Chapter 7
GATE Embedded [#]
7.1 Quick Start with GATE Embedded [#]
Embedding GATE-based language processing in other applications using GATE Embedded (the GATE API) is straightforward:
-
add the GATE libraries to your application’s classpath.
-
if you use a build tool with dependency management, such as Maven or Gradle, add a dependency on the right version of uk.ac.gate:gate-core – this is the recommended way to build against the GATE APIs.
-
if you can’t use a dependency manager, you can instead add all the JAR files from the lib directory of a GATE installation to your compile classpath in your build tool.
-
-
initialise GATE with gate.Gate.init();
-
program to the framework API.
For example, this code will create the default ANNIE extraction system, the same as the “load ANNIE” button in GATE Developer:
2 Gate.init();
3
4 // load the ANNIE plugin
5 Plugin anniePlugin = new Plugin.Maven(
6 "uk.ac.gate.plugins", "annie", gate.Main.version);
7 Gate.getCreoleRegister().registerPlugin(anniePlugin);
8
9 // load ANNIE application from inside the plugin
10 SerialAnalyserController controller = (SerialAnalyserController)
11 PersistenceManager.loadObjectFromUrl(new ResourceReference(
12 anniePlugin, "resources/" + ANNIEConstants.DEFAULT_FILE)
13 .toURL());
If you want to use resources from any plugins, you need to load the plugins before calling createResource:
2
3 // need Tools plugin for the Morphological analyser
4 Gate.getCreoleRegister().registerPlugin(new Plugin.Maven(
5 "uk.ac.gate.plugins", "tools", gate.Main.version));
6
7 ...
8
9 ProcessingResource morpher = (ProcessingResource)
10 Factory.createResource("gate.creole.morph.Morph");
Instead of creating your processing resources individually using the Factory, you can create your application in GATE Developer, save it using the ‘save application state’ option (see Section 3.9.3), and then load the saved state from your code. This will automatically reload any plugins that were loaded when the state was saved, you do not need to load them manually.
2
3 CorpusController controller = (CorpusController)
4 PersistenceManager.loadObjectFromFile(new File("savedState.xgapp"));
There are many examples of using GATE Embedded available at:
http://gate.ac.uk/wiki/code-repository/.
See Section 2.3 for details of the system properties GATE uses to find its configuration files.
7.2 Resource Management in GATE Embedded [#]
As outlined earlier, GATE defines three different types of resources:
-
Language Resources
-
: (LRs) entities that hold linguistic data.
-
Processing Resources
-
: (PRs) entities that process data.
-
Visual Resources
-
: (VRs) components used for building graphical interfaces.
These resources are collectively named CREOLE1 resources.
All CREOLE resources have some associated meta-data in the form of annotations on the resource class and some of its methods. The most important role of that meta-data is to specify the set of parameters that a resource understands, which of them are required and which not, if they have default values and what those are. See Section 4.7 for full details of the configuration mechanism.
All resource types have creation-time parameters that are used during the initialisation phase. Processing Resources also have run-time parameters that get used during execution (see Section 7.5 for more details).
Controllers are used to define GATE applications and have the role of controlling the execution flow (see Section 7.6 for more details).
This section describes how to create and delete CREOLE resources as objects in a running Java virtual machine. This process involves using GATE’s Factory class2, and, in the case of LRs, may also involve using a DataStore.
CREOLE resources are Java Beans; creation of a resource object involves using a default constructor, then setting parameters on the bean, then calling an init() method. The Factory takes care of all this, makes sure that the GATE Developer GUI is told about what is happening (when GUI components exist at runtime), and also takes care of restoring LRs from DataStores. A programmer using GATE Embedded should never call the constructor of a resource: always use the Factory!
Creating a resource involves providing the following information:
-
fully qualified class name for the resource. This is the only required value. For all the rest, defaults will be used if actual values are not provided.
-
values for the creation time parameters.†
-
initial values for resource features.† For an explanation on features see Section 7.4.2.
-
a name for the new resource;
† Parameters and features need to be provided in the form of a GATE Feature Map which is essentially a java Map (java.util.Map) implementation, see Section 7.4.2 for more details on Feature Maps.
Creating a resource via the Factory involves passing values for any create-time parameters that require setting to the Factory’s createResource method. If no parameters are passed, the defaults are used. So, for example, the following code creates a default ANNIE part-of-speech tagger:
2 "uk.ac.gate.plugins", "annie", gate.Main.version));
3FeatureMap params = Factory.newFeatureMap(); //empty map:default params
4ProcessingResource tagger = (ProcessingResource)
5 Factory.createResource("gate.creole.POSTagger", params);
Note that if the resource created here had any parameters that were both mandatory and had no default value, the createResource call would throw an exception. In the case of the POS tagger, all the required parameters have default values so no params need to be passed in.
When creating a Document, however, the URL of the source for the document must be provided3. For example:
2FeatureMap params = Factory.newFeatureMap();
3params.put("sourceUrl", u);
4Document doc = (Document)
5 Factory.createResource("gate.corpora.DocumentImpl", params);
Note that the document created here is transient: when you quit the JVM the document will no longer exist. If you want the document to be persistent, you need to store it in a DataStore (see Section 7.4.5).
Apart from createResource() methods with different signatures, Factory also provides some shortcuts for common operations, listed in table 7.1.
Method | Purpose |
newFeatureMap() | Creates a new Feature Map (as used in the example above). |
newDocument(String content) | Creates a new GATE Document starting from a String value that will be used to generate the document content. |
newDocument(URL sourceUrl) | Creates a new GATE Document using the text pointed by an URL to generate the document content. |
newDocument(URL sourceUrl, String encoding) | Same as above but allows the specification of an encoding to be used while downloading the document content. |
newCorpus(String name) | creates a new GATE Corpus with a specified name. |
GATE maintains various data structures that allow the retrieval of loaded resources. When a resource is no longer required, it needs to be removed from those structures in order to remove all references to it, thus making it a candidate for garbage collection. This is achieved using the deleteResource(Resource res) method on Factory.
Simply removing all references to a resource from the user code will NOT be enough to make the resource collect-able. Not calling Factory.deleteResource() will lead to memory leaks!
7.3 Using CREOLE Plugins [#]
As shown in the examples above, in order to use a CREOLE resource the relevant CREOLE plugin must be loaded. Processing Resources, Visual Resources and Language Resources other than Document, Corpus and DataStore all require that the appropriate plugin is first loaded. When using Document, Corpus or DataStore, you do not need to first load a plugin. The following API calls listed in table 7.2 are relevant to working with CREOLE plugins.
| Class gate.Gate
| |
Method | Purpose |
public static void addKnownPlugin(Plugin plugin) | adds the plugin to the list of known plugins. |
public static void removeKnownPlugin(Plugin plugin) | tells the system to ‘forget’ about one previously known directory. If the specified plugin was loaded, it will be unloaded as well - i.e. all the metadata relating to resources defined by this plugin will be removed from memory. |
public static void addAutoloadPlugin(Plugin plugin) | adds a new plugin to the list of plugins that are loaded automatically at start-up. |
public static void removeAutoloadPlugin(Plugin plugin) | tells the system to remove a plugin from the list of plugins that are loaded automatically at system start-up. This will be reflected in the user’s configuration data file. |
| Class gate.CreoleRegister
| |
public void registerPlugin(Plugin plugin) | loads a new CREOLE plugin. The new plugin is added to the list of known plugins if not already there. |
public void unregisterPlugin(Plugin plugin) | unloads a loaded CREOLE plugin. |
There are several different subclasses of Plugin that can be passed to these methods. The most common one is Plugin.Maven, as seen in the examples above, which is a plugin that is a single JAR file specified via its group:artifact:version “coordinates”, and which is downloaded from a Maven repository at runtime by GATE the first time the plugin is loaded. The vast majority of standard GATE plugins are of this type. To load version 8.5 of the ANNIE plugin, for example, you would use:
2 "uk.ac.gate.plugins", "annie", "8.5"));
By default GATE looks in the Central Repository and in the GATE repository (http://repo.gate.ac.uk/content/groups/public/, where we deploy snapshot builds of the standard plugins), plus any repositories declared in active profiles in the normal Maven settings.xml file. Mirror and proxy settings from this file are also respected.
In addition to Maven plugins, GATE still supports the style of plugins used in GATE version 8.4.1 and earlier where the plugin is a directory on disk which contains a creole.xml configuration file and optionally one or more JAR files containing the compiled classes of the plugin’s CREOLE resources. These plugins are represented by the class Plugin.Directory, with a URL pointing to the directory that contains the creole.xml file:
2 new URL("file:/home/example/my-plugins/FishCounter/"));
Finally, if you are writing a GATE Embedded application and have a single resource class that will only be used from your embedded code (and so does not need to be distributed as a complete plugin), and all the configuration for that resource is provided as Java annotations on the class, then it is possible to register the class as a special type of Plugin called a “component”:
Note that components cannot be registered this way in the developer GUI, and cannot be included in saved application states (see section 7.9 below).
7.4 Language Resources [#]
This section describes the implementation of documents and corpora in GATE.
7.4.1 GATE Documents
Documents are modelled as content plus annotations (see Section 7.4.4) plus features (see Section 7.4.2).
The content of a document can be any implementation of the gate.DocumentContent interface; the features are <attribute, value> pairs stored a Feature Map. Attributes are String values while the values can be any Java object.
The annotations are grouped in sets (see section 7.4.3). A document has a default (anonymous) annotations set and any number of named annotations sets.
Documents are defined by the gate.Document interface and there is also a provided implementation:
-
: transient document. Can be stored persistently through Java serialisation.
