Chapter 7
JAPE: Regular Expressions Over Annotations [#]
If Osama bin Laden did not exist, it would be necessary to invent him. For the past four years, his name has been invoked whenever a US president has sought to increase the defence budget or wriggle out of arms control treaties. He has been used to justify even President Bush’s missile defence programme, though neither he nor his associates are known to possess anything approaching ballistic missile technology. Now he has become the personification of evil required to launch a crusade for good: the face behind the faceless terror.
The closer you look, the weaker the case against Bin Laden becomes. While the terrorists who inflicted Tuesday’s dreadful wound may have been inspired by him, there is, as yet, no evidence that they were instructed by him. Bin Laden’s presumed guilt appears to rest on the supposition that he is the sort of man who would have done it. But his culpability is irrelevant: his usefulness to western governments lies in his power to terrify. When billions of pounds of military spending are at stake, rogue states and terrorist warlords become assets precisely because they are liabilities.
The need for dissent, George Monbiot, The Guardian, Tuesday September 18, 2001.
This chapter describes JAPE – a Java Annotation Patterns Engine. JAPE provides finite state transduction over annotations based on regular expressions. JAPE is a version of CPSL – Common Pattern Specification Language1.
JAPE allows you to recognise regular expressions in annotations on documents. Hang on, there’s something wrong here: a regular language can only describe sets of strings, not graphs, and GATE’s model of annotations is based on graphs. Hmmm. Another way of saying this: typically, regular expressions are applied to character strings, a simple linear sequence of items, but here we are applying them to a much more complex data structure. The result is that in certain cases the matching process in non-deterministic (i.e. the results are dependent on random factors like the addresses at which data is stored in the virtual machine): when there is structure in the graph being matched that requires more than the power of a regular automaton to recognise, JAPE chooses an alternative arbitrarily. However, this is not the bad news that it seems to be, as it turns out that in many useful cases the data stored in annotation graphs in GATE (and other language processing systems) can be regarded as simple sequences, and matched deterministically with regular expressions.
A JAPE grammar consists of a set of phases, each of which consists of a set of pattern/action rules. The phases run sequentially and constitute a cascade of finite state transducers over annotations. The left-hand-side (LHS) of the rules consist of an annotation pattern that may contain regular expression operators (e.g. *, ?, +). The right-hand-side (RHS) consists of annotation manipulation statements. Annotations matched on the LHS of a rule may be referred to on the RHS by means of labels that are attached to pattern elements.
At the beginning of each grammar, several options can be set:
- Control - this defines the method of rule matching (see Section 7.3)
- Debug - when set to true, if the grammar is running in Appelt mode and there is more than one possible match, the conflicts will be displayed on the standard output. See also Section 7.5.
Input annotations must also be defined at the start of each grammar. If no annotations are defined, all annotations will be matched.
There are 3 main ways in which the pattern can be specified:
- specify a string of text, e.g. {Token.string == "of"}
- specify the presence or absence of an annotation previously assigned from a gazetteer, tokeniser, or other module, e.g. {Lookup} (matches a Lookup annotation) or {!Lookup} (matches if there is not a Lookup annotation at this location).
- specify the attributes (and values) of an annotation. Several operators are supported - see
section 7.1 for full details:
- {Token.kind == "number"}, {Token.length != 4} - equality and inequality.
- {Token.string > "aardvark"}, {Token.length < 10} - comparison operators. >= and <= are also supported.
- {Token.string =~ "[Dd]ogs"}, {Token.string !~ "(?i)hello"} - regular expression. ==~ and !=~ are also provided, for whole-string matching.
- {X contains Y} and {X within Y} for checking annotations within the context of other annotations.
Macros can also be used in the LHS of rules. This means that instead of expressing the information in the rule, it is specified in a macro, which can then be called in the rule. The reason for this is simply to avoid having to repeat the same information in several rules. Macros can themselves be used inside other macros.
New as of September 2008, in addition to referencing annotation features, JAPE allows access to other ”meta-properties” of an annotation. This is done by using an ”@” symbol rather than a ”.” symbol after the annotation type name. The three meta-properties that are built in are:
- length - returns the spanning length of the annotation.
- string - returns the string spanned by the annotation in the document.
- cleanString - Like string, but with extra white space stripped out. (i.e. ”\s+” goes to a single space and leading or trailing white space is removed).
At this time, you cannot access the value of a ”meta-property” from a non-java RHS of a rule. (e.g. You can’t write: {X@length > "5"}:label-->:label.New = {somefeat = :label.X@length }. We hope to add this at some point.
The same union and kleen operators can be used as for the tokeniser rules, i.e.
|
* ? + |
New as of late-September 2008, a range notation can also be added. e.g.
({Token})[1,3]
|
matches one to three Tokens in a row.
({Token.kind == number})[3]
|
matches exactly 3 number Tokens in a row.
The pattern description is followed by a label for the annotation. A label is denoted by a preceding colon; in the example below, the label is :location.
The RHS of the rule contains information about the annotation. Information about the annotation is transferred from the LHS of the rule using the label just described, and annotated with the entity type (which follows it). Finally, attributes and their corresponding values are added to the annotation. Alternatively, the RHS of the rule can contain Java code to create or manipulate annotations.
In the simple example below, the pattern described will be awarded an annotation of type “Enamex” (because it is an entity name). This annotation will have the attribute “kind”, with value “location”, and the attribute “rule”, with value “GazLocation”. (The purpose of the “rule” attribute is simply to ease the process of manual rule validation).
