Chapter 1
Introduction [#]
Software documentation is like sex: when it is good, it is very, very good; and when it is bad, it is better than nothing. (Anonymous.)
There are two ways of constructing a software design: one way is to make it so simple that there are obviously no deficiencies; the other way is to make it so complicated that there are no obvious deficiencies. (C.A.R. Hoare)
A computer language is not just a way of getting a computer to perform operations but rather that it is a novel formal medium for expressing ideas about methodology. Thus, programs must be written for people to read, and only incidentally for machines to execute. (The Structure and Interpretation of Computer Programs, H. Abelson, G. Sussman and J. Sussman, 1985.)
If you try to make something beautiful, it is often ugly. If you try to make something useful, it is often beautiful. (Oscar Wilde)1
GATE2 is an infrastructure for developing and deploying software components that process human language. It is nearly 15 years old and is in active use for all types of computational task involving human language. GATE excels at text analysis of all shapes and sizes. From large corporations to small startups, from €multi-million research consortia to undergraduate projects, our user community is the largest and most diverse of any system of this type, and is spread across all but one of the continents3.
GATE is open source free software; users can obtain free support from the user and developer community via GATE.ac.uk or on a commercial basis from our industrial partners. We are the biggest open source language processing project with a development team more than double the size of the largest comparable projects (many of which are integrated with GATE4). More than €5 million has been invested in GATE development5; our objective is to make sure that this continues to be money well spent for all GATE’s users.
The GATE family of tools has grown over the years to include a desktop client for developers, a workflow-based web application, a Java library, an architecture and a process. GATE is:
- an IDE, GATE Developer: an integrated development environment6 for language processing components bundled with a very widely used Information Extraction system and a comprehensive set of other plugins
- a cloud computing solution for hosted large-scale text processing, GATE Cloud (http://gatecloud.net/). See also Chapter 22.
- a web app, GATE Teamware: a collaborative annotation environment for factory-style semantic annotation projects built around a workflow engine and a heavily-optimised backend service infrastructure. See also Chapter 23.
- a multi-paradigm search repository, GATE Mímir, which can be used to index and search over text, annotations, semantic schemas (ontologies), and semantic meta-data (instance data). It allows queries that arbitrarily mix full-text, structural, linguistic and semantic queries and that can scale to terabytes of text. See also Chapter 24.
- a framework, GATE Embedded: an object library optimised for inclusion in diverse applications giving access to all the services used by GATE Developer and more.
- an architecture: a high-level organisational picture of how language processing software composition.
- a process for the creation of robust and maintainable services.
We also develop:
- a wiki/CMS, GATE Wiki (http://gatewiki.sf.net/), mainly to host our own websites and as a testbed for some of our experiments
For more information on the GATE family see http://gate.ac.uk/family/ and also Part IV of this book.
One of our original motivations was to remove the necessity for solving common engineering problems before doing useful research, or re-engineering before deploying research results into applications. Core functions of GATE take care of the lion’s share of the engineering:
- modelling and persistence of specialised data structures
- measurement, evaluation, benchmarking (never believe a computing researcher who hasn’t measured their results in a repeatable and open setting!)
- visualisation and editing of annotations, ontologies, parse trees, etc.
- a finite state transduction language for rapid prototyping and efficient implementation of shallow analysis methods (JAPE)
- extraction of training instances for machine learning
- pluggable machine learning implementations (Weka, SVM Light, ...)
On top of the core functions GATE includes components for diverse language processing tasks, e.g. parsers, morphology, tagging, Information Retrieval tools, Information Extraction components for various languages, and many others. GATE Developer and Embedded are supplied with an Information Extraction system (ANNIE) which has been adapted and evaluated very widely (numerous industrial systems, research systems evaluated in MUC, TREC, ACE, DUC, Pascal, NTCIR, etc.). ANNIE is often used to create RDF or OWL (metadata) for unstructured content (semantic annotation).
GATE version 1 was written in the mid-1990s; at the turn of the new millennium we completely rewrote the system in Java; version 5 was released in June 2009; and version 6 — in November 2010. We believe that GATE is the leading system of its type, but as scientists we have to advise you not to take our word for it; that’s why we’ve measured our software in many of the competitive evaluations over the last decade-and-a-half (MUC, TREC, ACE, DUC and more; see Section 1.4 for details). We invite you to give it a try, to get involved with the GATE community, and to contribute to human language science, engineering and development.
This book describes how to use GATE to develop language processing components, test their performance and deploy them as parts of other applications. In the rest of this chapter:
- Section 1.1 describes the best way to use this book;
- Section 1.2 briefly notes that the context of GATE is applied language processing, or Language Engineering;
- Section 1.3 gives an overview of developing using GATE;
- Section 1.4 lists publications describing GATE performance in evaluations;
- Section 1.5 outlines what is new in the current version of GATE;
- Section 1.6 lists other publications about GATE.
Note: if you don’t see the component you need in this document, or if we mention a component that you can’t see in the software, contact gate-users@lists.sourceforge.net7 – various components are developed by our collaborators, who we will be happy to put you in contact with. (Often the process of getting a new component is as simple as typing the URL into GATE Developer; the system will do the rest.)
1.1 How to Use this Text [#]
The material presented in this book ranges from the conceptual (e.g. ‘what is software architecture?’) to practical instructions for programmers (e.g. how to deal with GATE exceptions) and linguists (e.g. how to write a pattern grammar). Furthermore, GATE’s highly extensible nature means that new functionality is constantly being added in the form of new plugins. Important functionality is as likely to be located in a plugin as it is to be integrated into the GATE core. This presents something of an organisational challenge. Our (no doubt imperfect) solution is to divide this book into three parts. Part I covers installation, using the GATE Developer GUI and using ANNIE, as well as providing some background and theory. We recommend the new user to begin with Part I. Part II covers the more advanced of the core GATE functionality; the GATE Embedded API and JAPE pattern language among other things. Part III provides a reference for the numerous plugins that have been created for GATE. Although ANNIE provides a good starting point, the user will soon wish to explore other resources, and so will need to consult this part of the text. We recommend that Part III be used as a reference, to be dipped into as necessary. In Part III, plugins are grouped into broad areas of functionality.