Main Document functions are presented in table 7.3.
| Content Manipulation
| |
Method | Purpose |
DocumentContent getContent() | Gets the Document content. |
void edit(Long start, Long end, DocumentContent replacement) | Modifies the Document content. |
void setContent(DocumentContent newContent) | Replaces the entire content. |
| Annotations Manipulation
| |
Method | Purpose |
public AnnotationSet getAnnotations() | Returns the default annotation set. |
public AnnotationSet getAnnotations(String name) | Returns a named annotation set. |
public Map getNamedAnnotationSets() | Returns all the named annotation sets. |
void removeAnnotationSet(String name) | Removes a named annotation set. |
| Input Output
| |
String toXml() | Serialises the Document in XML format. |
String toXml(Set aSourceAnnotationSet, boolean includeFeatures) | Generates XML from a set of annotations only, trying to preserve the original format of the file used to create the document. |
7.4.2 Feature Maps [#]
All CREOLE resources as well as the Controllers and the annotations can have attached meta-data in the form of Feature Maps.
A Feature Map is a Java Map (i.e. it implements the java.util.Map interface) and holds <attribute-name, attribute-value> pairs. The attribute names are Strings while the values can be any Java Objects.
The use of non-Serialisable objects as values is strongly discouraged.
Feature Maps are created using the gate.Factory.newFeatureMap() method.
The actual implementation for FeatureMaps is provided by the gate.util.SimpleFeatureMapImpl class.
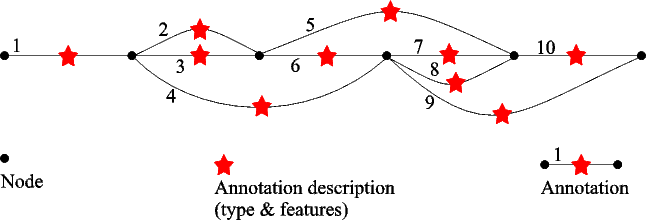
Objects that have features in GATE implement the gate.util.FeatureBearer interface which has only the two accessor methods for the object features: FeatureMap getFeatures() and void setFeatures(FeatureMap features).
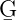 etting a particular feature from an object
etting a particular feature from an object
7.4.3 Annotation Sets [#]
A GATE document can have one or more annotation layers — an anonymous one, (also called default), and as many named ones as necessary.
An annotation layer is organised as a Directed Acyclic Graph (DAG) on which the nodes are particular locations —anchors— in the document content and the arcs are made out of annotations reaching from the location indicated by the start node to the one pointed by the end node (see Figure 7.1 for an illustration). Because of the graph metaphor, the annotation layers are also called annotation graphs. In terms of Java objects, the annotation layers are represented using the Set paradigm as defined by the collections library and they are hence named annotation sets. The terms of annotation layer, graph and set are interchangeable and refer to the same concept when used in this book.
An annotation set holds a number of annotations and maintains a series of indices in order to provide fast access to the contained annotations.
The GATE Annotation Sets are defined by the gate.AnnotationSet interface and there is a default implementation provided:
-
annotation set implementation used by transient documents.
The annotation sets are created by the document as required. The first time a particular annotation set is requested from a document it will be transparently created if it doesn’t exist.
Tables 7.4 and 7.5 list the most used Annotation Set functions.
| Annotations Manipulation
| |
Method | Purpose |
Integer add(Long start, Long end, String type, FeatureMap features) | Creates a new annotation between two offsets, adds it to this set and returns its id. |
Integer add(Node start, Node end, String type, FeatureMap features) | Creates a new annotation between two nodes, adds it to this set and returns its id. |
boolean remove(Object o) | Removes an annotation from this set. |
| Nodes
| |
Method | Purpose |
Node firstNode() | Gets the node with the smallest offset. |
Node lastNode() | Gets the node with the largest offset. |
Node nextNode(Node node) | Get the first node that is relevant for this annotation set and which has the offset larger than the one of the node provided. |
| Set implementation
| |
Iterator iterator() |
|
int size() |
|
| Searching
| |
AnnotationSet get(Long offset) | Select annotations by offset. This returns the set of annotations whose start node is the least such that it is greater than or equal to offset. If a positional index doesn’t exist it is created. If there are no nodes at or beyond the offset parameter then it will return null. |
AnnotationSet get(Long startOffset, Long endOffset) | Select annotations by offset. This returns the set of annotations that overlap totally or partially with the interval defined by the two provided offsets. The result will include all the annotations that either:
|
AnnotationSet get(String type) | Returns all annotations of the specified type. |
AnnotationSet get(Set types) | Returns all annotations of the specified types. |
AnnotationSet get(String type, FeatureMap constraints) | Selects annotations by type and features. |
Set getAllTypes() | Gets a set of java.lang.String objects representing all the annotation types present in this annotation set. |
AnnotationSet getContained(Long startOffset, Long endOffset) | Select annotations contained within an interval, i.e. |
AnnotationSet getCovering(String neededType, Long startOffset, Long endOffset) | Select annotations of the given type that completely span the range. |
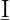 terating from left to right over all annotations of a given type
terating from left to right over all annotations of a given type
2String type = "Person";
3//Get all person annotations
4AnnotationSet persSet = annSet.get(type);
5//Sort the annotations
6List persList = new ArrayList(persSet);
7Collections.sort(persList, new gate.util.OffsetComparator());
8//Iterate
9Iterator persIter = persList.iterator();
10while(persIter.hasNext()){
11...
12}
7.4.4 Annotations [#]
An annotation is a form of meta-data attached to a particular section of document content. The connection between the annotation and the content it refers to is made by means of two pointers that represent the start and end locations of the covered content. An annotation must also have a type (or a name) which is used to create classes of similar annotations, usually linked together by their semantics.
An Annotation is defined by:
-
start node
-
a location in the document content defined by an offset.
-
end node
-
a location in the document content defined by an offset.
-
type
-
a String value.
-
features
-
(see Section 7.4.2).
-
ID
-
an Integer value. All annotations IDs are unique inside an annotation set.
In GATE Embedded, annotations are defined by the gate.Annotation interface and implemented by the gate.annotation.AnnotationImpl class. Annotations exist only as members of annotation sets (see Section 7.4.3) and they should not be directly created by means of a constructor. Their creation should always be delegated to the containing annotation set.
7.4.5 GATE Corpora [#]
A corpus in GATE is a Java List (i.e. an implementation of java.util.List) of documents. GATE corpora are defined by the gate.Corpus interface and the following implementations are available:
-
gate.corpora.CorpusImpl
-
used for transient corpora.
-
gate.corpora.SerialCorpusImpl
-
used for persistent corpora that are stored in a serial datastore (i.e. as a directory in a file system).
Apart from implementation for the standard List methods, a Corpus also implements the methods in table 7.6.
Method | Purpose |
String getDocumentName(int index) | Gets the name of a document in this corpus. |
List getDocumentNames() | Gets the names of all the documents in this corpus. |
void populate(URL directory, FileFilter filter, String encoding, boolean recurseDirectories) | Fills this corpus with documents created on the fly from selected files in a directory. Uses a FileFilter to select which files will be used and which will be ignored. A simple file filter based on extensions is provided in the Gate distribution (gate.util.ExtensionFileFilter). |
void populate(URL singleConcatenatedFile, String documentRootElement, String encoding, int numberOfDocumentsToExtract, String documentNamePrefix, DocType documentType) | Fills the provided corpus with documents extracted from the provided single concatenated file. Uses the content between the start and end of the element as specified by documentRootElement for each document. The parameter documentType specifies if the resulting files are html, xml or of any other type. User can also restrict the number of documents to extract by providing the relevant value for numberOfDocumentsToExtract parameter. |
Creating a corpus from all XML files in a directory
Using a DataStore
Assuming that you have a DataStore already open called myDataStore, this code will ask the datastore to take over persistence of your document, and to synchronise the memory representation of the document with the disk storage:
Document persistentDoc = myDataStore.adopt(doc, mySecurity); myDataStore.sync(persistentDoc);
When you want to restore a document (or other LR) from a datastore, you make the same createResource call to the Factory as for the creation of a transient resource, but this time you tell it the datastore the resource came from, and the ID of the resource in that datastore:
2 SerialDataStore sds = new SerialDataStore(u.toString());
3 sds.open();
4
5 // getLrIds returns a list of LR Ids, so we get the first one
6 Object lrId = sds.getLrIds("gate.corpora.DocumentImpl").get(0);
7
8 // we need to tell the factory about the LR’s ID in the data
9 // store, and about which datastore it is in − we do this
10 // via a feature map:
11 FeatureMap features = Factory.newFeatureMap();
12 features.put(DataStore.LR_ID_FEATURE_NAME, lrId);
13 features.put(DataStore.DATASTORE_FEATURE_NAME, sds);
14
15 // read the document back
16 Document doc = (Document)
17 Factory.createResource("gate.corpora.DocumentImpl", features);
7.5 Processing Resources [#]
Processing Resources (PRs) represent entities that are primarily algorithmic, such as parsers, generators or ngram modellers.
They are created using the GATE Factory in manner similar the Language Resources. Besides the creation-time parameters they also have a set of run-time parameters that are set by the system just before executing them.
Analysers are a particular type of processing resources in the sense that they always have a document and a corpus among their run-time parameters.
The most used methods for Processing Resources are presented in table 7.7
Method | Purpose |
void setParameterValue(String paramaterName, Object parameterValue) | Sets the value for a specified parameter. method inherited from gate.Resource |
void setParameterValues(FeatureMap parameters) | Sets the values for more parameters in one step. method inherited from gate.Resource |
Object getParameterValue(String paramaterName) | Gets the value of a named parameter of this resource. method inherited from gate.Resource |
Resource init() | Initialise this resource, and return it. method inherited from gate.Resource |
void reInit() | Reinitialises the processing resource. After calling this method the resource should be in the state it is after calling init. If the resource depends on external resources (such as rules files) then the resource will re-read those resources. If the data used to create the resource has changed since the resource has been created then the resource will change too after calling reInit(). |
void execute() | Starts the execution of this Processing Resource. |
void interrupt() | Notifies this PR that it should stop its execution as soon as possible. |
boolean isInterrupted() | Checks whether this PR has been interrupted since the last time its Executable.execute() method was called. |
7.6 Controllers [#]
Controllers are used to create GATE applications. A Controller handles a set of Processing Resources and can execute them following a particular strategy. GATE provides a series of serial controllers (i.e. controllers that run their PRs in sequence):
-
gate.creole.SerialController:
-
a serial controller that takes any kind of PRs.