Rule: GazLocation
( {Lookup.majorType == location} ) :location --> :location.Enamex = {kind="location", rule=GazLocation} |
It is also possible to have more than one pattern and corresponding action, as shown in the rule below. On the LHS, each pattern is enclosed in a set of round brackets and has a unique label; on the RHS, each lable is associated with an action. In this example, the Lookup annotation is labelled “jobtitle” and is given the new annotation JobTitle; the TempPerson annotation is labelled “person” and is given the new annotation “Person”.
Rule: PersonJobTitle
Priority: 20 ( {Lookup.majorType == jobtitle} ):jobtitle ( {TempPerson} ):person --> :jobtitle.JobTitle = {rule = "PersonJobTitle"}, :person.Person = {kind = "personName", rule = "PersonJobTitle"} |
Similarly, labelled patterns can be nested, as in the example below, where the whole pattern is annotated as Person, but within the pattern, the jobtitle is annotated as JobTitle.
Rule: PersonJobTitle2
Priority: 20 ( ( {Lookup.majorType == jobtitle} ):jobtitle {TempPerson} ):person --> :jobtitle.JobTitle = {rule = "PersonJobTitle"}, :person.Person = {kind = "personName", rule = "PersonJobTitle"} |
JAPE provides limited support for copying annotation feature values from the left to the right hand side of a rule, for example:
Rule: LocationType
( {Lookup.majorType == location} ):loc --> :loc.Location = {rule = "LocationType", type = :loc.Lookup.minorType} |
This will set the ”type” feature of the generated location to the value of the ”minorType” feature from the ”Lookup” annotation bound to the loc label. If the Lookup has no minorType, the Location will have no ”type” feature. The behaviour of newFeat = :bind.Type.oldFeat is:
- Find all the annotations of type Type from the left hand side binding bind.
- Find one of them that has a non-null value for its oldFeat feature (if there is more than one, which one is chosen is up to the JAPE implementation).
- If such a value exists, set the newFeat feature of our newly created annotation to this value.
- If no such non-null value exists, do not set the newFeat feature at all.
Notice that the behaviour is deliberately underspecified if there is more than one Type annotation in bind. If you need more control, or if you want to copy several feature values from the same left hand side annotation, you should consider using Java code on the right hand side of your rule (see section 7.7).
Grammar rules can essentially be of two types. The first type of rule involves no gazetteer lookup, but can be defined using a small set of possible formats. In general, these are fairly straightforward and offer little potential for ambiguity.
The second type of rules rely more heavily on the gazetteer lists, and cover a much wider range of possibilities. This not only means that many rules may be needed to describe all situations, but that there is a much greater potential for ambiguity. This leads to the necessity for rule ordering and prioritisation, as will be discussed below.
For example, a single rule is sufficient to identify an IP address, because there is only one basic format - a series of numbers, each set connected by a dot. The rule for this is given below2:
Rule: IPAddress
( {Token.kind == number} {Token.string == "."} {Token.kind == number} {Token.string == "."} {Token.kind == number} {Token.string == "."} {Token.kind == number} ) :ipAddress --> :ipAddress.Address = {kind = "ipAddress"} |
To identify a date or time, there are many possible variations, and so many rules are needed. For example, the same date information can appear in the following formats (amongst others):
Wed, 10/7/00
Wed, 10/July/00 Wed, 10 July, 2000 Wed 10th of July, 2000 Wed. July 10th, 2000 Wed 10 July 2000 |
Different types of date can also be expressed. For example, the following would also be classified as date entities:
the late ’80s
Monday St. Andrew’s Day 99 BC mid-November 1980-81 from March to April |
This also means there is a much greater potential for ambiguity. For example, many of the months of the year can also be girls’ Christian names (e.g. May, June). This means that contextual information may be needed to disambiguate them, or we may have to guess which is more likely, based on frequency. For example, while “Friday” could be a person’s name (as in “Man Friday”), it is much more likely to be a day of the week.
Finally, macros can also be used on the RHS of rules. In this case, the label (which matches the label on the LHS of the rule) should be included in the macro. Below we give an example of using a macro on the RHS.
Macro: UNDERSCORES_OKAY // separate
:match // lines { gate.AnnotationSet matchedAnns = (gate.AnnotationSet)bindings.get("match"); int begOffset = matchedAnns.firstNode().getOffset().intValue(); int endOffset = matchedAnns.lastNode().getOffset().intValue(); String mydocContent = doc.getContent().toString(); String matchedString = mydocContent.substring(begOffset, endOffset); gate.FeatureMap newFeatures = Factory.newFeatureMap(); if(matchedString.equals("Spanish")) { newFeatures.put("myrule", "Lower"); } else { newFeatures.put("myrule", "Upper"); } newFeatures.put("quality", "1"); annotations.add(matchedAnns.firstNode(), matchedAnns.lastNode(), "Spanish_mark", newFeatures); } Rule: Lower ( ({Token.string == "Spanish"}) :match)-->UNDERSCORES_OKAY // no label here, only macro name Rule: Upper ( ({Token.string == "SPANISH"}) :match)-->UNDERSCORES_OKAY // no label here, only macro name |
7.1 Matching operators in detail [#]
This section gives more detail on the behaviour of the matching operators used on the left-hand side of JAPE rules.
7.1.1 Equality operators (“==” and “!=”)
The basic operator in JAPE is equality. {Lookup.majorType == "person"} matches a Lookup annotation whose majorType feature has the value “person”. Similarly {Lookup.majorType != "person"} would match any Lookup whose majorType feature does not have the value “person”. If a feature is missing it is treated as if it had an empty string as its value, so this would also match a Lookup annotation that did not have a majorType feature at all.
Certain type coercions are performed:
- If the constraint’s attribute is a string, it is compared with the annotation feature value using string equality (String.equals()).