1.2 Context [#]
GATE can be thought of as a Software Architecture for Language Engineering [Cunningham 00].
‘Software Architecture’ is used rather loosely here to mean computer infrastructure for software development, including development environments and frameworks, as well as the more usual use of the term to denote a macro-level organisational structure for software systems [Shaw & Garlan 96].
Language Engineering (LE) may be defined as:
…the discipline or act of engineering software systems that perform tasks involving processing human language. Both the construction process and its outputs are measurable and predictable. The literature of the field relates to both application of relevant scientific results and a body of practice. [Cunningham 99a]
The relevant scientific results in this case are the outputs of Computational Linguistics, Natural Language Processing and Artificial Intelligence in general. Unlike these other disciplines, LE, as an engineering discipline, entails predictability, both of the process of constructing LE-based software and of the performance of that software after its completion and deployment in applications.
Some working definitions:
- Computational Linguistics (CL): science of language that uses computation as an investigative tool.
- Natural Language Processing (NLP): science of computation whose subject matter is data structures and algorithms for computer processing of human language.
- Language Engineering (LE): building NLP systems whose cost and outputs are measurable and predictable.
- Software Architecture: macro-level organisational principles for families of systems. In this context is also used as infrastructure.
- Software Architecture for Language Engineering (SALE): software infrastructure, architecture and development tools for applied CL, NLP and LE.
(Of course the practice of these fields is broader and more complex than these definitions.)
In the scientific endeavours of NLP and CL, GATE’s role is to support experimentation. In this context GATE’s significant features include support for automated measurement (see Chapter 10), providing a ‘level playing field’ where results can easily be repeated across different sites and environments, and reducing research overheads in various ways.
1.3 Overview [#]
1.3.1 Developing and Deploying Language Processing Facilities [#]
GATE as an architecture suggests that the elements of software systems that process natural language can usefully be broken down into various types of component, known as resources8. Components are reusable software chunks with well-defined interfaces, and are a popular architectural form, used in Sun’s Java Beans and Microsoft’s .Net, for example. GATE components are specialised types of Java Bean, and come in three flavours:
- LanguageResources (LRs) represent entities such as lexicons, corpora or ontologies;
- ProcessingResources (PRs) represent entities that are primarily algorithmic, such as parsers, generators or ngram modellers;
- VisualResources (VRs) represent visualisation and editing components that participate in GUIs.
These definitions can be blurred in practice as necessary.
Collectively, the set of resources integrated with GATE is known as CREOLE: a Collection of REusable Objects for Language Engineering. All the resources are packaged as Java Archive (or ‘JAR’) files, plus some XML configuration data. The JAR and XML files are made available to GATE by putting them on a web server, or simply placing them in the local file space. Section 1.3.2 introduces GATE’s built-in resource set.
When using GATE to develop language processing functionality for an application, the developer uses GATE Developer and GATE Embedded to construct resources of the three types. This may involve programming, or the development of Language Resources such as grammars that are used by existing Processing Resources, or a mixture of both. GATE Developer is used for visualisation of the data structures produced and consumed during processing, and for debugging, performance measurement and so on. For example, figure 1.1 is a screenshot of one of the visualisation tools.
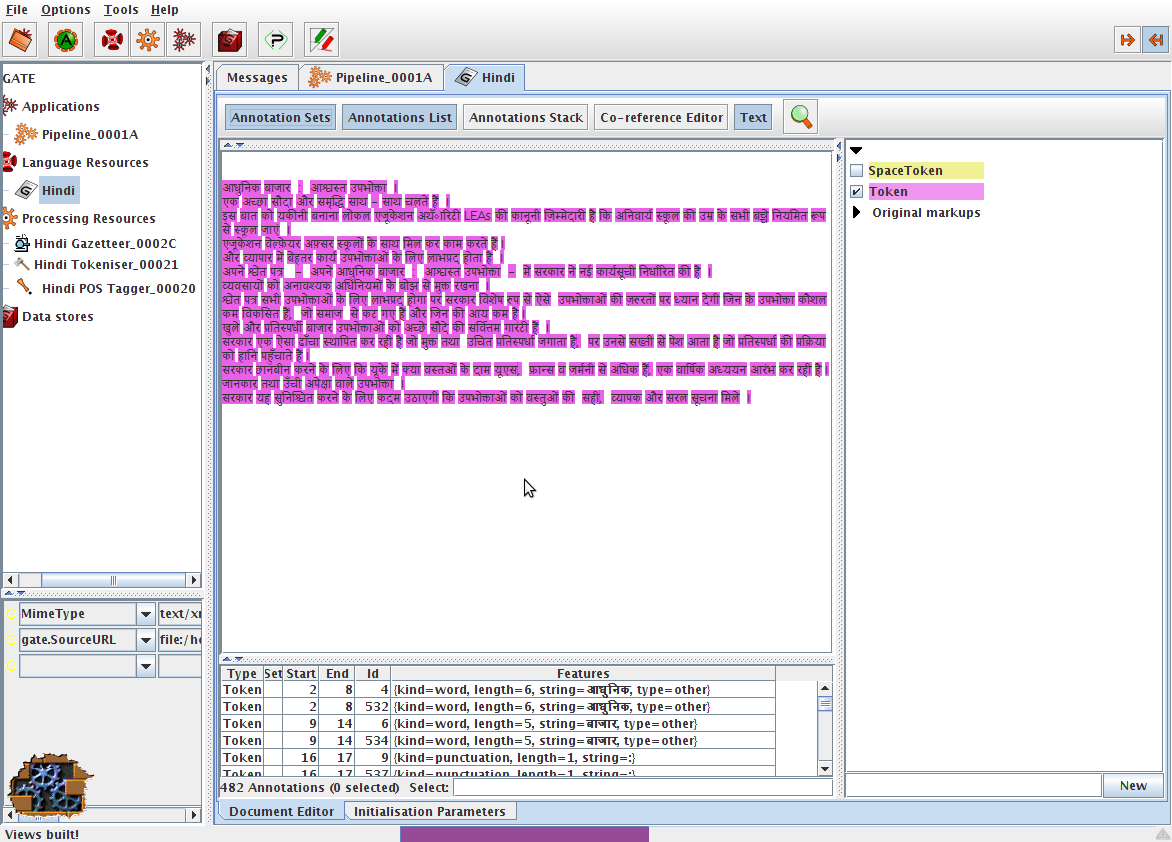
GATE Developer is analogous to systems like Mathematica for Mathematicians, or JBuilder for Java programmers: it provides a convenient graphical environment for research and development of language processing software.