-
gate.creole.SerialAnalyserController:
-
a serial controller that only accepts Language Analysers as member PRs.
-
gate.creole.ConditionalSerialController:
-
a serial controller that accepts all types of PRs and that allows the inclusion or exclusion of member PRs from the execution chain according to certain run-time conditions (currently features on the document being processed are used).
-
gate.creole.ConditionalSerialAnalyserController:
-
a serial controller that only accepts Language Analysers and that allows the conditional run of member PRs.
-
gate.creole.RealtimeCorpusController:
-
a SerialAnalyserController that allows you to specify graceful and timeout parameters (times in milliseconds). If processing for a document takes longer than the amount of time specified for graceful, then the controller will attempt to gracefully end it by sending an interrupt request to it. If the graceful parameter is ‘-1’ then no attempt to gracefully end it is made. If processing takes longer than the amount of time specified for the timeout parameter, it will be forcibly terminated and the controller will move on to the next document. The parameter suppressExceptions controls if time-outs and other exceptions will be suppressed or passed on to the caller: if this parameter is set to ‘true’, then any exception or a timeout will simply cause the controller to move on to the next document rather than failing the entire corpus processing. If the parameter is set to ‘false’ both time-outs and exceptions will be passed on as exceptions to the caller.
Additionally there is a scriptable controller provided by the Groovy plugin. See section 7.16.3 for details.
Creating an ANNIE application and running it over a corpus
2Plugin anniePlugin = new Plugin.Maven(
3 "uk.ac.gate.plugins", "annie", gate.Main.version);
4Gate.getCreoleRegister().registerPlugin(anniePlugin);
5
6// create a serial analyser controller to run ANNIE with
7SerialAnalyserController annieController =
8 (SerialAnalyserController) Factory.createResource(
9 "gate.creole.SerialAnalyserController",
10 Factory.newFeatureMap(),
11 Factory.newFeatureMap(), "ANNIE");
12
13// load each PR as defined in ANNIEConstants
14// Note this code is for demonstration purposes only,
15// in practice if you want to load the ANNIE app you
16// should use the PersistenceManager as shown at the
17// start of this chapter
18for(int i = 0; i < ANNIEConstants.PR_NAMES.length; i++) {
19 // use default parameters
20 FeatureMap params = Factory.newFeatureMap();
21 ProcessingResource pr = (ProcessingResource)
22 Factory.createResource(ANNIEConstants.PR_NAMES[i],
23 params);
24 // add the PR to the pipeline controller
25 annieController.add(pr);
26} // for each ANNIE PR
27
28// Tell ANNIE’s controller about the corpus you want to run on
29Corpus corpus = ...;
30annieController.setCorpus(corpus);
31// Run ANNIE
32annieController.execute();
7.7 Modelling Relations between Annotations [#]
Most text processing tasks in GATE model metadata associated with text snippets as annotations. In some cases, however, it is useful to to have another layer of metadata, associated with the annotations themselves. One such case is the modelling of relations between annotations. One typical example of relations between annotation is that of co-reference. Two annotations of type Person may be referring to the same actual person; in this case the two annotations are said to be co-referring.
Starting with version 7.1, GATE Embedded supports the representation of relations between annotations. A relation set is associated with, and accssed via, an annotation set. All members of a relation must be either annotations from the associated annotation set or other relations within the same set. The classes supporting relations can be found in the gate.relations package.
A relation, as described by the gate.relations.Relation interface, is defined by the following values:
-
id
-
a unique ID that identifies the relation. IDs for both relations and annotations are generated from the same source, guaranteeing that not only is the ID unique among the relations, but also among all annotations from the same document.
-
type
-
a String value describing the type of the relation (e.g. ’coref’ for co-reference relations).
-
members
-
an int[] array, containing the annotation IDs for the annotations referred to by the relation. Note that relations are not guaranteed to be symmetric, so the ordering in the members array is relevant.
-
featureMap
-
a FeatureMap that, like with Annotations, allows the storing of an arbitary set of features for the relation.
-
userData
-
an optional Serializable value, which can be used to associate any arbitrary data with a relation.
Relation sets are modelled by the gate.relations.RelationSet class. The principal API calls published by this class include:
-
public Relation addRelation(String type, int... members)
Creates a new relation with the specified type and member annotations. Returns the newly created relation object. -
public void addRelation(Relation rel)
Adds to this relation set an externally-created relation. This method is provided to support the use of custom implementations of the gate.relations.Relation interface. -
public boolean deleteRelation(Relation relation)
Deletes the specified relation from this relation set. Any relations which include this relation as a member will also be deleted (recursively) to ensure the set remains internally consistent. -
public Collection<Relation> get()
Returns all the relations within this set. -
public Relation get(Integer id)
Returns the relation with the given ID. -
public Collection<Relation> getRelations(String type)
Gets all relations with the specified type contained in this relation set. -
public Collection<Relation> getRelations(int... members)
Gets relations by members. Gets all relations with have the specified members on the specified positions. The required members are represented as an int[], where each required annotation ID is placed on its required position. For unconstrained positions, the constant value gate.relations.RelationSet.ANY should be used. -
public Collection<Relation> getRelations(String type, int... members)
Gets all relations with the specified type and members. -
public Collection<Relation> getReferencing(int id)
Gets all the relations which reference an annotation or relation with the specified ID. -
public int getMaximumArity()
Gets the maximum arity (number of members) for all relations in this relation set.
Included next is a simple code snippet that illustrates the RelationSet API. The function of the example code is to:
-
find all the Sentence annotations inside a document;
-
for each sentence, find all the contained Token annotations;
-
for each sentence and contained token, add a new relation named contained between the token and the sentence.
2Document doc = Factory.newDocument(
3 new File("documents/file.xml").toURI().toURL());
4// get the annotation set
5AnnotationSet annSet = doc.getAnnotations();
6// get the relations set
7RelationSet relSet = annSet.getRelations();
8// get all sentences
9AnnotationSet sentences = annSet.get(
10 ANNIEConstants.SENTENCE_ANNOTATION_TYPE);
11for(Annotation sentence : sentences) {
12 // get all the tokens
13 AnnotationSet tokens = annSet.get(
14 ANNIEConstants.TOKEN_ANNOTATION_TYPE,
15 sentence.getStartNode().getOffset(),
16 sentence.getEndNode().getOffset());
17 for(Annotation token : tokens) {
18 // for each sentence and token, add the contained relation
19 relSet.addRelation("contained",
20 new int[] {token.getId(), sentence.getId()});
21 }
22}
7.8 Duplicating a Resource [#]
Sometimes, particularly in a multi-threaded application, it is useful to be able to create an independent copy of an existing PR, controller or LR. The obvious way to do this is to call createResource again, passing the same class name, parameters, features and name, and for many resources this will do the right thing. However there are some resources for which this may be insufficient (e.g. controllers, which also need to duplicate their PRs), unsafe (if a PR uses temporary files, for instance), or simply inefficient. For example for a large gazetteer this would involve loading a second copy of the lists into memory and compiling them into a second identical state machine representation, but a much more efficient way to achieve the same behaviour would be to use a SharedDefaultGazetteer (see section 13.10), which can re-use the existing state machine.
The GATE Factory provides a duplicate method which takes an existing resource instance and creates and returns an independent copy of the resource. By default it uses the algorithm described above, extracting the parameter values from the template resource and calling createResource to create a duplicate (the actual algorithm is slightly more complicated than this, see the following section). However, if a particular resource type knows of a better way to duplicate itself it can implement the CustomDuplication interface, and provide its own duplicate method which the factory will use instead of performing the default duplication algorithm. A caller who needs to duplicate an existing resource can simply call Factory.duplicate to obtain a copy, which will be constructed in the appropriate way depending on the resource type.
Note that the duplicate object returned by Factory.duplicate will not necessarily be of the same class as the original object. However the contract of Factory.duplicate specifies that where the original object implements any of a list of core GATE interfaces, the duplicate can be assumed to implement the same ones – if you duplicate a DefaultGazetteer the result may not be an instance of DefaultGazetteer but it is guaranteed to implement the Gazetteer interface.
Full details of how to implement a custom duplicate method in your own resource type can be found in the JavaDoc documentation for the CustomDuplication interface and the Factory.duplicate method.
7.8.1 Sharable properties [#]
The @Sharable annotation (in the gate.creole.metadata package) provides a way for a resource to mark JavaBean properties whose values should be shared between a resource and its duplicates. Typical examples of objects that could be marked sharable include large or expensive-to-create data structures that are created by a resource at init time and subsequently used in a read-only fashion, a thread-safe cache of some sort, or state used to create globally unique identifiers (such as an AtomicInteger that is incremented each time a new ID is required). Clearly any ojects that are shared between different resource instances must be accessed by all instances in a way that is thread-safe or appropriately synchronized.
The sharable property must have the standard public getter and setter methods, with the @Sharable annotation applied to the setter4. The same setter may be marked both as a sharable property and as a @CreoleParameter but the two are not related – sharable properties that are not parameters and parameters that are not sharable are both allowed and both have uses in different circumstances. The use of sharable properties removes the need to implement custom duplication in many simple cases.
The default duplication algorithm in full is thus as follows:
-
Extract the values of all init-time parameters from the original resource.
-
Recursively duplicate any of these values that are themselves GATE Resources, except for parameters that are marked as @Sharable (i.e. parameters that are marked sharable are copied directly to the duplicate resource without being duplicated themselves).
-
Add to this parameter map any other sharable properties of the original resource (including those that are not parameters).