- If the constraint’s attribute is an integer it is treated as a java.lang.Long. If the annotation feature value is also a Long, or is a string that can be parsed as a Long, then it is compared using Long.equals().
- If the constraint’s attribute is a floating-point number it is treated as a java.lang.Double. If the annotation feature value is also a Double, or is a string that can be parsed as a Double, then it is compared using Double.equals().
- If the constraint’s attribute is true or false (without quotes) it is treated as a java.lang.Boolean. If the annotation feature value is also a Boolean, or is a string that can be parsed as a Boolean, then it is compared using Boolean.equals().
The != operator matches exactly when == doesn’t.
7.1.2 Comparison operators (“<”, “<=”, “>=” and “>”)
Comparison operators have their expected meanings, for example {Token.length > 3} matches a Token annotation whose length attribute is an integer greater than 3. The behaviour of the operators depends on the type of the constraint’s attribute:
- If the constraint’s attribute is a string it is compared with the annotation feature value using Unicode-lexicographic order (see String.compareTo()).
- If the constraint’s attribute is an integer it is treated as a java.lang.Long. If the annotation feature value is also a Long, or is a string that can be parsed as a Long, then it is compared using Long.compareTo().
- If the constraint’s attribute is a floating-point number it is treated as a java.lang.Double. If the annotation feature value is also a Double, or is a string that can be parsed as a Double, then it is compared using Double.compareTo().
7.1.3 Regular expression operators (“=~”, “==~”, “!~” and “!=~”) [#]
These operators match regular expressions. {Token.string =~ "[Dd]ogs"} matches a Token annotation whose string feature contains a substring that matches the regular expression [Dd]ogs, using !~ would match if the feature value does not contain a substring that matches the regular expression. The ==~ and !=~ operators are like =~ and !~ respectively, but require that the whole value match (or not match) the regular expression3. As with ==, missing features are treated as if they had the empty string as their value, so the constraint {Identifier.name ==~ "(?i)[aeiou]*"} would match an Identifier annotation which does not have a name feature, as well as any whose name contains only vowels.
The matching uses the standard Java regular expression library, so full details of the pattern syntax can be found in the JavaDoc documentation for java.util.regex.Pattern. There are a few specific points to note:
- To enable flags such as case-insensitive matching you can use the (?flags) notation. See the Pattern JavaDocs for details.
- If you need to include a double quote character in a regular expression you must precede it with a backslash, otherwise JAPE will give a syntax error. Quoted strings in JAPE grammars also convert the sequences \n, \r and \t to the characters newline (U+000A), carriage return (U+000D) and tab (U+0009) respectively, but these characters can match literally in regular expressions so it does not make any difference to the result in most cases.4
7.1.4 Contextual operators (“contains” and “within”) [#]
These operators match annotations within the context of other annotations.
- contains - Written as {X contains Y}, returns true if an annotation of type X completely contains an annotation of type Y.
- within - Written as {X within Y}, returns true if an annotation of type X is completely covered by an annotation of type Y.
For either operator, the right-hand value (Y in the above examples) can be a full constraint itself. For example {X contains {Y.foo=bar}} is also accepted. The operators can be used in a multi-constraint statement just like any of the traditional ones, so {X.f1 != "something", X contains {Y.foo=bar}} is valid.
It is possible to add additional custom operators without modifying the JAPE language. There are new init-time parameters to Transducer so that additional annotation ”meta-property” accessors and custom operators can be referenced at runtime. To add a custom operator, write a class that implements gate.jape.constraint.ConstraintPredicate, and then list that class name for the Transducer’s ”operators” property. Similarly, to add a custom ”meta-property” accessor, write a class that implements gate.jape.constraint.AnnotationAccessor, and then list that class name in the Transducer’s ”annotationAccessors” property.
7.2 Use of Context
Context can be dealt with in the grammar rules in the following way. The pattern to be annotated is always enclosed by a set of round brackets. If preceding context is to be included in the rule, this is placed before this set of brackets. This context is described in exactly the same way as the pattern to be matched. If context following the pattern needs to be included, it is placed after the label given to the annotation. Context is used where a pattern should only be recognised if it occurs in a certain situation, but the context itself does not form part of the pattern to be annotated.
For example, the following rule for Time (assuming an appropriate macro for “year”) would mean that a year would only be recognised if it occurs preceded by the words “in” or “by”:
Rule: YearContext1
({Token.string == "in"}| {Token.string == "by"} ) (YEAR) :date --> :date.Timex = {kind = "date", rule = "YearContext1"} |
Similarly, the following rule (assuming an appropriate macro for “email”) would mean that an email address would only be recognised if it occurred inside angled brackets (which would not themselves form part of the entity):
Rule: Emailaddress1
({Token.string == ‘‘<’’}) ( (EMAIL) ) ({Token.string == ‘‘>’’}) --> :email.Address= {kind = "email", rule = "Emailaddress1"} |
Also, it is possible to specify the constraint that one annotation must start at the same place as another. For example:
Rule: SurnameStartingWithDe
( {Token.string == "de", Lookup.majorType == "name", Lookup.minorType == "surname"} ):de --> :de.Surname = {prefix = "de"} |
This rule would match anywhere where a Token with string “de” and a Lookup with majorType “name” and minorType “surname” start at the same offset in the text. Both the Lookup and Token annotations would be included in the :de binding, so the Surname annotation generated would span the longer of the two. Constraints on the same annotation type must be satisfied by a single annotation, so in this example there must be a single Lookup matching both the major and minor types – the rule would not match if there were two different lookups at the same location, one of them satisfying each constraint.
7.3 Use of Priority [#]
Each grammar has one of 5 possible control styles: “brill”, “all”, “first”, “once” and “appelt”. This is specified at the beginning of the grammar.