When an appropriate set of resources have been developed, they can then be embedded in the target client application using GATE Embedded. GATE Embedded is supplied as a series of JAR files.9 To embed GATE-based language processing facilities in an application, these JAR files are all that is needed, along with JAR files and XML configuration files for the various resources that make up the new facilities.
1.3.2 Built-In Components [#]
GATE includes resources for common LE data structures and algorithms, including documents, corpora and various annotation types, a set of language analysis components for Information Extraction and a range of data visualisation and editing components.
GATE supports documents in a variety of formats including XML, RTF, email, HTML, SGML and plain text. In all cases the format is analysed and converted into a single unified model of annotation. The annotation format is a modified form of the TIPSTER format [Grishman 97] which has been made largely compatible with the Atlas format [Bird & Liberman 99], and uses the now standard mechanism of ‘stand-off markup’. GATE documents, corpora and annotations are stored in databases of various sorts, visualised via the development environment, and accessed at code level via the framework. See Chapter 5 for more details of corpora etc.
A family of Processing Resources for language analysis is included in the shape of ANNIE, A Nearly-New Information Extraction system. These components use finite state techniques to implement various tasks from tokenisation to semantic tagging or verb phrase chunking. All ANNIE components communicate exclusively via GATE’s document and annotation resources. See Chapter 6 for more details. Other CREOLE resources are described in Part III.
1.3.3 Additional Facilities in GATE Developer/Embedded [#]
Three other facilities in GATE deserve special mention:
- JAPE, a Java Annotation Patterns Engine, provides regular-expression based pattern/action rules over annotations – see Chapter 8.
- The ‘annotation diff’ tool in the development environment implements performance metrics such as precision and recall for comparing annotations. Typically a language analysis component developer will mark up some documents by hand and then use these along with the diff tool to automatically measure the performance of the components. See Chapter 10.
- GUK, the GATE Unicode Kit, fills in some of the gaps in the JDK’s10 support for Unicode, e.g. by adding input methods for various languages from Urdu to Chinese. See Section 3.11.2 for more details.
1.3.4 An Example [#]
This section gives a very brief example of a typical use of GATE to develop and deploy language processing capabilities in an application, and to generate quantitative results for scientific publication.
Let’s imagine that a developer called Fatima is building an email client11 for Cyberdyne Systems’ large corporate Intranet. In this application she would like to have a language processing system that automatically spots the names of people in the corporation and transforms them into mailto hyperlinks.
A little investigation shows that GATE’s existing components can be tailored to this purpose. Fatima starts up GATE Developer, and creates a new document containing some example emails. She then loads some processing resources that will do named-entity recognition (a tokeniser, gazetteer and semantic tagger), and creates an application to run these components on the document in sequence. Having processed the emails, she can see the results in one of several viewers for annotations.
The GATE components are a decent start, but they need to be altered to deal specially with people from Cyberdyne’s personnel database. Therefore Fatima creates new ‘cyber-’ versions of the gazetteer and semantic tagger resources, using the ‘bootstrap’ tool. This tool creates a directory structure on disk that has some Java stub code, a Makefile and an XML configuration file. After several hours struggling with badly written documentation, Fatima manages to compile the stubs and create a JAR file containing the new resources. She tells GATE Developer the URL of these files12, and the system then allows her to load them in the same way that she loaded the built-in resources earlier on.
Fatima then creates a second copy of the email document, and uses the annotation editing facilities to mark up the results that she would like to see her system producing. She saves this and the version that she ran GATE on into her serial datastore. From now on she can follow this routine:
- Run her application on the email test corpus.
- Check the performance of the system by running the ‘annotation diff’ tool to compare her manual results with the system’s results. This gives her both percentage accuracy figures and a graphical display of the differences between the machine and human outputs.
- Make edits to the code, pattern grammars or gazetteer lists in her resources, and recompile where necessary.
- Tell GATE Developer to re-initialise the resources.
- Go to 1.
To make the alterations that she requires, Fatima re-implements the ANNIE gazetteer so that it regenerates itself from the local personnel data. She then alters the pattern grammar in the semantic tagger to prioritise recognition of names from that source. This latter job involves learning the JAPE language (see Chapter 8), but as this is based on regular expressions it isn’t too difficult.