-
Extract the features of the original resource and recursively duplicate any values in this map that are themselves resources, as above.
-
Call Factory.createResource passing the class name of the original resource, the duplicated/shared parameters and the duplicated features.
-
this will result in a call to the new resource’s init method, with all sharable properties (parameters and non-parameters) populated with their values from the old resource. The init method must recognise this and adapt its behaviour appropriately, i.e. not re-creating sharable data structures that have already been injected.
-
-
If the original resource is a PR, extract its runtime parameter values (except those that are marked as sharable, which have already been dealt with above), and recursively duplicate any resource values in the map.
-
Set the resulting runtime parameter values on the duplicate resource.
The duplication process keeps track of any recursively-duplicated resources, such that if the same original resource is used in several places (e.g. when duplicating a controller with several JAPE transducer PRs that all refer to the same ontology LR in their runtime parameters) then the same duplicate (ontology) will be used in the same places in the duplicated resource (i.e. all the duplicate transducers will refer to the same ontology LR, which will be a duplicate of the original one).
7.9 Persistent Applications [#]
GATE Embedded allows the persistent storage of applications in a format based on XML serialisation. This is particularly useful for applications management and distribution. A developer can save the state of an application when he/she stops working on its design and continue developing it in a next session. When the application reaches maturity it can be deployed to the client site using the same method.
When an application (i.e. a Controller) is saved, GATE will actually only save the values for the parameters used to create the Processing Resources that are contained in the application. When the application is reloaded, all the PRs will be re-created using the saved parameters.
Many PRs use external resources (files) to define their behaviour and, in most cases, these files are identified using URLs. During the saving process, all the URLs are converted relative URLs based on the location of the application file. This way, if the resources are packaged together with the application file, the entire application can be reliably moved to a different location.
API access to application saving and loading is provided by means of two static methods on the gate.util.persistence.PersistenceManager class, listed in table 7.8.
Method | Purpose |
public static void saveObjectToFile(Object obj, File file) | Saves the data needed to re-create the provided GATE object to the specified file. The Object provided can be any type of Language or Processing Resource or a Controller. The procedures may work for other types of objects as well (e.g. it supports most Collection types). |
public static Object loadObjectFromFile(File file) | Parses the file specified (which needs to be a file created by the above method) and creates the necessary object(s) as specified by the data in the file. Returns the root of the object tree. |
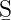 aving and loading a GATE application
aving and loading a GATE application
2File file = ...;
3//What to save?
4Controller theApplication = ...;
5
6//save
7gate.util.persistence.PersistenceManager.
8 saveObjectToFile(theApplication, file);
9//delete the application
10Factory.deleteResource(theApplication);
11theApplication = null;
12
13[...]
14//load the application back
15theApplication = gate.util.persistence.PersistenceManager.
16 loadObjectFromFile(file);
7.10 Ontologies
Starting from GATE version 3.1, support for ontologies has been added. Ontologies are nominally Language Resources but are quite different from documents and corpora and are detailed in chapter 14.
Classes related to ontologies are to be found in the gate.creole.ontology package and its sub-packages. The top level package defines an abstract API for working with ontologies while the sub-packages contain concrete implementations. A client program should only use the classes and methods defined in the API and never any of the classes or methods from the implementation packages.
The entry point to the ontology API is the gate.creole.ontology.Ontology interface which is the base interface for all concrete implementations. It provides methods for accessing the class hierarchy, listing the instances and the properties.
Ontology implementations are available through plugins. Before an ontology language resource can be created using the gate.Factory and before any of the classes and methods in the API can be used, one of the implementing ontology plugins must be loaded. For details see chapter 14.
7.11 Loading Annotation Schemas [#]
In order to create a gate.creole.AnnotationSchema object from a schema annotation file, one must use the gate.Factory class;
2param.put("xmlFileUrl",annotSchemaFile.toURL());\\
3AnnotationSchema annotSchema = \\
4Factory.createResurce("gate.creole.AnnotationSchema", params);
Note: All the elements and their values must be written in lower case, as XML is defined as case sensitive and the parser used for XML Schema inside GATE searches is case sensitive.
In order to be able to write XML Schema definitions, the ones defined in GATE (resources/creole/schema) can be used as a model, or the user can have a look at http://www.w3.org/2000/10/XMLSchema for a proper description of the semantics of the elements used.
Some examples of annotation schemas are given in Section 5.4.1.
7.12 Creating a New CREOLE Resource [#]
To create a new resource you need to:
-
write a Java class that implements GATE’s beans model;
-
annotate the class with the necessary CREOLE metadata;
-
compile the class, and any others that it uses, into a Java Archive (JAR) file, including a creole.xml file to identify the JAR as a plugin;
-
tell GATE how to find the JAR.
The recommended way to build GATE plugins from version 8.5 onwards is to use the Apache Maven build tool. A JAR file requires certain specific contents in order to be a valid GATE plugin, and GATE provides tools to automate the creation of these as part of a Maven build. For best results you should use Maven 3.5.2 or later.
GATE provides a Maven archetype to create the skeleton of a new plugin including an example AbstractLanguageAnalyser processing resource you can use as a starting point for your own code. To create a new plugin project from the archetype, run the following Maven command (which has been split over several lines for clarity, but should be run as a single command):
mvn archetype:generate -DarchetypeGroupId=uk.ac.gate \ -DarchetypeArtifactId=gate-pr-archetype \ -DarchetypeVersion=8.6
Replace “8.6” with the version of gate-core that you wish to depend on. You will be prompted for several values by Maven:
-
groupId
-
the group ID to use in the generated project POM. In Maven terms a “group” is a set of related JARs maintained and released by the same developer or group – conventionally this is based on the same convention as Java package names, using a reversed form of a DNS domain you own. You can use any value you like here, except that you should not use a group ID starting uk.ac.gate, as that is reserved for core plugins from the GATE team.
-
artifactId
-
the artifact ID for the generated project POM – this will be used as the directory name for the new project on disk and as the first part of the name of the final JAR file.
-
version
-
the initial version number for your new plugin – this should always end with -SNAPSHOT in capital letters, which is a Maven convention denoting work-in-progress code where the same version number can refer to different JAR files over time. The Maven dependency mechanism assumes that only -SNAPSHOT versions can ever change, and JAR files for non-SNAPSHOT versions are immutable and can be cached forever.
-
package
-
the Java package name. Often this is the same as the group ID but this is not strictly required.
-
prClass
-
the class name of the PR class to generate – this must be a valid Java identifier.
-
prName
-
the name of the PR as it will appear to users in the GATE Developer GUI (e.g. in the “new processing resource” popup menu).
Alternatively you can specify any of these values as extra -D options to archetype:generate, e.g. -DprClass=GoldfishTagger.
The archetype will create a new directory named after the artifactId, containing a few files:
-
pom.xml
-
the Maven project descriptor controlling the build process
-
src/main/java/package/prClass.java
-
the PR Java class.
-
src/main/resources/creole.xml
-
the plugin descriptor that identifies this project as a GATE plugin.
-
src/main/resources/resources
-
a directory into which you should put any resource files that your PR requires (e.g. configuration files, JAPE grammars, etc.). The doubled “resources” is deliberate – src/main/resources is the Maven conventional location for non-Java files that should be packaged in the JAR, and GATE requires a folder called resources inside that.
-
src/test
-
some simple tests.
The generated Java class in src/main/java contains some basic CREOLE metadata and an example of how you can configure parameters, and some boilerplate initialization and execution code that you can modify to your requirements.
There is an alternative archetype available called gate-plugin-archetype, which creates the Maven project structure, POM file and creole.xml but not the example Java class. This is useful if you already have an existing CREOLE plugin from an earlier version of GATE that you want to convert to the Maven style. The process is exactly the same as described above, use the same mvn archetype:generate call as before but with -DarchetypeArtifactId=gate-plugin-archetype.
7.12.1 Dependencies [#]
If you need to use other Java libraries in your PR code you should declare them in the <dependencies> block of the pom.xml. You can use https://search.maven.org to find the appropriate XML snippet for each dependency.
If your plugin requires another GATE plugin to operate (for example if it needs to internally create a JAPE transducer PR) then you should declare a dependency on the relevant plugin in src/main/resources/creole.xml (see section 4.7, in particular the REQUIRES element) and GATE will ensure that the other plugin is always loaded before this one, and that this plugin is unloaded whenever the other one is unloaded.
If your plugin has a compile-time dependency on another plugin then you will also need to declare this in pom.xml as well as in creole.xml – the pom dependency should use “provided” scope:
<dependency> <groupId>uk.ac.gate.plugins</groupId> <artifactId>annie</artifactId> <version>8.5</version> <scope>provided</scope> </dependency>
Note that such dependencies are very rarely required, typically only if you need to write a PR class in one plugin that extends (in the Java sense) a PR defined in another plugin. If you simply need to run another plugin’s PR as part of yours then the creole.xml dependency is sufficient as you would create and use the PR via the Factory in the normal way.
2// of this PR and is of type \texttt{ResourceReference}
3FeatureMap params = Utils.featureMap("grammarUrl", grammarLocation);
4LanguageAnalyser jape = (LanguageAnalyser)Factory.createResource(
5 "gate.creole.Transducer", params);
One of the tests created by the archetypes, the GappLoadingTest, will look for any saved application files in src/main/resources and test that they load successfully into GATE. As a side effect, this test will also create two files in the target folder detailing all the other plugins on which this plugin depends. It captures both direct dependencies (REQUIRES entries in creole.xml) and indirect dependencies where other plugins are loaded by one of this plugin’s saved applications, even if there is no hard dependency between them. For example, many plugins have sample applications that require the ANNIE plugin in order to load document reset, tokeniser or JAPE transducer PRs. The information is presented in two ways:
-
a flat file creole-dependencies.txt listing the plugins with the plugin under test on the first row and then other required plugins in the order they were loaded during the GappLoadingTest.
