging is applied to the annotations with the same annotation type but in different annotation sets of the same document. We implemented two approaches for annotation merging. The first method takes a parameter numMinK and selects the annotation on which at least numMinK annotators agree. If two or more merged annotations have the same span, then the annotation with the most supporters is kept and other annotations with the same span are discarded. The second method selects one annotation from those annotations with the same span, which the majority of the annotators support. Note that if one annotator did not create the annotation with the particular span, we count it as one non-support of the annotation with the span. If it turns out that the majority of the annotators did not support the annotation with that span, then no annotation with the span would be put into the merged annotations.
9.30.1 Two implemented methods
The following two static methods in the class gate.util.AnnotationMerging are for the merging methods. The two methods have very similar input and output parameters. Each of the methods takes an array of annotation sets, which should be the same annotation type on the same document from different annotators, as input. If there is one annotation feature indicating the annotation label, the name of the annotation feature is another input. Otherwise, set the input parameter for the annotation feature as null. The output is a map the key of which is one merged annotation and the value of which represents the annotators (in terms of the indices of the array of annotation sets) who support the annotation. The method also has a boolean input parameter to indicate if or not the annotations from different annotators are based on the same set of instances, which can be determined by the static method public boolean isSameInstancesForAnnotators(AnnotationSet[] annsA) in the class gate.util.IaaCalculation. One instance corresponds to all the annotations with the same span. If the annotation sets are based on the same set of instances, the merging methods will ensure that the merged annotations are on the same set of instances.
- The Method public static void mergeAnnogation(AnnotationSet[] annsArr, String
nameFeat,
HashMap<Annotation,String>mergeAnns, int numMinK, boolean isTheSameInstances) merges the annotations stored in the array annsArr. The merged annotation is put into the map mergeAnns, which key is the merged annotation and which value is a string containing the indices of elements in the annotation set array annsArr which contain that annotation. NumMinK specifies the minimal number of the annotators supporting one merged annotation. The boolean parameter isTheSameInstances indicate if or not those annotation sets for merging are based on the same instances. - Method public static void mergeAnnogationMajority(AnnotationSet[] annsArr, String nameFeat, HashMap<Annotation, String>mergeAnns, boolean isTheSameInstances) selects the annotations which the majority of the annotators agree on. The meanings of parameters are the same as those in the above method.
9.30.2 Annotation Merging Plugin
The annotation merging methods are wrapped in the plugin such that they can be used in a PR in the GATE GUI. The plugin can be used as a PR in an application of pipeline or corpus pipeline. To use the PR, each document in the pipeline or the corpus pipeline should have the annotation sets for merging. The annotation merging PR has no loading parameter but has several run-time parameters specifying the annotation merging task, explained in the following.
- annSetOutput: the annotation set in the current document for storing the merged annotations. For the sake of clearance, it had better not be an existing annotation set.
- annSetsForMerging: the annotation sets in the document for merging. It is an optional parameter. If it is not assigned with any value, the annotation sets for merging would be all the annotation sets in the document except the default annotation set. If specified, it is a sequence of the names of the annotation sets for merging, separated by “;”. For example, the value “a-1;a-2;a-3” represents three annotation set, “a-1”, “a-2” and “a-3”.
- annTypeAndFeats: the annotation types in the annotation set for merging. It is an optional parameter. It specifies the annotation types in the annotation sets for merging. For each type specified, it may also specify an annotation feature of the type and the values of the feature define the labels of the annotation type. If the parameter is not set a value, the annotation types for merging are all the types in the annotation sets for merging, and no annotation feature for each type is specified. If the parameter is specified, it is a sequence of names of annotation types, separated by “;”. If one annotation type has one particular annotation feature to indicate the label of the annotation, the annotation feature will immediately follow the annotation type’s name and is separated by “->” in the sequence. For example, the value “SENT->senRel;OPINION_OPR;OPINION_SRC->type” specifies three annotation types, “SENT”, “OPINION_OPR” and “OPINION_SRC” and specifies the annotation feature “senRel” and “type” for the two types SENT and OPINION_SRC, respectively but does not specify any feature for the type OPINION_OPR.
- mergingMethod specifies the method used for merging. Currently it has two values MajorityVoting and MergingByAnnotatorNum, referring to the two merging methods described above, respectively.
- minimalAnnNum specifies the minimal number of annotators who agree on one annotation in order to put the annotation into merged set, which is needed by the merging method MergingByAnnotatorNum. If the value of the parameter is smaller than 1, set the parameter as 1. If the value is bigger than total number of annotation sets for merging, set the parameter as the total number of annotation sets. If not assigning anything to the parameter in the GUI, it use the default value 1. Note that the parameter does not have any effect on another merging method MajorityVoting.
9.31 OntoRoot Gazetteer [#]
OntoRoot Gazetteer is a type of a dynamically created gazetteer that is, in combination with few other generic GATE resources, capable of producing ontology-aware annotations over the given content with regards to given ontology. This gazetteer is a part of Ontology_Based_Gazetteer plugin that has been developed as a part of TAO project.
9.31.1 How does it work? [#]
To produce ontology-aware annotations i.e. annotations that link to the specific concepts or relations from the ontology, it is essential to pre-process the Ontology Resources (e.g., Classes, Instances, Properties) and extract their human-understandable lexicalisations.