Eventually the system is running nicely, and her accuracy is 93% (there are still some problem cases, e.g. when people use nicknames, but the performance is good enough for production use). Now Fatima stops using GATE Developer and works instead on embedding the new components in her email application using GATE Embedded. This application is written in Java, so embedding is very easy13: the GATE JAR files are added to the project CLASSPATH, the new components are placed on a web server, and with a little code to do initialisation, loading of components and so on, the job is finished in half a day – the code to talk to GATE takes up only around 150 lines of the eventual application, most of which is just copied from the example in the sheffield.examples.StandAloneAnnie class.
Because Fatima is worried about Cyberdyne’s unethical policy of developing Skynet to help the large corporates of the West strengthen their strangle-hold over the World, she wants to get a job as an academic instead (so that her conscience will only have to cope with the torture of students, as opposed to humanity). She takes the accuracy measures that she has attained for her system and writes a paper for the Journal of Nasturtium Logarithm Incitement describing the approach used and the results obtained. Because she used GATE for development, she can cite the repeatability of her experiments and offer access to example binary versions of her software by putting them on an external web server.
And everybody lived happily ever after.
1.4 Some Evaluations [#]
This section contains an incomplete list of publications describing systems that used GATE in competitive quantitative evaluation programmes. These programmes have had a significant impact on the language processing field and the widespread presence of GATE is some measure of the maturity of the system and of our understanding of its likely performance on diverse text processing tasks.
- [Li et al. 07d]
- describes the performance of an SVM-based learning system in the NTCIR-6 Patent Retrieval Task. The system achieved the best result on two of three measures used in the task evaluation, namely the R-Precision and F-measure. The system obtained close to the best result on the remaining measure (A-Precision).
- [Saggion 07]
- describes a cross-source coreference resolution system based on semantic clustering. It uses GATE for information extraction and the SUMMA system to create summaries and semantic representations of documents. One system configuration ranked 4th in the Web People Search 2007 evaluation.
- [Saggion 06]
- describes a cross-lingual summarization system which uses SUMMA components and the Arabic plugin available in GATE to produce summaries in English from a mixture of English and Arabic documents.
- Open-Domain Question Answering:
- The University of Sheffield has a long history of research into open-domain question answering. GATE has formed the basis of much of this research resulting in systems which have ranked highly during independent evaluations since 1999. The first successful question answering system developed at the University of Sheffield was evaluated as part of TREC 8 and used the LaSIE information extraction system (the forerunner of ANNIE) which was distributed with GATE [Humphreys et al. 99]. Further research was reported in [Scott & Gaizauskas. 00], [Greenwood et al. 02], [Gaizauskas et al. 03], [Gaizauskas et al. 04] and [Gaizauskas et al. 05]. In 2004 the system was ranked 9th out of 28 participating groups.
- [Saggion 04]
- describes techniques for answering definition questions. The system uses definition patterns manually implemented in GATE as well as learned JAPE patterns induced from a corpus. In 2004, the system was ranked 4th in the TREC/QA evaluations.
- [Saggion & Gaizauskas 04b]
- describes a multidocument summarization system implemented using summarization components compatible with GATE (the SUMMA system). The system was ranked 2nd in the Document Understanding Evaluation programmes.
- [Maynard et al. 03e] and [Maynard et al. 03d]
- describe participation in the TIDES surprise language program. ANNIE was adapted to Cebuano with four person days of effort, and achieved an F-measure of 77.5%. Unfortunately, ours was the only system participating!
- [Maynard et al. 02b] and [Maynard et al. 03b]
- describe results obtained on systems designed for the ACE task (Automatic Content Extraction). Although a comparison to other participating systems cannot be revealed due to the stipulations of ACE, results show 82%-86% precision and recall.
- [Humphreys et al. 98]
- describes the LaSIE-II system used in MUC-7.
- [Gaizauskas et al. 95]
- describes the LaSIE-II system used in MUC-6.
1.5 Recent Changes [#]
This section details recent changes made to GATE. Appendix A provides a complete change log.
1.5.1 Version 7.0 (February 2012) [#]
Major new features
The CREOLE Plugin Manager has been completely re-written and now includes support for installing new plugins from remote update sites. See sections 3.6 and 12.3.5 for more details. In addition, plugins can now contribute additional “ready-made applications” to the GATE Developer menus alongside the standard applications (ANNIE, etc.). Details can be found in section 12.3.4.
A new plugin named JAPE_Plus has been added. It contains a new JAPE execution engine that includes various optimisations and should be significantly faster than the standard engine. JAPE_Plus has not yet been comprehensively tested, so it should be considered beta software, and used with caution. See Section 8.11 for more details.
A new Java-based launcher has been implemented which now replaces the use of Apache ANT for starting-up GATE Developer. The GATE Developer application now behaves in a more natural way in dock-based desktop environments such as Mac OS X and Ubuntu Unity.
Improved the support for processing biomedical text by adding new PRs to incorporate the following tools: AbGene, the NormaGene tagger, the GENIA sentence splitter, MutationFinder and the Penn BioTagger (contains a tokenizer and three taggers for gene, malignancy and variation). For full details of these new resources see section 16.1.
The Flexible Gazetteer PR has been rewritten to provide a better and faster implementation. The two parameters inputAnnotationSetName and outputAnnotationSetName have been renamed to inputASName and outputASName, however old applications with the old parameters should still work. Please see Section 13.6 for more details.
Removal of deprecated functionality
Various components were removed in this release as they have been unsupported and deprecated in previous releases:
- the GATE Unicode Kit (GUK), which has been superseded by improved native support for localisation in the various target operating systems. If you still require GUK it is available as a separate software project at http://gate.svn.sourceforge.net/viewvc/gate/guk/trunk.
- the database-backed datastore implementation.
- the plugins Jape_Compiler (superseded by JAPE_Plus) and Ontology_OWLIM2.
In addition the Web_Search_Google, Web_Search_Yahoo and Web_Translate_Google plugins have been removed as the underlying web services on which they depend are no longer available. Documentation for obsolete plugins can be found in appendix C, and if you require any of them for your application please see plugins/Obsolete/README.TXT in the GATE Developer distribution.