-
a representation of the dependency graph in the GraphViz DOT format (creole-dependencies.gv) with a node for each plugin and an edge for each dependency, coloured red for REQUIRES links and coloured green for dependencies only expressed by the sample saved applications.
7.13 Adding Support for a New Document Format [#]
In order to add a new document format, one needs to extend the gate.DocumentFormat class and to implement an abstract method called:
This method is supposed to implement the functionality of each format reader and to create annotations on the document. Finally the document’s old content will be replaced with a new one containing only the text between markups.
If one needs to add a new textual reader will extend the gate.corpora.TextualDocumentFormat and override the unpackMarkup(doc) method.
This class needs to be implemented under the Java bean specifications because it will be instantiated by GATE using Factory.createResource() method.
The init() method that one needs to add and implement is very important because in here the reader defines its means to be selected successfully by GATE. What one needs to do is to add some specific information into certain static maps defined in DocumentFormat class, that will be used at reader detection time.
After that, a definition of the reader will be placed into the one’s creole.xml file and the reader will be available to GATE.
We present for the rest of the section a complete three step example of adding such a reader. The reader we describe in here is an XML reader.
Step 1
Create a new class called XmlDocumentFormat that extends
gate.corpora.TextualDocumentFormat and add appropriate CREOLE metadata. For
example:
2 autoinstances = {@AutoInstance(hidden = true)})
3public class XmlDocumentFormat extends TextualDocumentFormat {
4
5}
Step 2
Implement the unpackMarkup(Document doc) which performs the required functionality for the reader. Add XML detection means in init() method:
2 // Register XML mime type
3 MimeType mime = new MimeType("text","xml");
4 // Register the class handler for this mime type
5 mimeString2ClassHandlerMap.put(mime.getType()+ "/" + mime.getSubtype(),
6 this);
7 // Register the mime type with mine string
8 mimeString2mimeTypeMap.put(mime.getType() + "/" + mime.getSubtype(),
9 mime);
10 // Register file suffixes for this mime type
11 suffixes2mimeTypeMap.put("xml",mime);
12 suffixes2mimeTypeMap.put("xhtm",mime);
13 suffixes2mimeTypeMap.put("xhtml",mime);
14 // Register magic numbers for this mime type
15 magic2mimeTypeMap.put("<?xml",mime);
16 // Set the mimeType for this language resource
17 setMimeType(mime);
18 return this;
19}// init()
More details about the information from those maps can be found in Section 5.5.1
More information on the operation of GATE’s document format analysers may be found in Section 5.5.
7.14 Using GATE Embedded in a Multithreaded Environment [#]
GATE Embedded can be used in multithreaded applications, so long as you observe a few restrictions. First, you must initialise GATE by calling Gate.init() exactly once in your application, typically in the application startup phase before any concurrent processing threads are started.
Secondly, you must not make calls that affect the global state of GATE (e.g. loading or unloading plugins) in more than one thread at a time. Again, you would typically load all the plugins your application requires at initialisation time. It is safe to create instances of resources in multiple threads concurrently.
Thirdly, it is important to note that individual GATE processing resources, language resources and controllers are by design not thread safe – it is not possible to use a single instance of a controller/PR/LR in multiple threads at the same time – but for a well written resource it should be possible to use several different instances of the same resource at once, each in a different thread. When writing your own resource classes you should bear the following in mind, to ensure that your resource will be useable in this way.
-
Avoid static data. Where possible, you should avoid using static fields in your class, and you should try and take all configuration data via the CREOLE parameters you declare in your creole.xml file. System properties may be appropriate for truly static configuration, such as the location of an external executable, but even then it is generally better to stick to CREOLE parameters – a user may wish to use two different instances of your PR, each talking to a different executable.
-
Read parameters at the correct time. Init-time parameters should be read in the init() (and reInit()) method, and for processing resources runtime parameters should be read at each execute().
-
Use temporary files correctly. If your resource makes use of external temporary files you should create them using File.createTempFile() at init or execute time, as appropriate. Do not use hardcoded file names for temporary files.
-
If there are objects that can be shared between different instances of your resource, make sure these objects are accessed either read-only, or in a thread-safe way. In particular you must be very careful if your resource can take other resource instances as init or runtime parameters (e.g. the Flexible Gazetteer, Section 13.6).
Of course, if you are writing a PR that is simply a wrapper around an external library that imposes these kinds of limitations there is only so much you can do. If your resource cannot be made safe you should document this fact clearly.
All the standard ANNIE PRs are safe when independent instances are used in different threads concurrently, as are the standard transient document, transient corpus and controller classes. A typical pattern of development for a multithreaded GATE-based application is:
-
Develop your GATE processing pipeline in GATE Developer.
-
Save your pipeline as a .gapp file.
-
In your application’s initialisation phase, load n copies of the pipeline using PersistenceManager.loadObjectFromFile() (see the Javadoc documentation for details), or load the pipeline once and then make copies of it using Factory.duplicate as described in section 7.8, and either give one copy to each thread or store them in a pool (e.g. a LinkedList).
-
When you need to process a text, get one copy of the pipeline from the pool, and return it to the pool when you have finished processing.
Alternatively you can use the Spring Framework as described in the next section to handle the pooling for you.
7.15 Using GATE Embedded within a Spring Application [#]
GATE Embedded provides helper classes to allow GATE resources to be created and managed by the Spring framework. These helpers are provided by the gate-spring module, which must be added as a dependency of your project (and which in turn depends on gate-core). To use the helpers in an XML bean definition file, add the following declarations to the top:
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:gate="http://gate.ac.uk/ns/spring" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://gate.ac.uk/ns/spring http://gate.ac.uk/ns/spring.xsd">
You can have Spring initialise GATE:
<gate:init />
For backwards compatibility the <gate:init> element accepts a number of attributes which were used in earlier versions of GATE to specify paths to GATE’s “home” folder and configuration files, but as of GATE 8.5 these options do nothing by default. If you do want to load a user configuration file (for example to configure things like the “add space on markup unpack” feature) then you must explicitly turn off the sandbox mode:
<gate:init run-in-sandbox="false" user-config-file="WEB-INF/user/xml" />
The user-config-file location is interpreted as a Spring “resource” path. If the value is not an absolute URL then Spring will resolve the path in an appropriate way for the type of application context — in a web application it is taken as being relative to the web app root, and you would typically use a location within WEB-INF as shown in the example above. To use an absolute path for gate-home it is not sufficient to use a leading slash (e.g. /opt/myapp/user.xml), for backwards-compatibility reasons Spring will still resolve this relative to your web application. Instead you must specify it as a full URL, i.e. file:/opt/myapp/user.xml.
You can specify CREOLE plugins that should be loaded after GATE has initialised using <gate:extra-plugin> elements, for example:
<gate:init /> <!-- load the standard ANNIE plugin from Maven Central --> <gate:extra-plugin group-id="uk.ac.gate.plugins" artifact-id="annie" vesion="8.5" /> <!-- load a custom directory-based plugin from inside the webapp --> <gate:extra-plugin>WEB-INF/plugins/FishCounter</gate:extra-plugin>
The usual rules apply for the resolution of Maven plugins – GATE will look in .m2/repository under the home directory of the current user, as well as in the Central repository and the GATE team repository online, plus any repositories configured in the current user’s .m2/settings.xml. As well as this you can specify a local “cache” directory which is a Maven repository that will be searched first before trying any remote repositories, as part of the <gate:init> element:
<gate:init> <gate:maven-caches> <value>WEB-INF/maven-cache</value> </gate:maven-caches> </gate:init>
Note that due to restrictions within the Maven resolver this must be a real directory on disk, so in the web application case if you put a cache inside your WAR file it will only be used if the WAR is unpacked by the container, not if it attempts to run the application directly from the compressed WAR.
To create a GATE resource, use the <gate:resource> element.
<gate:resource id="referenceDocument" scope="singleton" resource-class="gate.corpora.DocumentImpl"> <gate:parameters> <entry key="sourceUrl"> <gate:url>WEB-INF/reference.xml</gate:url> </entry> </gate:parameters> <gate:features> <entry key="documentVersion" value="0.1.3" /> <entry key="mainRef"> <value type="java.lang.Boolean">true</value> </entry> </gate:features> </gate:resource>
The children of <gate:parameters> are Spring <entry/> elements, just as you would write when configuring a bean property of type Map<String,Object>. <gate:url> provides a way to construct a java.net.URL from a resource path as discussed above. If it is possible to resolve the resource path as a file: URL then this form will be preferred, as there are a number of areas within GATE which work better with file: URLs than with other types of URL (for example plugins that run external processes, or that use a URL parameter to point to a directory in which they will create new files).
A note about types: The <gate:parameters> and <gate:features> elements define GATE FeatureMaps. When using the simple <entry key="..." value="..." /> form, the entry values will be treated as strings; Spring can convert strings into many other types of object using the standard Java Beans property editor mechanism, but since a FeatureMap can hold any kind of values you must use an explicit <value type="...">...</value> to tell Spring what type the value should be.
There is an additional twist for <gate:parameters> – GATE has its own internal logic to convert strings to other types required for resource parameters (see the discussion of default parameter values in section 4.7.1). So for parameter values you have a choice, you can either use an explicit <value type="..."> to make Spring do the conversion, or you can pass the parameter value as a string and let GATE do the conversion. For resource parameters whose type is gate.creole.ResourceReference, if you pass a string value that is not an absolute URL (starting file:, http:, etc.) then GATE will treat the string as a path relative to the plugin that defines the resource type whose parameter you are setting. If this is not what you intended then you should use <gate:url> to cause Spring to resolve the path to a URL (which GATE will then convert to a ResourceReference) before passing it to GATE. For example, for a JAPE transducer, <entry key="grammarURL" value="grammars/main.jape" /> would resolve to the resource reference creole://uk.ac.gate.plugins;annie;8.5/grammars/main.jape, whereas
<entry key="grammarURL"> <gate:url>grammars/main.jape</gate:url> </entry>
would resolve to file:/path/to/webapp/grammars/main.jape.
