The GATE Process
The GATE Process describes the steps you need to take if you want to create predictable and sustainable language processing capabilities in your organisation. The process is supported by software (most notably GATE Teamware), but it is not primarily based on tools. The process encapsulates expert knowledge and the use of that knowledge to build, educate and direct multi-role teams whose work involves the complex workflows (or business processes) necessary to do text analysis (etc.) in a cost-effective, sustainable and accurate manner.
The process covers four areas:
- data integration and domain modelling (with Ontotext)
- content enrichment (via information extraction or semantic annotation)
- search, navigation and presentation (with Ontotext)
- systems integration
The process is specified as a set of UML activity diagrams which are supported by business process management tooling, GATE Teamware, GATE Developer and GATE embedded.
To implement the GATE process in your organisation, contact the GATE team.
Why a Process?
Three reasons:
First, successful deployment of language-based or semantic technology is most often not just about software but about sets of interlocking capabilities (both human and machine) working together over time.
Second, we need a process for the same reason that manufacturers now rely more on quality assurance (QA) than quality control: it is better to prevent errors from occurring (as in QA) than try to fix them when they do (as in quality control). QA relies on continual measurement of quality and on the implementation of workflow predictability; the GATE process brings these characteristics to the deployment of language processing.
Third, over the last 15 years the GATE team have been involved in numerous applications of text processing, from business intelligence to web mining, from voice of the customer to news indexing. Along the way we have built systems for clients as diverse as the BBC Archives or Oxford University's Sumerian corpus, British Telecom's digital library or MedCPU's decision support engine. We have also helped out or observed on a large number of projects for other people using GATE. In the early 2000s we came to understand that although we had produced some of the best tools available for supporting the development of these applications by specialists, in practice there were several other key stakeholders and staff roles involved that are crucial to success. In addition, these staff must participate in a complex workflow in order to guarantee success at predictable cost, and to establish performance beyond the lifetime of the initial development project.
Therefore we developed a process, and a set of workflow-driven web tools to support it. This process is a set of steps to follow in the definition, prototyping, development, deployment and maintenance of SA processes. (I.e.: this section is not about "get this great new bit of software and it will transform your life", but "this is how to implement robust and maintainable services".) The process helps answers questions such as:
- how to decide if annotation is applicable to your problem
- how to define the problem with reference to a corpus of examples
- how to identify similarities with other problems and thence to estimate likely performance levels