Other enhancements and bug fixes
CREOLE plugins can now use Apache Ivy to include third-party dependencies. See section 4.7.4 for details.
The Default ANNIE Gazetteer now allows a user to specify different annotation types to be used for annotating entries from different lists. For example, a user may want to find city names mentioned in a gazetteer list (e.g. city.lst) and annotate the matching strings as City. Please see section 6.3 for more details.
The Segment Processing PR has two additional run-time parameters called segmentAnnotationFeatureName and segmentAnnotationFeatureValue. These features allow users to specify a constraint on feature name and feature value. If user has provided values for these parameters, only the annotations with the specified feature name and feature value are processed with the Segment Processing PR. Also, the parameter controller has been renamed to analyser which means the Segment Processing PR can now also run an individual PR on the specified segments14. See 19.2.10 for more information on section-by-section processing.
The Hash Gazetteer (section 13.5) now properly supports the caseSensitive parameter (previously the parameter could be set but had no effect).
The Document Reset PR (Section 6.1) now defaults to keeping the Key set as well as Original markups. This makes working with pre-annotated gold standard document less dangerous (assuming you put the gold standard annotations in a set called Key).
Updated Stanford Parser plugin (see Section 17.4) to version 1.6.8.
The TextCat based Language Identification PR now supports generating new language fingerprints. See section 15.1 for full details.
Added support for reading XCAS and XMI-format documents created by UIMA. See section 5.5.9 for details.
Various improvements to the GATE Developer GUI:
- added support in the document editor to switch the principal text orientation, to better support documents written in right-to-left languages such as Arabic, Hebrew or Urdu (section 3.2).
- added new mouse shortcuts to the Annotation Stack view in the document editor to speed up the curation process (section 3.4.3).
- the document editor layout is now saved to the user preferences file, gate.xml. It means that you can give this file to a new user so s/he will have a preconfigured document editor (section 3.2).
- the script behind an instance of the Groovy Scripting PR (section 7.16.2) can now be edited from within GATE Developer through a new visual resource which supports syntax highlighting.
The rule and phase names are now accessible in a JAPE Java RHS by the ruleName() and phaseName() methods and the name of the JAPE processing resource executing the JAPE transducer is accessible through the action context getPRName() method. See section 8.6.5.
1.6 Further Reading [#]
Lots of documentation lives on the GATE web site, including:
- GATE online tutorials;
- the main system documentation tree;
- JavaDoc API documentation;
- HTML of the source code;
- comprehensive list of GATE plugins.
For more details about Sheffield University’s work in human language processing see the NLP group pages or A Definition and Short History of Language Engineering ([Cunningham 99a]). For more details about Information Extraction see IE, a User Guide or the GATE IE pages.
A list of publications on GATE and projects that use it (some of which are available on-line from http://gate.ac.uk/gate/doc/papers.html):
2010
- [Bontcheva et al. 10]
- describes the Teamware web-based collaborative annotation environment, emphasising the different roles that users play in the corpus annotation process.
- [Damljanovic 10]
- presents the use of GATE in the development of controlled natural language interfaces. There is other related work by Damljanovic, Agatonovic, and Cunningham on using GATE to build natural language interfaces for quering ontologies.
- [Aswani & Gaizauskas 10]
- discusses the use of GATE to process South Asian languages (Hindi and Gujarati).
2009
- [Saggion & Funk 09]
- focuses in detail on the use of GATE for mining opinions and facts for business intelligence gathering from web content.
- [Aswani & Gaizauskas 09]
- presents in more detail the text alignment component of GATE.
- [Bontcheva et al. 09]
- is the ‘Human Language Technologies’ chapter of ‘Semantic Knowledge Management’ (John Davies, Marko Grobelnik and Dunja MladeniÄĞ eds.)
- [Damljanovic et al. 09]
- discusses the use of semantic annotation for software engineering, as part of the TAO research project.
- [Laclavik & Maynard 09]
- reviews the current state of the art in email processing and communication research, focusing on the roles played by email in information management, and commercial and research efforts to integrate a semantic-based approach to email.
- [Li et al. 09]
- investigates two techniques for making SVMs more suitable for language learning tasks. Firstly, an SVM with uneven margins (SVMUM) is proposed to deal with the problem of imbalanced training data. Secondly, SVM active learning is employed in order to alleviate the difficulty in obtaining labelled training data. The algorithms are presented and evaluated on several Information Extraction (IE) tasks.
2008
- [Agatonovic et al. 08]
- presents our approach to automatic patent enrichment, tested in large-scale, parallel experiments on USPTO and EPO documents.
- [Damljanovic et al. 08]
- presents Question-based Interface to Ontologies (QuestIO) - a tool for querying ontologies using unconstrained language-based queries.
- [Damljanovic & Bontcheva 08]
- presents a semantic-based prototype that is made for an open-source software engineering project with the goal of exploring methods for assisting open-source developers and software users to learn and maintain the system without major effort.
- [Della Valle et al. 08]
- presents ServiceFinder.
- [Li & Cunningham 08]
- describes our SVM-based system and several techniques we developed successfully to adapt SVM for the specific features of the F-term patent classification task.
- [Li & Bontcheva 08]
- reviews the recent developments in applying geometric and quantum mechanics methods for information retrieval and natural language processing.
- [Maynard 08]
- investigates the state of the art in automatic textual annotation tools, and examines the extent to which they are ready for use in the real world.
- [Maynard et al. 08a]
- discusses methods of measuring the performance of ontology-based information extraction systems, focusing particularly on the Balanced Distance Metric (BDM), a new metric we have proposed which aims to take into account the more flexible nature of ontologically-based applications.