You can load a GATE saved application with
<gate:saved-application location="WEB-INF/application.gapp" scope="prototype"> <gate:customisers> <gate:set-parameter pr-name="custom transducer" name="ontology" ref="sharedOntology" /> </gate:customisers> </gate:saved-application>
‘Customisers’ are used to customise the application after it is loaded. In the example above, we assume we have loaded a singleton copy of an ontology which is then shared between all the separate instances of the (prototype) application. The <gate:set-parameter> customiser accepts all the same ways to provide a value as the standard Spring <property> element (a "value" or "ref" attribute, or a sub-element - <value>, <list>, <bean>, <gate:resource> …).
The <gate:add-pr> customiser provides support for the case where most of the application is in a saved state, but we want to create one or two extra PRs with Spring (maybe to inject other Spring beans as init parameters) and add them to the pipeline.
<gate:saved-application ...> <gate:customisers> <gate:add-pr add-before="OrthoMatcher" ref="myPr" /> </gate:customisers> </gate:saved-application>
By default, the <gate:add-pr> customiser adds the target PR at the end of the pipeline, but an add-before or add-after attribute can be used to specify the name of a PR before (or after) which this PR should be placed. Alternatively, an index attribute places the PR at a specific (0-based) index into the pipeline. The PR to add can be specified either as a ‘ref’ attribute, or with a nested <bean> or <gate:resource> element.
7.15.1 Duplication in Spring [#]
The above example defines the <gate:application> as a prototype-scoped bean, which means the saved application state will be loaded afresh each time the bean is fetched from the bean factory (either explicitly using getBean or implicitly when it is injected as a dependency of another bean). However in many cases it is better to load the application once and then duplicate it as required (as described in section 7.8), as this allows resources to optimise their memory usage, for example by sharing a single in-memory representation of a large gazetteer list between several instances of the gazetteer PR. This approach is supported by the <gate:duplicate> tag.
<gate:duplicate id="theApp"> <gate:saved-application location="/WEB-INF/application.xgapp" /> </gate:duplicate>
The <gate:duplicate> tag acts like a prototype bean definition, in that each time it is fetched or injected it will call Factory.duplicate to create a new duplicate of its template resource (declared as a nested element or referenced by the template-ref attribute). However the tag also keeps track of all the duplicate instances it has returned over its lifetime, and will ensure they are released (using Factory.deleteResource) when the Spring context is shut down.
The <gate:duplicate> tag also supports customisers, which will be applied to the newly-created duplicate resource before it is returned. This is subtly different from applying the customisers to the template resource itself, which would cause them to be applied once to the original resource before it is first duplicated.
Finally, <gate:duplicate> takes an optional boolean attribute return-template. If set to false (or omitted, as this is the default behaviour), the tag always returns a duplicate — the original template resource is used only as a template and is not made available for use. If set to true, the first time the bean defined by the tag is injected or fetched, the original template resource is returned. Subsequent uses of the tag will return duplicates. Generally speaking, it is only safe to set return-template="true" when there are no customisers, and when the duplicates will all be created up-front before any of them are used. If the duplicates will be created asynchronously (e.g. with a dynamically expanding pool, see below) then it is possible that, for example, a template application may be duplicated in one thread whilst it is being executed by another thread, which may lead to unpredictable behaviour.
7.15.2 Spring pooling [#]
In a multithreaded application it is vital that individual GATE resources are not used in more than one thread at the same time. Because of this, multithreaded applications that use GATE Embedded often need to use some form of pooling to provided thread-safe access to GATE components. This can be managed by hand, but the Spring framework has built-in tools to support transparent pooling of Spring-managed beans. Spring can create a pool of identical objects, then expose a single “proxy” object (offering the same interface) for use by clients. Each method call on the proxy object will be routed to an available member of the pool in such a way as to guarantee that each member of the pool is accessed by no more than one thread at a time.
Since the pooling is handled at the level of method calls, this approach is not used to create a pool of GATE resources directly — making use of a GATE PR typically involves a sequence of method calls (at least setDocument(doc), execute() and setDocument(null)), and creating a pooling proxy for the resource may result in these calls going to different members of the pool. Instead the typical use of this technique is to define a helper object with a single method that internally calls the GATE API methods in the correct sequence, and then create a pool of these helpers. The interface gate.util.DocumentProcessor and its associated implementation gate.util.LanguageAnalyserDocumentProcessor are useful for this. The DocumentProcessor interface defines a processDocument method that takes a GATE document and performs some processing on it. LanguageAnalyserDocumentProcessor implements this interface using a GATE LanguageAnalyser (such as a saved “corpus pipeline” application) to do the processing. A pool of LanguageAnalyserDocumentProcessor instances can be exposed through a proxy which can then be called from several threads.
The machinery to implement this is all built into Spring, but the configuration typically required to enable it is quite fiddly, involving at least three co-operating bean definitions. Since the technique is so useful with GATE Embedded, GATE provides a special syntax to configure pooling in a simple way.
To use Spring pooling, you need to add a dependency to your project on an appropriate version of org.apache.commons:commons-pool2 or commons-pool:commons-pool5. Now, given the <gate:duplicate id="theApp"> definition from the previous section we can create a DocumentProcessor proxy that can handle up to five concurrent requests as follows:
<bean id="processor" class="gate.util.LanguageAnalyserDocumentProcessor"> <property name="analyser" ref="theApp" /> <gate:pooled-proxy max-size="5" /> </bean>
The <gate:pooled-proxy> element decorates a singleton bean definition. It converts the original definition to prototype scope and replaces it with a singleton proxy delegating to a pool of instances of the prototype bean. The pool parameters are controlled by attributes of the <gate:pooled-proxy> element, the most important ones being:
-
max-size
-
The maximum size of the pool. If more than this number of threads try to call methods on the proxy at the same time, the others will (by default) block until an object is returned to the pool.
-
initial-size
-
The default behaviour of Spring’s pooling tools is to create instances in the pool on demand (up to the max-size). This attribute instead causes initial-size instances to be created up-front and added to the pool when it is first created.
-
when-exhausted-action-name
-
What to do when the pool is exhausted (i.e. there are already max-size concurrent calls in progress and another one arrives). Should be set to one of WHEN_EXHAUSTED_BLOCK (the default, meaning block the excess requests until an object becomes free), WHEN_EXHAUSTED_GROW (create a new object anyway, even though this pushes the pool beyond max-size) or WHEN_EXHAUSTED_FAIL (cause the excess calls to fail with an exception).
Any of these attributes can make use of the usual ${...} property placeholder mechanism. Many more options are available, corresponding to the properties of the underlying Spring TargetSource in use (by default, a slightly customised subclass of CommonsPool2TargetSource or CommonsPoolTargetSource, depending which version of commons-pool you depend on). These allow you, for example, to configure a pool that dynamically grows and shrinks as necessary, releasing objects that have been idle for a set amount of time. See the JavaDoc documentation of CommonsPoolTargetSource (and the documentation for Apache commons-pool) for full details. If you wish to use a different TargetSource implementation from the default you can provide a target-source-class attribute with the fully-qualified class name of the class you wish to use (which must, of course, implement the TargetSource interface).
Note that the <gate:pooled-proxy> technique is not tied to GATE in any way, it is simply an easy way to configure standard Spring beans and can be used with any bean that needs to be pooled, not just objects that make use of GATE.
7.15.3 Further reading [#]
These custom elements all define various factory beans. For full details, see the JavaDocs for the gate-spring module. The main Spring framework API documentation is the best place to look for more detail on the pooling facilities provided by Spring AOP.
7.16 Groovy for GATE [#]
Groovy is a dynamic programming language based on Java. Groovy is not used in the core GATE distribution, so to enable the Groovy features in GATE you must first load the Groovy plugin. Loading this plugin:
-
provides access to the Groovy scripting console (configured with some extensions for GATE) from the GATE Developer “Tools” menu.
-
provides a PR to run a Groovy script over documents.
-
provides a controller which uses a Groovy DSL to define its execution strategy.
-
enhances a number of core GATE classes with additional convenience methods that can be used from any Groovy code including the console, the script PR, and any Groovy class that uses the GATE Embedded API.
This section describes these features in detail, but assumes that the reader already has some knowledge of the Groovy language. If you are not already familiar with Groovy you should read this section in conjunction with Groovy’s own documentation at http://groovy.codehaus.org/.
7.16.1 Groovy Scripting Console for GATE [#]
Loading the Groovy plugin in GATE Developer will provide a “Groovy Console” item in the Tools/Groovy Tools menu. This menu item opens the standard Groovy console window (http://groovy.codehaus.org/Groovy+Console).
To help scripting GATE in Groovy, the console is pre-configured to import all classes from the gate and gate.util packages of the core GATE API. This means you can refer to classes and interfaces such as Factory, AnnotationSet, Gate, etc. without needing to prefix them with a package name. In addition, the following (read-only) variable bindings are pre-defined in the Groovy Console.
-
corpora: a list of loaded corpora LRs (Corpus)
-
docs: a list of all loaded document LRs (DocumentImpl)
-
prs: a list of all loaded PRs
-
apps: a list of all loaded Applications (AbstractController)
These variables are automatically updated as resources are created and deleted in GATE.
Here’s an example script. It finds all documents with a feature “annotator” set to “fred”, and puts them in a new corpus called “fredsDocs”.
You can find other examples (and add your own) in the Groovy script repository on the GATE Wiki: http://gate.ac.uk/wiki/groovy-recipes/.
Why won’t the ‘Groovy executing’ dialog go away? Sometimes, when you execute a Groovy script through the console, a dialog will appear, saying “Groovy is executing. Please wait”. The dialog fails to go away even when the script has ended, and cannot be closed by clicking the “Interrupt” button. You can, however, continue to use the Groovy Console, and the dialog will usually go away next time you run a script. This is not a GATE problem: it is a Groovy problem.