- how to design a balance of adaptation interventions for system setup and maintenance
- how to measure success
Process Elements
The GATE Process is currently customised specifically for each client of the team. Below we list some example steps from previous processes; see also Text Analysis Lifecycles with GATE.
- first we try to describe in an imprecise way what type of annotation is
relevant to the client's business case. this step includes:
- example data collection (text, audio, video, speech transcription)
- informal end-user systems analysis and identification of information need
- analogy with previous SA systems
- identification of any domain-specific terminologies, taxonomies or ontologies that are relevant to the information need (e.g. JPO f-terms)
- estimation of likely task complexity, domain specificity and hence machine accuracy levels
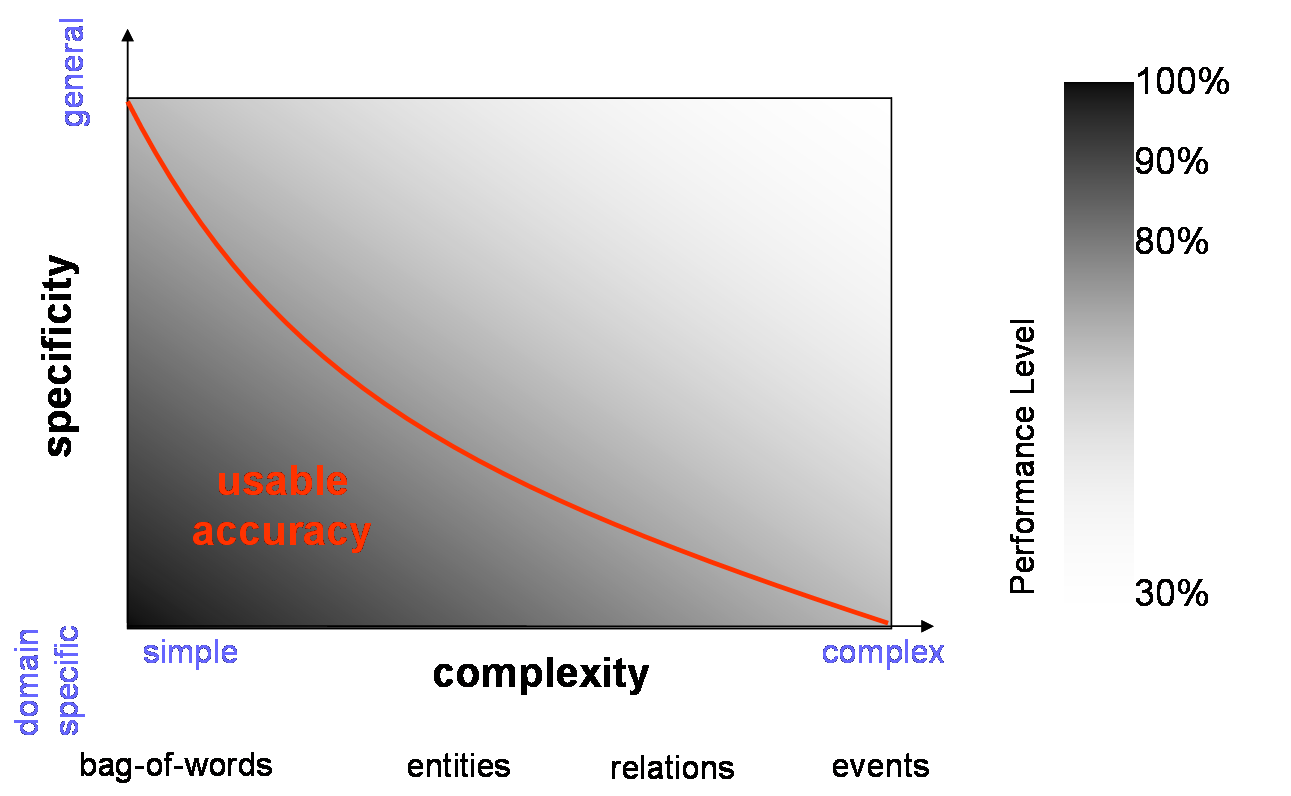
- this then allows us to place your SA requirement on the following graph:
the distance above the curve where a task appears is proportional to the
level of manual input required
- see also this diagram on domain
specificity vs. task complexity; the axes on the graph correspond to:
- Simple tasks: document clustering, full-text search, entities ...
- Complex tasks: relations and events, cross-document reference
- Specific domains: chemical engineering job descriptions, football reports
- General domains: all news sites, a corporate intranet, the web
- see also this diagram on domain
specificity vs. task complexity; the axes on the graph correspond to:
- next we do some trial annotation and a small-scale indicative mockup of the
results in order to verify that we understand properly the type of
annotation relevant to the client, and revise the specification as necessary
- in this phase we try and get multiple stakeholders to do some annotation according to the inexact specification developed previously. then we examine in details the differences between different people' interpretations of the specification, and iterate until we've produced an annotation task manual exact enough to achieve reliable inter-annotator agreement
- then
- bootstrap an IE sys
- import and/or creation of terminology/taxonomy/ontology
- learning
- measurement
- this results in a prototype which quantifies
- eventual machine accuracy levels relative to LE staff resource
- annotation revision staff resource
- curation and maintenance staff resource
- the resource picture includes the following elements (each of which is
relative to the level of accuracy that has been defined as needed for the
eventual annotation consumer):
- the first step produces a resource estimate for 100% manual performance of the task
- we then draw a curve of progressively less manual intervention as first the baseline IE system is implemented by the LE staff and then ML learns from HA staff and the system is tuned by the IC and LE staff; this element includes a measure of the amount of data needed until the ML process converges (if that amount is practical to obtain)
- the final point on the curve represents the level of HA resource required in order to maintain the same performance level; IC (and possible LE) staff resource may also be required depending on the mutation rate of the information need and/or the input text)

{kind=link}