- [Maynard et al. 08b]
- investigates NLP techniques for ontology population, using a combination of rule-based approaches and machine learning.
- [Tablan et al. 08]
- presents the QuestIO system âĂŞ a natural language interface for accessing structured information, that is domain independent and easy to use without training.
2007
- [Funk et al. 07a]
- describes an ontologically based approach to multi-source, multilingual information extraction.
- [Funk et al. 07b]
- presents a controlled language for ontology editing and a software implementation, based partly on standard NLP tools, for processing that language and manipulating an ontology.
- [Maynard et al. 07a]
- proposes a methodology to capture (1) the evolution of metadata induced by changes to the ontologies, and (2) the evolution of the ontology induced by changes to the underlying metadata.
- [Maynard et al. 07b]
- describes the development of a system for content mining using domain ontologies, which enables the extraction of relevant information to be fed into models for analysis of financial and operational risk and other business intelligence applications such as company intelligence, by means of the XBRL standard.
- [Saggion 07]
- describes experiments for the cross-document coreference task in SemEval 2007. Our cross-document coreference system uses an in-house agglomerative clustering implementation to group documents referring to the same entity.
- [Saggion et al. 07]
- describes the application of ontology-based extraction and merging in the context of a practical e-business application for the EU MUSING Project where the goal is to gather international company intelligence and country/region information.
- [Li et al. 07a]
- introduces a hierarchical learning approach for IE, which uses the target ontology as an essential part of the extraction process, by taking into account the relations between concepts.
- [Li et al. 07b]
- proposes some new evaluation measures based on relations among classification labels, which can be seen as the label relation sensitive version of important measures such as averaged precision and F-measure, and presents the results of applying the new evaluation measures to all submitted runs for the NTCIR-6 F-term patent classification task.
- [Li et al. 07c]
- describes the algorithms and linguistic features used in our participating system for the opinion analysis pilot task at NTCIR-6.
- [Li et al. 07d]
- describes our SVM-based system and the techniques we used to adapt the approach for the specifics of the F-term patent classification subtask at NTCIR-6 Patent Retrieval Task.
- [Li & Shawe-Taylor 07]
- studies Japanese-English cross-language patent retrieval using Kernel Canonical Correlation Analysis (KCCA), a method of correlating linear relationships between two variables in kernel defined feature spaces.
2006
- [Aswani et al. 06]
- (Proceedings of the 5th International Semantic Web Conference (ISWC2006)) In this paper the problem of disambiguating author instances in ontology is addressed. We describe a web-based approach that uses various features such as publication titles, abstract, initials and co-authorship information.
- [Bontcheva et al. 06a]
- ‘Semantic Annotation and Human Language Technology’, contribution to ‘Semantic Web Technology: Trends and Research’ (Davies, Studer and Warren, eds.)
- [Bontcheva et al. 06b]
- ‘Semantic Information Access’, contribution to ‘Semantic Web Technology: Trends and Research’ (Davies, Studer and Warren, eds.)
- [Bontcheva & Sabou 06]
- presents an ontology learning approach that 1) exploits a range of information sources associated with software projects and 2) relies on techniques that are portable across application domains.
- [Davis et al. 06]
- describes work in progress concerning the application of Controlled Language Information Extraction - CLIE to a Personal Semantic Wiki - Semper- Wiki, the goal being to permit users who have no specialist knowledge in ontology tools or languages to semi-automatically annotate their respective personal Wiki pages.
- [Li & Shawe-Taylor 06]
- studies a machine learning algorithm based on KCCA for cross-language information retrieval. The algorithm is applied to Japanese-English cross-language information retrieval.
- [Maynard et al. 06]
- discusses existing evaluation metrics, and proposes a new method for evaluating the ontology population task, which is general enough to be used in a variety of situation, yet more precise than many current metrics.
- [Tablan et al. 06b]
- describes an approach that allows users to create and edit ontologies simply by using a restricted version of the English language. The controlled language described is based on an open vocabulary and a restricted set of grammatical constructs.
- [Tablan et al. 06a]
- describes the creation of linguistic analysis and corpus search tools for Sumerian, as part of the development of the ETCSL.
- [Wang et al. 06]
- proposes an SVM based approach to hierarchical relation extraction, using features derived automatically from a number of GATE-based open-source language processing tools.
2005
- [Aswani et al. 05]
- (Proceedings of Fifth International Conference on Recent Advances in Natural Language Processing (RANLP2005)) It is a full-featured annotation indexing and search engine, developed as a part of the GATE. It is powered with Apache Lucene technology and indexes a variety of documents supported by the GATE.
- [Bontcheva 05]
- presents the ONTOSUM system which uses Natural Language Generation (NLG) techniques to produce textual summaries from Semantic Web ontologies.
- [Cunningham 05]
- is an overview of the field of Information Extraction for the 2nd Edition of the Encyclopaedia of Language and Linguistics.
- [Cunningham & Bontcheva 05]
- is an overview of the field of Software Architecture for Language Engineering for the 2nd Edition of the Encyclopaedia of Language and Linguistics.
- [Dowman et al. 05a]
- (Euro Interactive Television Conference Paper) A system which can use material from the Internet to augment television news broadcasts.
- [Dowman et al. 05b]
- (World Wide Web Conference Paper) The Web is used to assist the annotation and indexing of broadcast news.
- [Dowman et al. 05c]
- (Second European Semantic Web Conference Paper) A system that semantically annotates television news broadcasts using news websites as a resource to aid in the annotation process.
- [Li et al. 05a]
- (Proceedings of Sheffield Machine Learning Workshop) describe an SVM based IE system which uses the SVM with uneven margins as learning component and the GATE as NLP processing module.