7.16.2 Groovy scripting PR [#]
The Groovy scripting PR enables you to load and execute Groovy scripts as part of a GATE application pipeline. The Groovy scripting PR is made available when you load the Groovy plugin via the plugin manager.
Parameters [#]
The Groovy scripting PR has a single initialisation parameter
-
scriptURL: the path to a valid Groovy script
It has three runtime parameters
-
inputASName: an optional annotation set intended to be used as input by the PR (but note that the PR has access to all annotation sets)
-
outputASName: an optional annotation set intended to be used as output by the PR (but note that the PR has access to all annotation sets)
-
scriptParams: optional parameters for the script. In a creole.xml file, these should be specified as key=value pairs, each pair separated by a comma. For example: ’name=fred,type=person’ . In the GATE GUI, these are specified via a dialog.
Script bindings [#]
As with the Groovy console described above Groovy scripts run by the scripting PR implicitly import all classes from the gate and gate.util packages of the core GATE API. The Groovy scripting PR also makes available the following bindings, which you can use in your scripts:
-
doc: the current document (Document)
-
corpus: the corpus containing the current document
-
controller: the controller running the script
-
content: the string content of the current document
-
inputAS: the annotation set specified by inputASName in the PRs runtime parameters
-
outputAS: the annotation set specified by outputASName in the PRs runtime parameters
Note that inputAS and outputAS are intended to be used as input and output AnnotationSets. This is, however, a convention: there is nothing to stop a script writing to or reading from any AnnotationSet. Also, although the script has access to the corpus containing the document it is running over, it is not generally necessary for the script to iterate over the documents in the corpus itself – the reference is provided to allow the script to access data stored in the FeatureMap of the corpus. Any other variables assigned to within the script code will be added to the binding, and values set while processing one document can be used while processing a later one.
Passing parameters to the script [#]
In addition to the above bindings, one further binding is available to the script:
-
scriptParams: a FeatureMap with keys and values as specified by the scriptParams runtime parameter
For example, if you were to create a scriptParams runtime parameter for your PR, with the keys and values: ’name=fred,type=person’, then the values could be retrieved in your script via scriptParams.name and scriptParams.type. If you populate the scriptParams FeatureMap programmatically, the values will of course have the same types inside the Groovy script, but if you create the FeatureMap with GATE Developer’s parameter editor, the keys and values will all have String type. (If you want to set n=3 in the GUI editor, for example, you can use scriptParams.n as Integer in the Groovy script to obtain the Integer type.)
Controller callbacks [#]
A Groovy script may wish to do some pre- or post-processing before or after processing the documents in a corpus, for example if it is collecting statistics about the corpus. To support this, the script can declare methods beforeCorpus and afterCorpus, taking a single parameter. If the beforeCorpus method is defined and the script PR is running in a corpus pipeline application, the method will be called before the pipeline processes the first document. Similarly, if the afterCorpus method is defined it will be called after the pipeline has completed processing of all the documents in the corpus. In both cases the corpus will be passed to the method as a parameter. If the pipeline aborts with an exception the afterCorpus method will not be called, but if the script declares a method aborted(c) then this will be called instead.
Note that because the script is not processing a particular document when these methods are called, the usual doc, corpus, inputAS, etc. are not available within the body of the methods (though the corpus is passed to the method as a parameter). The scriptParams and controller variables are available.
The following example shows how this technique could be used to build a simple tf/idf index for a GATE corpus. The example is available in the GATE distribution as plugins/Groovy/resources/scripts/tfidf.groovy. The script makes use of some of the utility methods described in section 7.16.4.
2void beforeCorpus(c) {
3 // list of maps (one for each doc) from term to frequency
4 frequencies = []
5 // sorted map from term to docs that contain it
6 docMap = new TreeMap()
7 // index of the current doc in the corpus
8 docNum = 0
9}
10
11// start frequency list for this document
12frequencies << [:]
13
14// iterate over the requested annotations
15inputAS[scriptParams.annotationType].each {
16 def str = doc.stringFor(it)
17 // increment term frequency for this term
18 frequencies[docNum][str] =
19 (frequencies[docNum][str] ?: 0) + 1
20
21 // keep track of which documents this term appears in
22 if(!docMap[str]) {
23 docMap[str] = new LinkedHashSet()
24 }
25 docMap[str] << docNum
26}
27
28// normalize counts by doc length
29def docLength = inputAS[scriptParams.annotationType].size()
30frequencies[docNum].each { freq ->
31 freq.value = ((double)freq.value) / docLength
32}
33
34// increment the counter for the next document
35docNum++
36
37// compute the IDFs and store the table as a corpus feature
38void afterCorpus(c) {
39 def tfIdf = [:]
40 docMap.each { term, docsWithTerm ->
41 def idf = Math.log((double)docNum / docsWithTerm.size())
42 tfIdf[term] = [:]
43 docsWithTerm.each { docId ->
44 tfIdf[term][docId] = frequencies[docId][term] * idf
45 }
46 }
47 c.features.freqTable = tfIdf
48}
Examples [#]
The plugin directory Groovy/resources/scripts contains some example scripts. Below is the code for a naive regular expression PR.
2matcher = content =~ scriptParams.regex
3while(matcher.find())
4 outputAS.add(matcher.start(),
5 matcher.end(),
6 scriptParams.type,
7 Factory.newFeatureMap())
The script needs to have the runtime parameter scriptParams set with keys and values as follows:
-
regex: the Groovy regular expression that you want to match e.g. [^\s]*ing
-
type: the type of the annotation to create for each regex match, e.g. regexMatch
When the PR is run over a document, the script will first make a matcher over the document content for the regular expression given by the regex parameter. It will iterate over all matches for this regular expression, adding a new annotation for each, with a type as given by the type parameter.
7.16.3 The Scriptable Controller [#]
The Groovy plugin’s “Scriptable Controller” is a more flexible alternative to the standard pipeline (SerialController) and corpus pipeline (SerialAnalyserController) applications and their conditional variants, and also supports the time limiting and robustness features of the realtime controller. Like the standard controllers, a scriptable controller contains a list of processing resources and can optionally be configured with a corpus, but unlike the standard controllers it does not necessarily execute the PRs in a linear order. Instead the execution strategy is controlled by a script written in a Groovy domain specific language (DSL), which is detailed in the following sections.
Running a single PR
To run a single PR from the scriptable controller’s list of PRs, simply use the PR’s name as a Groovy method call:
If the PR’s name contains spaces or any other character that is not valid in a Groovy identifier, or if the name is a reserved word (such as “import”) then you must enclose the name in single or double quotes. You may prefer to rename the PRs so their names are valid identifiers. Also, if there are several PRs in the controller’s list with the same name, they will all be run in the order in which they appear in the list.
You can optionally provide a Map of named parameters to the call, and these will override the corresponding runtime parameter values for the PR (the original values will be restored after the PR has been executed):
Iterating over the corpus
If a corpus has been provided to the controller then you can iterate over all the documents in the corpus using eachDocument:
The block of code (in fact a Groovy closure) is executed once for each document in the corpus exactly as a standard corpus pipeline application would operate. The current document is available to the script in the variable doc and the corpus in the variable corpus, and in addition any calls to PRs that implement the LanguageAnalyser interface will set the PR’s document and corpus parameters appropriately.
Running all the PRs in sequence
Calling allPRs() will execute all the controller’s PRs once in the order in which they appear in the list. This is rarely useful in practice but it serves to define the default behaviour: the initial script that is used by default in a newly instantiated scriptable controller is eachDocument { allPRs() }, which mimics the behaviour of a standard corpus pipeline application.
More advanced scripting
The basic DSL is extremely simple, but because the script is Groovy code you can use all the other facilities of the Groovy language to do conditional execution, grouping of PRs, etc. The control script has the same implicit imports as provided by the Groovy Script PR (section 7.16.2), and additional import statements can be added as required.
For example, suppose you have a pipeline for multi-lingual document processing, containing PRs named “englishTokeniser”, “englishGazetteer”, “frenchTokeniser”, “frenchGazetteer”, “genericTokeniser”, etc., and you need to choose which ones to run based on a document feature:
2 def lang = doc.features.language ?: ’generic’
3 "${lang}Tokeniser"()
4 "${lang}Gazetteer"()
5}
As another example, suppose you have a particular JAPE grammar that you know is slow on documents that mention a large number of locations, so you only want to run it on documents with up to 100 Location annotations, and use a faster but less accurate one on others:
2void annotateLocations() {
3 tokeniser()
4 splitter()
5 gazetteer()
6 locationGrammar()
7}
8
9eachDocument {
10 annotateLocations()
11 if(doc.annotations["Location"].size() <= 100) {
12 fullLocationClassifier()
13 }
14 else {
15 fastLocationClassifier()
16 }
17}
You can have more than one call to eachDocument, for example a controller that pre-processes some documents, then collects some corpus-level statistics, then further processes the documents based on those statistics.
As a final example, consider a controller to post-process data from a manual annotation task. Some of the documents have been annotated by one annotator, some by more than one (the annotations are in sets named “annotator1”, “annotator2”, etc., but the number of sets varies from document to document).
2 // find all the annotatorN sets on this document
3 def annotators =
4 doc.annotationSetNames.findAll {
5 it ==~ /annotator\d+/
6 }
7
8 // run the post−processing JAPE grammar on each one
9 annotators.each { asName ->
10 postProcessingGrammar(
11 inputASName: asName,
12 outputASName: asName)
13 }
14
15 // now merge them to form a consensus set
16 mergingPR(annSetsForMerging: annotators.join(’;’))
17}
Nesting a scriptable controller in another application
Like the standard SerialAnalyserController, the scriptable controller implements the LanugageAnalyser interface and so can itself be nested as a PR in another pipeline. When used in this way, eachDocument does not iterate over the corpus but simply calls its closure once, with the “current document” set to the document that was passed to the controller as a parameter. This is the same logic as is used by SerialAnalyserController, which runs its PRs once only rather than once per document in the corpus.