The Brill style means that when more than one rule matches the same region of the document, they are all fired. The result of this is that a segment of text could be allocated more than one entity type, and that no priority ordering is necessary. Brill will execute all matching rules starting from a given position and will advance and continue matching from the position in the document where the longest match finishes.
The ”all” style is similar to Brill, in that it will also execute all matching rules, but the matching will continue from the next offset to the current one.
For example, where [] are annotations of type Ann
[aaa[bbb]] [ccc[ddd]]
|
then a rule matching {Ann} and creating {Ann-2} for the same spans will generate:
BRILL: [aaabbb] [cccddd]
ALL: [aaa[bbb]] [ccc[ddd]] |
With the “first” style, a rule fires for the first match that’s found. This makes it unappropiate for rules that end in ”+” or ”?” or ”*”. Once a match is found the rule is fired; it does not attempt to get a longer match (as the other two styles do).
With the ”once” style, once a rule has fired, the whole JAPE phase exits after the first match.
With the appelt style, only one rule can be fired for the same region of text, according to a set of priority rules. Priority operates in the following way.
- From all the rules that match a region of the document starting at some point X, the one which matches the longest region is fired.
- If more than one rule matches the same region, the one with the highest priority is fired
- If there is more than one rule with the same priority, the one defined earlier in the grammar is fired.
An optional priority declaration is associated with each rule, which should be a positive integer. The higher the number, the greater the priority. By default (if the priority declaration is missing) all rules have the priority -1 (i.e. the lowest priority).
For example, the following two rules for location could potentially match the same text.
Rule: Location1
Priority: 25 ( ({Lookup.majorType == loc_key, Lookup.minorType == pre} {SpaceToken})? {Lookup.majorType == location} ({SpaceToken} {Lookup.majorType == loc_key, Lookup.minorType == post})? ) :locName --> :locName.Location = {kind = "location", rule = "Location1"} Rule: GazLocation Priority: 20 ( ({Lookup.majorType == location}):location ) --> :location.Name = {kind = "location", rule=GazLocation} |
Assume we have the text “China sea”, that “China” is defined in the gazetteer as “location”, and that sea is defined as a “loc_key” of type “post”. In this case, rule Location1 would apply, because it matches a longer region of text starting at the same point (“China sea”, as opposed to just “China”). Now assume we just have the text “China”. In this case, both rules could be fired, but the priority for Location1 is highest, so it will take precedence. In this case, since both rules produce the same annotation, so it is not so important which rule is fired, but this is not always the case.
One important point of which to be aware is that prioritisation only operates within a single grammar. Although we could make priority global by having all the rules in a single grammar, this is not ideal due to other considerations. Instead, we currently combine all the rules for each entity type in a single grammar. An index file (main.jape) is used to define which grammars should be used, and in which order they should be fired.
7.4 Use of negation [#]
All the examples in the preceding sections involve constraints that require the presence of certain annotations to match. JAPE also supports “negative” constraints which specify the absence of annotations. A negative constraint is signalled in the grammar by a “!” character.
Negative constraints are generally used in combination with positive ones to constrain the locations at which the positive constraint can match. For example:
Rule: PossibleName
( {Token.orth == "upperInitial", !Lookup} ):name --> :name.PossibleName = {} |
This rule would match any uppercase-initial Token, but only where there is no Lookup annotation starting at the same location. The general rule is that a negative constraint matches at any location where the corresponding positive constraint would not match. Negative constraints do not contribute any annotations to the bindings - in the example above, the :name binding would contain only the Token annotation. The exception to this is when a negative constraint is used alone, without any positive constraints in the combination. In this case it binds all the annotations at the match position that do not match the constraint. Thus, {!Lookup} would bind all the annotations starting at this location except Lookups. In most cases, negative constraints should only be used in combination with positive ones.
Any constraint can be negated, for example:
Rule: SurnameNotStartingWithDe
( {Surname, !Token.string ==~ "[Dd]e"} ):name --> :name.NotDe = {} |
This would match any Surname annotation that does not start at the same place as a Token with the string ”de” or ”De”. Note that this is subtly different from {Surname, Token.string !=~ "[Dd]e"}, as the second form requires a Token annotation to be present, whereas the first form (!Token...) will match if there is no Token annotation at all at this location.5
7.5 Useful tricks [#]
Although the JAPE language has some limitations as to how rules and patterns can be expressed, there are some useful tricks to overcome these problems.
- Using priority to resolve ambiguity. If the Appelt style of matching is selected, rule priority
operates in the following way.
- Length of rule – a rule matching a longer pattern will fire first.
- Explicit priority declaration. Use the optional Priority function to assign a ranking. The higher the number, the higher the priority. If no priority is stated, the default is -1.
- Order of rules. In the case where the above two factors do not distinguish between two rules, the order in which the rules are stated applies. Rules stated first have higher priority.
Because priority can only operate within a single grammar, this can be a problem for dealing with ambiguity issues. One solution to this is to create a temporary set of annotations in initial grammars, and then manipulate this temporary set in one or more later phases (for example, by converting temporary annotations from different phases into permanent annotations in a single final phase). See the default set of grammars for an example of this.
- Negative operator. JAPE provides an operator to look for the absence of a single annotation
type (see section 7.4), but there is no support for a general negative operator to
prevent a rule from firing if a particular sequence of annotations is found. One
solution to this is to create a “negative rule” which has higher priority than the
matching “positive rule”. The style of matching must be Appelt for this to work.