- [Li et al. 05b]
- (Proceedings of Ninth Conference on Computational Natural Language Learning (CoNLL-2005)) uses the uneven margins versions of two popular learning algorithms SVM and Perceptron for IE to deal with the imbalanced classification problems derived from IE.
- [Li et al. 05c]
- (Proceedings of Fourth SIGHAN Workshop on Chinese Language processing (Sighan-05)) a system for Chinese word segmentation based on Perceptron learning, a simple, fast and effective learning algorithm.
- [Polajnar et al. 05]
- (University of Sheffield-Research Memorandum CS-05-10) User-Friendly Ontology Authoring Using a Controlled Language.
- [Saggion & Gaizauskas 05]
- describes experiments on content selection for producing biographical summaries from multiple documents.
- [Ursu et al. 05]
- (Proceedings of the 2nd European Workshop on the Integration of Knowledge, Semantic and Digital Media Technologies (EWIMT 2005))Digital Media Preservation and Access through Semantically Enhanced Web-Annotation.
- [Wang et al. 05]
- (Proceedings of the 2005 IEEE/WIC/ACM International Conference on Web Intelligence (WI 2005)) Extracting a Domain Ontology from Linguistic Resource Based on Relatedness Measurements.
2004
- [Bontcheva 04]
- (LREC 2004) describes lexical and ontological resources in GATE used for Natural Language Generation.
- [Bontcheva et al. 04]
- (JNLE) discusses developments in GATE in the early naughties.
- [Cunningham & Scott 04a]
- (JNLE) is the introduction to the above collection.
- [Cunningham & Scott 04b]
- (JNLE) is a collection of papers covering many important areas of Software Architecture for Language Engineering.
- [Dimitrov et al. 04]
- (Anaphora Processing) gives a lightweight method for named entity coreference resolution.
- [Li et al. 04]
- (Machine Learning Workshop 2004) describes an SVM based learning algorithm for IE using GATE.
- [Maynard et al. 04a]
- (LREC 2004) presents algorithms for the automatic induction of gazetteer lists from multi-language data.
- [Maynard et al. 04b]
- (ESWS 2004) discusses ontology-based IE in the hTechSight project.
- [Maynard et al. 04c]
- (AIMSA 2004) presents automatic creation and monitoring of semantic metadata in a dynamic knowledge portal.
- [Saggion & Gaizauskas 04a]
- describes an approach to mining definitions.
- [Saggion & Gaizauskas 04b]
- describes a sentence extraction system that produces two sorts of multi-document summaries; a general-purpose summary of a cluster of related documents and an entity-based summary of documents related to a particular person.
- [Wood et al. 04]
- (NLDB 2004) looks at ontology-based IE from parallel texts.
2003
- [Bontcheva et al. 03]
- (NLPXML-2003) looks at GATE for the semantic web.
- [Cunningham et al. 03]
- (Corpus Linguistics 2003) describes GATE as a tool for collaborative corpus annotation.
- [Kiryakov 03]
- (Technical Report) discusses semantic web technology in the context of multimedia indexing and search.
- [Manov et al. 03]
- (HLT-NAACL 2003) describes experiments with geographic knowledge for IE.
- [Maynard et al. 03a]
- (EACL 2003) looks at the distinction between information and content extraction.
- [Maynard et al. 03c]
- (Recent Advances in Natural Language Processing 2003) looks at semantics and named-entity extraction.
- [Maynard et al. 03e]
- (ACL Workshop 2003) describes NE extraction without training data on a language you don’t speak (!).
- [Saggion et al. 03a]
- (EACL 2003) discusses robust, generic and query-based summarisation.
- [Saggion et al. 03b]
- (Data and Knowledge Engineering) discusses multimedia indexing and search from multisource multilingual data.
- [Saggion et al. 03c]
- (EACL 2003) discusses event co-reference in the MUMIS project.
- [Tablan et al. 03]
- (HLT-NAACL 2003) presents the OLLIE on-line learning for IE system.
- [Wood et al. 03]
- (Recent Advances in Natural Language Processing 2003) discusses using parallel texts to improve IE recall.
2002
- [Baker et al. 02]
- (LREC 2002) report results from the EMILLE Indic languages corpus collection and processing project.
- [Bontcheva et al. 02a]
- (ACl 2002 Workshop) describes how GATE can be used as an environment for teaching NLP, with examples of and ideas for future student projects developed within GATE.
- [Bontcheva et al. 02b]
- (NLIS 2002) discusses how GATE can be used to create HLT modules for use in information systems.
- [Bontcheva et al. 02c], [Dimitrov 02a] and [Dimitrov 02b]
- (TALN 2002, DAARC 2002, MSc thesis) describe the shallow named entity coreference modules in GATE: the orthomatcher which resolves pronominal coreference, and the pronoun resolution module.
- [Cunningham 02]
- (Computers and the Humanities) describes the philosophy and motivation behind the system, describes GATE version 1 and how well it lived up to its design brief.
- [Cunningham et al. 02]
- (ACL 2002) describes the GATE framework and graphical development environment as a tool for robust NLP applications.
- [Dimitrov 02a, Dimitrov et al. 02]
- (DAARC 2002, MSc thesis) discuss lightweight coreference methods.
- [Lal 02]
- (Master Thesis) looks at text summarisation using GATE.
- [Lal & Ruger 02]
- (ACL 2002) looks at text summarisation using GATE.
- [Maynard et al. 02a]
- (ACL 2002 Summarisation Workshop) describes using GATE to build a portable IE-based summarisation system in the domain of health and safety.
- [Maynard et al. 02c]
- (AIMSA 2002) describes the adaptation of the core ANNIE modules within GATE to the ACE (Automatic Content Extraction) tasks.
- [Maynard et al. 02d]
- (Nordic Language Technology) describes various Named Entity recognition projects developed at Sheffield using GATE.