As a precondition for extracting human-understandable content from the ontology first a list of the following is being created:
- names of all ontology resources i.e. fragment identifiers 6 and
- assigned property values for all ontology resources (e.g., label and datatype property values)
Each item from the list is further processed so that:
- any name containing dash ("-") or underline ("_") character(s) is processed so that each of these characters is replaced by a blank space. For example, Project_Name or Project-Name would become a Project Name.
- any name that is written in camelCase style is actually split into its constituent words, so that ProjectName becomes a Project Name (optional).
- any name that is a compound name such as ’POS Tagger for Spanish’ is split so that both ’POS Tagger’ and ’Tagger’ are added to the list for processing. In this example, ’for’ is a stop word, and any words after it are ignored (optional).
Each item from this list is analysed separately by the Onto Root Application (ORA) on execution (see figure 9.21). The Onto Root Application first tokenises each linguistic term, then assigns part-of-speech and lemma information to each token.
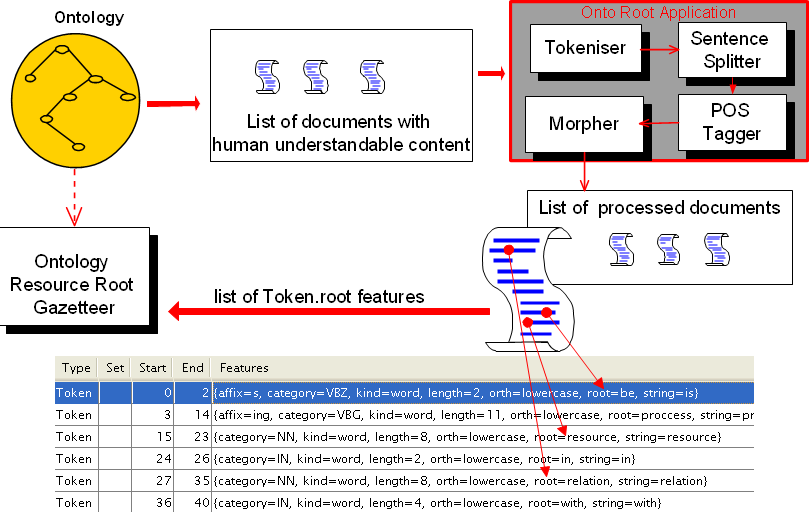
As a result of that pre-processing, each token in the terms will have additional feature named ’root’, which contains the lemma as created by the morphological analyser. It is this lemma or a set of lemmas which are then added to the dynamic gazetteer list, created from the ontology.
For instance, if there is a resource with a short name (i.e., fragment identifier) ProjectName, without any assigned properties the created list before executing the OntoRoot gazetteer collection will contain following the strings:
- ’ProjectName’,
- ’Project Name’ after separating camelCased word and
- ’Name’ after applying heuristic rules.
Each of the item from the list is then analysed separately and the results would be the same as the input strings, as all of entries are nouns given in singular form.
9.31.2 Initialisation of OntoRoot Gazetteer [#]
To initialise the gazetteer there are few mandatory parameters:
- Ontology to be processed;
- Tokeniser, POS Tagger and GATE Morphological Analyser to be used during processing.
and few optional ones:
- useResourceUri, default is set to true - should this gazetteer analyse resource URIs or not;
- considerProperties, default is set to true - should this gazetteer consider properties or not;
- propertiesToInclude - checked only if considerProperties is set to true - this parameter contains the list of property names (URIs) to be included, comma separated;
- propertiesToExclude - checked only if emphconsiderProperties is set to true - this parameter contains the list of property names to be excluded, comma separated;
- caseSensitive, default set to be false -should this gazetteer diferentiate on case;
- separateCamelCasedWords, default set to true - should this gazetteer separate emphcamelCased words, e.g. ’ProjectName’ into ’Project Name’;
- considerHeuristicRules, default set to false - should this gazetteer consider several heuristic rules or not. Rules include splitting the words containing spaces, and using prepositions as stop words; for example, if ’pos tagger for spanish’ would be analysed, ’for’ would be considered as a stop word; heuristically derived would be ’pos tagger’ and this would be further used to add ’pos tagger’ to the gazeetteer list, with a feature emphheuristical level set to be 0, and ’tagger’ with emphheuristical level 1; at runtime lower heuristical level should be prefered. NOTE: setting considerHeuristicRules to true can cause a lot of noise for some ontologies and is likely to require implementing an additional filterring resource that will prefer the annotations with the lower heuristic level;
1shef.nlp.supple.prolog.SICStusProlog exists for backwards compatibility and behaves the same as SICStusProlog3.
2resources/englishPCFG.ser.gz
3resources/english-tag-map.txt
4GHC version 6.4.1 was used to build the supplied binaries for Windows, Linux and Mac
5http://lucene.apache.org
6An ontology resource is usually identified by an URI concatenated with a set of characters starting with ’#’. This set of characters is called fragment identifier. For example, if the URI of a class representing GATE POS Tagger is: ’http://gate.ac.uk/ns/gate-ontology#POSTagger’, the fragment identifier will be ’POSTagger’.