To create a negative rule, simply state on the LHS of the rule the pattern that
should NOT be matched, and on the RHS do nothing. In this way, the positive rule
cannot be fired if the negative pattern matches, and vice versa, which has the
same end result as using a negative operator. A useful variation for developers is
to create a dummy annotation on the RHS of the negative rule, rather than to
do nothing, and to give the dummy annotation a rule feature. In this way, it is
obvious that the negative rule has fired. Alternatively, use Java code on the RHS
to print a message when the rule fires. An example of a matching negative and
positive rule follows. Here, we want a rule which matches a surname followed by a
comma and a set of initials. But we want to specify that the initials shouldn’t have
the POS category PRP (personal pronoun). So we specify a negative rule that
will fire if the PRP category exists, thereby preventing the positive rule from
firing.
Rule: NotPersonReverse
Priority: 20
// we don’t want to match ’’Jones, I’’
(
{Token.category == NNP}
{Token.string == ","}
{Token.category == PRP}
)
:foo
-->
{}
Rule: PersonReverse
Priority: 5
// we want to match ‘‘Jones, F.W.’’
(
{Token.category == NNP}
{Token.string == ","}
(INITIALS)?
)
:person --> - Matching special characters. To specify a single or double quote as a string, precede it with a
backslash, e.g.
{Token.string=="\""}
will match a double quote. For other special characters, such as “$”, enclose it in double quotes, e.g.
{Token.category == "PRP\$"} - Referring to previous annotations. An annotation generated in one phase can be referred to in a later phase, in exactly the same way as any other kind of annotation (by specifying the name of the annotation within curly braces). The features and values can be referred to or omitted, as with all other annotations. Make sure that if the Input specification is used in the grammar, that the annotation to be referred to is included in the list.
- Using context. Specify left or right context around a pattern by enclosing it in round brackets
outside the round brackets of the pattern. In the example below, the context “in” must
precede the location to be annotated. Only the location will be annotated, but it is
important to remember that context is consumed by the rule, so it cannot be reused in
another rule within the same phase. So, for example, right context cannot be used as left
context for another rule.
Rule:InLoc1
// in PARIS
(
{Token.string == "in"}
)
(
{Lookup.majorType == location}
)
:locName - Debug. Add the following to the options at the top of the grammar.
Options: control = appelt debug = true
- Avoid conflicts. If two possible ways of matching are found for the same text string, a conflict can arise. Normally this is handled by the priority mechanism (test length, rule priority and finally rule precedence). If all these are equal, Jape will simply choose a match at random and fire it. This leads ot non-deterministic behaviour, which should be avoided.
- Using Java code on the RHS. If you want to be flash, you can use any Java code you like on the RHS of the rule. This is useful for feature percolation (see below), for deleting previous annotations, measuring length of strings, and performing alternative operations depending on particular features of the annotation. See 7.7 for more details.
- Feature percolation. To copy features from previous annotations, where the value of the feature is unknown, some simple Java code can be used. See Section 7.7 for a more detailed explanation of this.
- Adding a feature to the document. Instead of adding a feature to an annotation, a
feature can be added to the document as a whole. For example, the following
code on the RHS would add the feature “texttype” with value “sport” to the
document.
doc.getFeatures().put("texttype", ‘‘sport’’);
- Overlapping annotations. Once JAPE has matched something, that part of the input is
”consumed” and it moves on to the next position. This means that it does not recognise
overlapping annotations in patterns, e.g. where matching overlapping lookups from the
gazetteer. For example, for a string ”hALCAM” with the lookups ”hAL”, ”ALCAM” and
”CAM”, only the first lookup ”hAL” will be recognised by the grammar rule that matches
lookups. After the grammar has matched ”hAL” it will continue with ”CAM” hence skipping
”ALCAM” completely.
The trick to handle this kind of situations is to delete the used up lookups and run again the same grammar over the same input. You may need to repeat this several times until you’ve used up all your lookups. The number of repetitions required needs to be determined experimentally.
7.6 Ontology aware grammar transduction [#]
GATE supports two different methods for ontology aware grammar transduction. Firstly it is possible to use the ontology feature both in grammars and annotations, while using the default transducer. Secondly it is possible to use an ontology aware transducer by passing an ontology language resource to one of the subsumes methods in SimpleFeatureMapImpl. This second strategy does not check for ontology features, which will make the writing of grammars easier, as there is no need to specify ontology when writing them. More information about the ontology-aware transducer can be found in Section 10.6.
7.7 Using Java code in JAPE rules [#]
The RHS of a JAPE rule can consist of any Java code. This is useful for removing temporary annotations and for percolating and manipulating features from previous annotations. In the example below
The first rule below shows a rule which matches a first person name, e.g. “Fred”, and adds a gender feature depending on the value of the minorType from the gazetteer list in which the name was found. We first get the bindings associated with the person label (i.e. the Lookup annotation). We then create a new annotation called “personAnn” which contains this annotation, and create a new FeatureMap to enable us to add features. Then we get the minorType features (and its value) from the personAnn annotation (in this case, the feature will be “gender” and the value will be “male”), and add this value to a new feature called “gender”. We create another feature “rule” with value “FirstName”. Finally, we add all the features to a new annotation “FirstPerson” which attaches to the same nodes as the original “person” binding.
Note that inputAS and outputAS represent the input and output annotation set. Normally, these would be the same (by default when using ANNIE, these will be the “Default” annotation set). Since the user is at liberty to change the input and output annotation sets in the paramters of the JAPE transducer at runtime, it cannot be guaranteed that the input and output annotation sets will be the same, and therefore we must specify the annotation set we are referring to.