- [Maynard et al. 02e]
- (JNLE) describes robustness and predictability in LE systems, and presents GATE as an example of a system which contributes to robustness and to low overhead systems development.
- [Pastra et al. 02]
- (LREC 2002) discusses the feasibility of grammar reuse in applications using ANNIE modules.
- [Saggion et al. 02b] and [Saggion et al. 02a]
- (LREC 2002, SPLPT 2002) describes how ANNIE modules have been adapted to extract information for indexing multimedia material.
- [Tablan et al. 02]
- (LREC 2002) describes GATE’s enhanced Unicode support.
Older than 2002
- [Maynard et al. 01]
- (RANLP 2001) discusses a project using ANNIE for named-entity recognition across wide varieties of text type and genre.
- [Bontcheva et al. 00] and [Brugman et al. 99]
- (COLING 2000, technical report) describe a prototype of GATE version 2 that integrated with the EUDICO multimedia markup tool from the Max Planck Institute.
- [Cunningham 00]
- (PhD thesis) defines the field of Software Architecture for Language Engineering, reviews previous work in the area, presents a requirements analysis for such systems (which was used as the basis for designing GATE versions 2 and 3), and evaluates the strengths and weaknesses of GATE version 1.
- [Cunningham et al. 00a], [Cunningham et al. 98a] and [Peters et al. 98]
- (OntoLex 2000, LREC 1998) presents GATE’s model of Language Resources, their access and distribution.
- [Cunningham et al. 00b]
- (LREC 2000) taxonomises Language Engineering components and discusses the requirements analysis for GATE version 2.
- [Cunningham et al. 00c] and [Cunningham et al. 99]
- (COLING 2000, AISB 1999) summarise experiences with GATE version 1.
- [Cunningham et al. 00d] and [Cunningham 99b]
- (technical reports) document early versions of JAPE (superseded by the present document).
- [Gambäck & Olsson 00]
- (LREC 2000) discusses experiences in the Svensk project, which used GATE version 1 to develop a reusable toolbox of Swedish language processing components.
- [Maynard et al. 00]
- (technical report) surveys users of GATE up to mid-2000.
- [McEnery et al. 00]
- (Vivek) presents the EMILLE project in the context of which GATE’s Unicode support for Indic languages has been developed.
- [Cunningham 99a]
- (JNLE) reviewed and synthesised definitions of Language Engineering.
- [Stevenson et al. 98] and [Cunningham et al. 98b]
- (ECAI 1998, NeMLaP 1998) report work on implementing a word sense tagger in GATE version 1.
- [Cunningham et al. 97b]
- (ANLP 1997) presents motivation for GATE and GATE-like infrastructural systems for Language Engineering.
- [Cunningham et al. 96a]
- (manual) was the guide to developing CREOLE components for GATE version 1.
- [Cunningham et al. 96b]
- (TIPSTER) discusses a selection of projects in Sheffield using GATE version 1 and the TIPSTER architecture it implemented.
- [Cunningham et al. 96c, Cunningham et al. 96d, Cunningham et al. 95]
- (COLING 1996, AISB Workshop 1996, technical report) report early work on GATE version 1.
- [Gaizauskas et al. 96a]
- (manual) was the user guide for GATE version 1.
- [Gaizauskas et al. 96b, Cunningham et al. 97a, Cunningham et al. 96e]
- (ICTAI 1996, TIPSTER 1997, NeMLaP 1996) report work on GATE version 1.
- [Humphreys et al. 96]
- (manual) describes the language processing components distributed with GATE version 1.
- [Cunningham 94, Cunningham et al. 94]
- (NeMLaP 1994, technical report) argue that software engineering issues such as reuse, and framework construction, are important for language processing R&D.
1These were, at least, our ideals; of course we didn’t completely live up to them…
2If you’ve read the overview at http://gate.ac.uk/overview.html, you may prefer to skip to Section 1.1.
3Rumours that we’re planning to send several of the development team to Antarctica on one-way tickets are false, libellous and wishful thinking.
4Our philosophy is reuse not reinvention, so we integrate and interoperate with other systems e.g.: LingPipe, OpenNLP, UIMA, and many more specific tools.
5This is the figure for direct Sheffield-based investment only and therefore an underestimate.
6GATE Developer and GATE Embedded are bundled, and in older distributions were referred to just as ‘GATE’.
7Follow the ‘support’ link from http://gate.ac.uk/ to subscribe to the mailing list.
8The terms ‘resource’ and ‘component’ are synonymous in this context. ‘Resource’ is used instead of just ‘component’ because it is a common term in the literature of the field: cf. the Language Resources and Evaluation conference series [LREC-1 98, LREC-2 00].
9The main JAR file (gate.jar) supplies the framework. Built-in resources and various 3rd-party libraries are supplied as separate JARs; for example (guk.jar, the GATE Unicode Kit.) contains Unicode support (e.g. additional input methods for languages not currently supported by the JDK). They are separate because the latter has to be a Java extension with a privileged security profile.
10JDK: Java Development Kit, Sun Microsystem’s Java implementation. Unicode support is being actively improved by Sun, but at the time of writing many languages are still unsupported. In fact, Unicode itself doesn’t support all languages, e.g. Sylheti; hopefully this will change in time.
11Perhaps because Outlook Express trashed her mail folder again, or because she got tired of Microsoft-specific viruses and hadn’t heard of Gmail or Thunderbird.
12While developing, she uses a file:/… URL; for deployment she can put them on a web server.
13Languages other than Java require an additional interface layer, such as JNI, the Java Native Interface, which is in C.
14Existing saved applications using the controller parameter will still work provided the controller in question implements the LanguageAnalyser interface. The CorpusController implementations supplied as standard with GATE all implement this interface.