Rule: FirstName
( {Lookup.majorType == person_first} ):person --> { gate.AnnotationSet person = (gate.AnnotationSet)bindings.get("person"); gate.Annotation personAnn = (gate.Annotation)person.iterator().next(); gate.FeatureMap features = Factory.newFeatureMap(); features.put("gender", personAnn.getFeatures().get("minorType")); features.put("rule", "FirstName"); outputAS.add(person.firstNode(), person.lastNode(), "FirstPerson", features); } |
The second rule (contained in a subsequent grammar phase) makes use of annotations produced by the first rule described above. Instead of percolating the minorType from the annotation produced by the gazetteer lookup, this time it percolates the feature from the annotation produced by the previous grammar rule. So here it gets the “gender” feature value from the “FirstPerson” annotation, and adds it to a new feature (again called “gender” for convenience), which is added to the new annotation (in outputAS) “TempPerson”. At the end of this rule, the existing input annotations (from inputAS) are removed because they are no longer needed. Note that in the previous rule, the existing annotations were not removed, because it is possible they might be needed later on in another grammar phase.
Rule: GazPersonFirst
( {FirstPerson} ) :person --> { gate.AnnotationSet person = (gate.AnnotationSet)bindings.get("person"); gate.Annotation personAnn = (gate.Annotation)person.iterator().next(); gate.FeatureMap features = Factory.newFeatureMap(); features.put("gender", personAnn.getFeatures().get("gender")); features.put("rule", "GazPersonFirst"); outputAS.add(person.firstNode(), person.lastNode(), "TempPerson", features); inputAS.removeAll(person); } |
7.7.1 Adding a feature to the document
The following example code shows how to add the feature “genre” with value “email” to the document, using JAVA code on the RHS of a rule:
Rule: Email
Priority: 150 ( {message} ) --> { doc.getFeatures().put("genre", "email"); } |
7.7.2 Using named blocks [#]
For the common case where a Java block refers just to the annotations from a single left-hand-side binding, JAPE provides a shorthand notation:
Rule: RemoveDoneFlag
( {Instance.flag == "done"} ):inst --> :inst{ Annotation theInstance = (Annotation)instAnnots.iterator().next(); theInstance.getFeatures().remove("flag"); } |
This rule is equivalent to the following:
Rule: RemoveDoneFlag
( {Instance.flag == "done"} ):inst --> { AnnotationSet instAnnots = (AnnotationSet)bindings.get("inst"); if(instAnnots != null && instAnnots.size() != 0) { Annotation theInstance = (Annotation)instAnnots.iterator().next(); theInstance.getFeatures().remove("flag"); } } |
A label :<label> on a Java block creates a local variable <label>Annots within the Java block which is the AnnotationSet bound to the <label> label. Also, the Java code in the block is only executed if there is at least one annotation bound to the label, so you do not need to check this condition in your own code. Of course, if you need more flexibility, e.g. to perform some action in the case where the label is not bound, you will need to use an unlabelled block and perform the bindings.get() yourself.
7.7.3 Java RHS overview [#]
When a JAPE grammar is parsed, a Jape parser creates action classes for all Java RHSs in the grammar. (one action class per RHS) RHS Java code will be embedded as a body of the method doIt and will work in context of this method. When a particular rule is fired, the method doIt will be executed.
Method doIt is specified by the interface gate.jape.RhsAction. Each action class implements this interface and is generated with the following template:
import java.io.*;
import java.util.*; import gate.*; import gate.jape.*; import gate.creole.ontology.Ontology; import gate.annotation.*; import gate.util.*; class <AutogeneratedActionClassName> implements java.io.Serializable, RhsAction { public void doIt(Document doc, java.util.Map bindings, AnnotationSet annotations, AnnotationSet inputAS, AnnotationSet outputAS, Ontology ontology) { // your RHS Java code will be embedded here ... } } |
Method doIt has the following parameters that can be used in RHS Java code:
- Document doc - a document that is currently processed
- java.util.Map bindings - a map of binding variables where a key is a (String) name of binding variable and value is (AnnotationSet) set of annotations corresponding to this binding variable
- AnnotationSet annotations - Do not use this (it’s a synonym for outputAS that is still used in some grammars but is now deprecated).
- AnnotationSet inputAS - input annotations
- AnnotationSet outputAS - output annotations
- Ontology ontology - a GATE’s transducer ontology
In your Java RHS you can use short names for all Java classes that are imported by the action class (plus Java classes from the packages that are imported by default according to JVM specification: java.lang.*, java.math.*). But you need to use fully qualified Java class names for all other classes. For example:
-->
{ // VALID line examples AnnotationSet as = ... InputStream is = ... java.util.logging.Logger myLogger = java.util.logging.Logger.getLogger("JAPELogger"); java.sql.Statement stmt = ... // INVALID line examples Logger myLogger = Logger.getLogger("JapePhaseLogger"); Statement stmt = ... } |
7.8 Optimising for speed [#]
The way in which grammars are designed can have a huge impact on the processing speed. Some simple tricks to keep the processing as fast as possible are:
- avoid the use of the * and + operators. Replace them with ? where possible. For example,
instead of
({Token})*
use
({Token})? ({Token})? ({Token})?if you can predict that you won’t need to recognise a string of Tokens longer than 3.
- avoid specifying unnecessary elements such as SpaceTokens where you can. To do this, use the Input specification at the beginning of the grammar to stipulate the annotations that need to be considered. If no Input specification is used, all annotations will be considered (so, for example, you cannot match two tokens separated by a space unless you specify the SpaceToken in the pattern). If, however, you specify Tokens but not SpaceTokens in the Input, SpaceTokens do not have to be mentioned in the pattern to be recognised. If, for example, there is only one rule in a phase that requires SpaceTokens to be specified, it may be judicious to move that rule to a separate phase where the SpaceToken can be specified as Input.
- avoid the shorthand syntax for copying feature values (newFeat = :bind.Type.oldFeat), particularly if you need to copy multiple features from the left to the right hand side of your rule.
7.9 Serializing JAPE Transducer [#]
JAPE grammars are written as files with the extension ”.jape”, which are parsed and compiled at run-time to execute them over the GATE document(s). Serialization of the JAPE Transducer adds the capability to serialize such grammar files and use them later to bootstrap new JAPE transducers, where they do not need the original JAPE grammar file. This allows people to distribute the serialized version of their grammars without disclosing the actual contents of their jape files. This is implemented as part of the JAPE Transducer PR. The following sections describe how to serialize and deserialize them.
7.9.1 How to serialize?
Once an instance of a JAPE transducer is created, the option to serialize it appears in the option menu of that instance. The option menu can be activated by right clicking on the respective PR. Having done so, it asks for the file name where the serialized version of the respective JAPE grammar is stored.
7.9.2 How to use the serialized grammar file?
The JAPE Transducer now also has an init-time parameter binaryGrammarURL, which appears as an optional parameter to the grammarURL. The User can use this parameter (i.e. binaryGrammarURL) to specify the serialized grammar file.
7.10 The JAPE Debugger [#]
The Jape debugger helps to find errors in Jape programs enabling the user to see in detail how a Jape rule works when applied to a particular range of text. It was written by Ontos, who also provided the original version of this documentation. The debugger allows the user to select a particular part of the text, and then look at the detailed history of processing. This will enable them to see which rules were matched and which were not, and also why particular rules were or were not matched. It is also possible to set breakpoints for particular rules, enabling the user to see how the rule was matched, and what annotations were created.
The Jape debugger could be useful in situations where the old simple DEBUG OUTPUT method does not help. For example when:
- A Rule LHS has not been matched.
- Text did not match the expected template of a rule.
- The rule was overridden by another conflicting rule.
- Annotations are created, but it is not possible to tell which rule created them.
7.10.1 Debugger GUI
The layout of the JAPE-debugger user interface is shown in Figure 7.1.
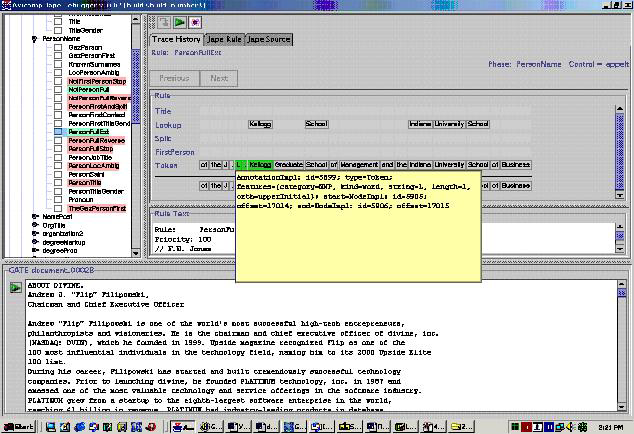
The debugger’s main frame consists of the following primary components:
- Resources tree (appears in the left side of the main frame and contains all the resources available within the current GATE session).
- Debugging panel (located at the center of the main frame and contains three tabs providing all necessary debugging information).
- Document panel (provides you with the document on which you are currently debugging).
7.10.2 Using the Debugger
In most situations you will use the debugger in trace mode using the following steps:
- initialize JAPE-debugger from the GATE menu (Tools / JAPE Debugger);
- run a GATE serial controller (This can be done either from GATE or from the debugger. Note: for performance reasons, the debugger doesnt gather matching information when its not running, so run GATE serial controller after you open the debugger window);
- select the part of the text that is interesting for debugging purposes, and press the button at the left of the text to update the view of the debugger.
After these steps the following information becomes available. In the Resources tree some of the rules become highlighted in different colors:
- Green means that the rule has matched successfully.
- Yellow means that it matched, but was overridden by another rule.
- Red means that the rule tried to match, but failed.
Trace history is the main debugging tab in Debugging panel. It contains the source of the JAPE rule currently selected, and the selected text in the document panel. All the inputs are shown, and matched inputs are highlighted in green. Annotations, which made the rule fail, are highlighted in red. If a rule tried to match more than one time on the selected text interval, buttons on the top of the panel (Previous and Next) become enabled, and allow one to observe all the matching attempts of the rule. Clicking on any of the inputs shows an annotation window, and the tool tip of the matched words gives the template in the rule.
Step by Step Example
To give an idea of how to use debugger for fixing bugs, lets consider the following example. For instance, there is a rule named PersonFullExt, which should find person names: A. B. Dick, J. F. Kennedy and so on, and create an annotation Person. To test the rule, we run GATE on a text fragment containing the following words: the J.L. Kellogg Graduate School, so we would expect that the part of the text J. L. Kellogg should get an annotation Person. Unfortunately, we encounter a problem (because only L. Kellogg was matched), so we decide to use the debugger to find the reason for this unexpected behavior. With JAPE-debugger, it is possible to observe everything needed during for finding and fixing the error.
The appropriate screenshot is shown in Figure 7.2.
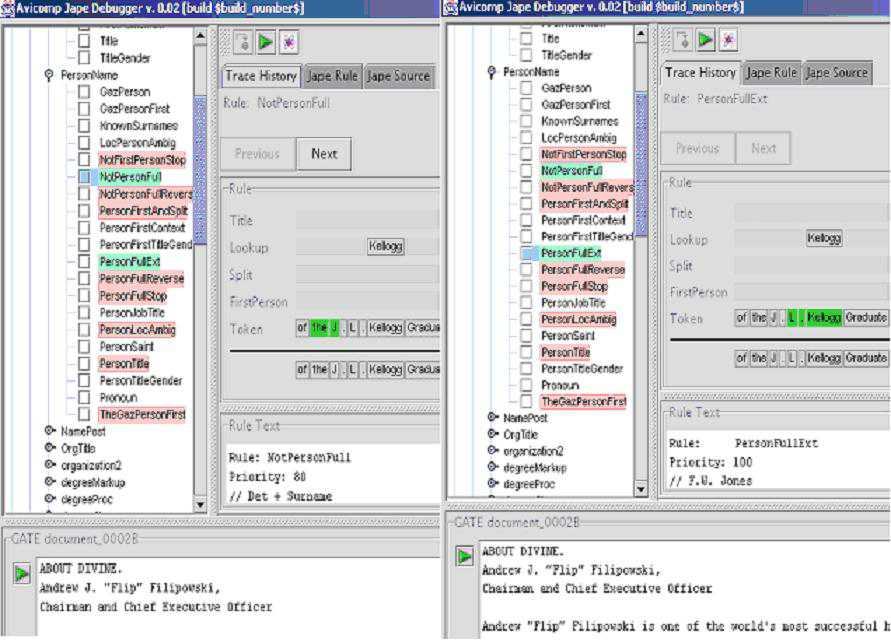
As you can see, the rule NotPersonFull matched the text ‘the J’, so the rule PersonFullExt could start matching only after the pointer has moved to the token ‘.’. Without the debugger, it wouldn’t be so easy to find the reason for this error, because the rule NotPersonFull doesn’t create any annotations.
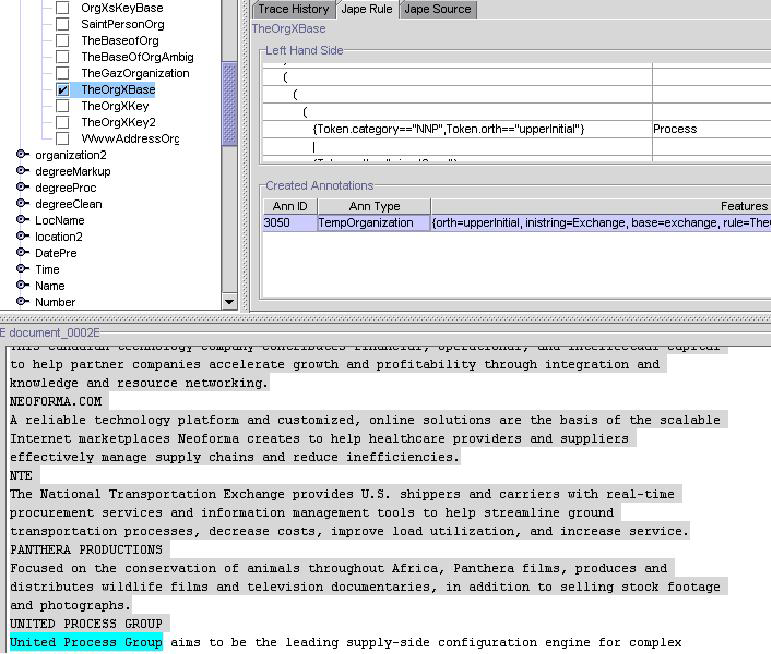
An additional feature of the debugger is the availability of debugging with breakpoints (Jape Rule Tab). After setting a breakpoint on a given rule (in our case it is the rule named TheOrgXBase), the GATE transducer will be interrupted at the breakpoint, and in the document panel the text that is currently matched by the rule (it is highlighted in cyan) will be displayed. In the tab, a special table representation of the rule (with what it matches on the left side), and the history of annotations created by this rule, will be displayed, as in Figure 7.3.
7.10.3 Known Bugs
1. Debugger doesn’t see processing resource reinitialization. A possible workaround is to close and open the resource again.
7.11 Notes for Montreal Transducer users [#]
In June 2008, the standard JAPE transducer implementation gained a number of features inspired by Luc Plamondon’s ”Montreal Transducer”, which has been available as a GATE plugin for several years. If you have existing Montreal Transducer grammars and want to update them to work with the standard JAPE implementation you should be aware of the following differences in behaviour:
- Quantifiers (*, + and ?) in the Montreal transducer are always greedy, but this is not necessarily the case in standard JAPE.
- The Montreal Transducer defines {Type.feature != value} to be the same as {!Type.feature == value} (and likewise the !~ operator in terms of =~). In standard JAPE these constructs have different semantics. {Type.feature != value} will only match if there is a Type annotation whose feature feature does not have the given value, and if it matches it will bind the single Type annotation. {!Type.feature == value} will match if there is no Type annotation at a given place with this feature (including when there is no Type annotation at all), and if it matches it will bind every other annotation that starts at that location. If you have used != in your Montreal grammars and want them to continue to behave the same way you must change them to use the prefix-! form instead (see section 7.4).
- The =~ operator in standard JAPE looks for regular expression matches anywhere within a feature value, whereas in the Montreal transducer it requires the whole string to match. To obtain the whole-string matching behaviour in standard JAPE, use the ==~ operator instead (see section 7.1.3).
1A good description of the original version of this language is in Doug Appelt’s TextPro manual. Doug was a great help to us in implementing JAPE. Thanks Doug!
2We might be more specific and state the possible lengths of the number, but within the confines of this project we currently have no need to, because there is no ambiguity with anything else
3This syntax will be familiar to Groovy users.
4However this does mean that it is not possible to include an n, r or t character after a backslash in a JAPE quoted string, or to have a backslash as the last character of your regular expression. Workarounds include placing the backslash in a character class ([\\]—) or enabling the (?x) flag, which allows you to put whitespace between the backslash and the offending character without changing the meaning of the pattern.
5In the Montreal transducer, the two forms were equivalent