Global variables
There are a number of variables that are pre-defined in the control script.
-
controller
-
(read-only) a reference to the ScriptableController object itself, providing access to its features etc.
-
prs
-
(read-only) an unmodifiable list of the processing resources in the pipeline.
-
corpus
-
(read-write) a reference to the corpus (if any) currently set on the controller, and over which any eachDocument loops will iterate. This variable is a direct “alias” to the controller’s getCorpus/setCorpus methods, so for example a script could build a new corpus (using a web crawler or similar), then use eachDocument to iterate over this corpus and process the documents.
In addition, as mentioned above, within the scope of an eachDocument loop there is a “doc” variable giving access to the document being processed in the current iteration. Note that if this controller is nested inside another controller (see the previous section) then the “doc” variable will be available throughout the script.
Ignoring errors
By default, if an exception or error occurs while processing (either thrown by a PR or occurring directly within the controller’s script) then the controller’s execution will terminate with an exception. If this occurs during an eachDocument then the remaining documents will not be processed. In some circumstances it may be preferable to ignore the error and simply continue with the next document. To support this you can use ignoringErrors:
Any exceptions or errors thrown within the ignoringErrors block will be logged6 but not rethrown. So in the example above if myTransducer fails with an exception the controller will continue with the next document. Note that it is important to nest the blocks correctly – if the nesting were reversed (with the eachDocument inside the ignoringErrors) then an exception would terminate the whole eachDocument loop and the remaining documents would not be processed.
Realtime behaviour
Some GATE processing resources can be very slow when operating on large or complex documents. In many cases it is possible to use heuristics within your controller’s script to spot likely “problem” documents and avoid running such PRs over them (see the fast vs. full location classifier example above), but for situations where this is not possible you can use the timeLimit method to put a blanket limit on the time that PRs will be allowed to consume, in a similar way to the real-time controller.
2 ignoringErrors {
3 annotateLocations()
4 timeLimit(soft:30.seconds, hard:30.seconds) {
5 classifyLocations()
6 }
7 }
8}
A call to timeLimit will attempt to limit the running time of its associated code block. You can specify three different kinds of limit:
-
soft
-
if the block is still executing after this time, attempt to interrupt it gently. This uses Thread.interrupt() and also calls the interrupt() method of the currently executing PR (if any).
-
exception
-
if the block is still executing after this time beyond the soft limit, attempt to induce an exception by setting the corpus and document parameters of the currently running PR to null. This is useful to deal with PRs that do not properly respect the interrupt call.
-
hard
-
if the block is still executing after this time beyond the previous limit, forcibly terminate it using Thread.stop. This is inherently dangerous and prone to memory leakage but may be the only way to stop particularly stubborn PRs. It should be used with caution.
Limits can be specified using Groovy’s TimeCategory notation as shown above (e.g. 10.seconds, 2.minutes, 1.minute+45.seconds), or as simple numbers (of milliseconds). Each limit starts counting from the end of the last, so in the example above the hard limit is 30 seconds after the soft limit, or 1 minute after the start of execution. If no hard limit is specified the controller will wait indefinitely for the block to complete.
Note also that when a timeLimit block is terminated it will throw an exception. If you do not wish this exception to terminate the execution of the controller as a whole you will need to wrap the timeLimit block in an ignoringErrors block.
timeLimit blocks, particularly ones with a hard limit specified, should be regarded as a last resort – if there are heuristic methods you can use to avoid running slow PRs in the first place it is a good idea to use them as a first defence, possibly wrapping them in a timeLimit block if you need hard guarantees (for example when you are paying per hour for your compute time in a cloud computing system).
The Scriptable Controller in GATE Developer
When you double-click on a scriptable controller in the resources tree of GATE Developer you see the same controller editor that is used by the standard controllers. This view allows you to add PRs to the controller and set their default runtime parameter values, and to specify the corpus over which the controller should run. A separate view is provided to allow you to edit the Groovy script, which is accessible via the “Control Script” tab (see figure 7.2). This tab provides a text editor which does basic Groovy syntax highlighting (the same editor used by the Groovy Console).
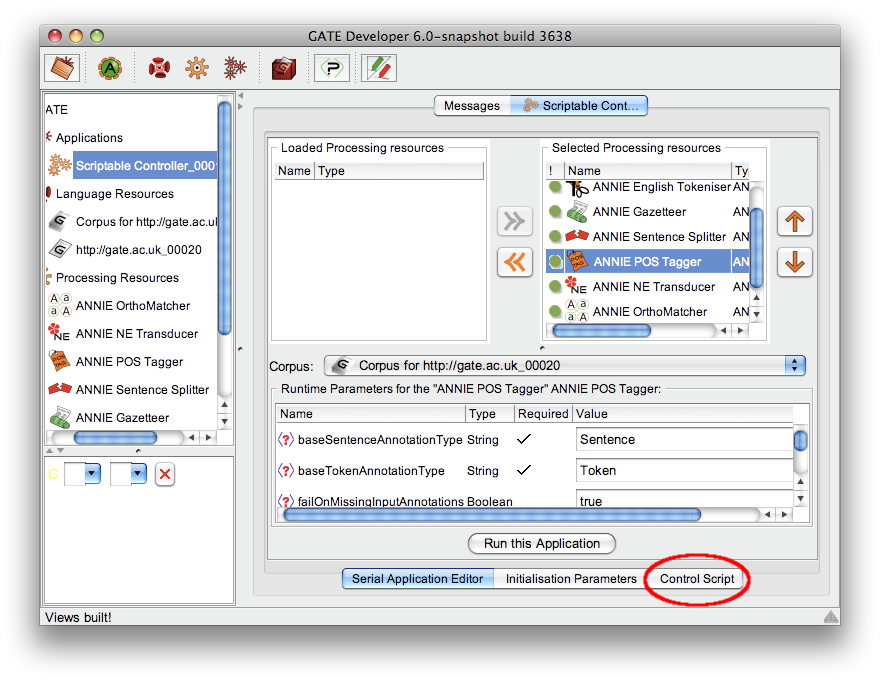
7.16.4 Utility methods [#]
Loading the Groovy plugin adds some additional methods to several of the core GATE API classes and interfaces using the Groovy “mixin” mechanism. Any Groovy code that runs after the plugin has been loaded can make use of these additional methods, including snippets run in the Groovy console, scripts run using the Script PR, and any other Groovy code that uses the GATE Embedded API.
The methods that are injected come from two classes. The gate.Utils class (part of the core GATE API in gate.jar) defines a number of static methods that can be used to simplify common tasks such as getting the string covered by an annotation or annotation set, finding the start or end offset of an annotation (or set), etc. These methods do not use any Groovy-specific types, so they are usable from pure Java code in the usual way as well as being mixed in for use in Groovy. Additionally, the class gate.groovy.GateGroovyMethods (part of the Groovy plugin) provides methods that use Groovy types such as closures and ranges.
The added methods include:
-
Unified access to the start and end offsets of an Annotation, AnnotationSet or Document: e.g. someAnnotation.start() or anAnnotationSet.end()
-
Simple access to the DocumentContent or string covered by an annotation or annotation set: document.stringFor(anAnnotation), document.contentFor(annotationSet)
-
Simple access to the length of an annotation or document, either as an int (annotation.length()) or a long (annotation.lengthLong()).
-
A method to construct a FeatureMap from any map, to support constructions like def params = [sourceUrl:’http://gate.ac.uk’, encoding:’UTF-8’].toFeatureMap()
-
A method to convert an annotation set into a List of annotations in the order they appear in the document, for iteration in a predictable order: annSet.inDocumentOrder().collect { it.type }
-
The each, eachWithIndex and collect methods for a corpus have been redefined to properly load and unload documents if the corpus is stored in a datastore.
-
Various getAt methods to support constructions like annotationSet["Token"] (get all Token annotations from the set), annotationSet[15..20] (get all annotations between offsets 15 and 20), documentContent[0..10] (get the document content between offsets 0 and 10).
-
A withResource method for any resource, which calls a closure with the resource passed as a parameter, and ensures that the resource is properly deleted when the closure completes (analagous to the default Groovy method InputStream.withStream).
For full details, see the source code or javadoc documentation for these two classes.
7.17 Saving Config Data to gate.xml
Arbitrary feature/value data items can be saved to the user’s gate.xml file via the following API calls:
To get the config data: Map configData = Gate.getUserConfig().
To add config data simply put pairs into the map: configData.put("my new config key", "value");.
To write the config data back to the XML file: Gate.writeUserConfig();.
Note that new config data will simply override old values, where the keys are the same. In this way defaults can be set up by putting their values in the main gate.xml file, or the site gate.xml file; they can then be overridden by the user’s gate.xml file.
7.18 Annotation merging through the API [#]
If we have annotations about the same subject on the same document from different annotators, we may need to merge those annotations to form a unified annotation. Two approaches for merging annotations are implemented in the API, via static methods in the class gate.util.AnnotationMerging.
The two methods have very similar input and output parameters. Each of the methods takes an array of annotation sets, which should be the same annotation type on the same document from different annotators, as input. A single feature can also be specified as a parameter (or given asnull if no feature is to be specified).
The output is a map, the key of which is one merged annotation and the value of which represents the annotators (in terms of the indices of the array of annotation sets) who support the annotation. The methods also have a boolean input parameter to indicate whether or not the annotations from different annotators are based on the same set of instances, which can be determined by the static method public boolean isSameInstancesForAnnotators(AnnotationSet[] annsA) in the class gate.util.IaaCalculation. One instance corresponds to all the annotations with the same span. If the annotation sets are based on the same set of instances, the merging methods will ensure that the merged annotations are on the same set of instances.
The two methods corresponding to those described for the Annotation Merging plugin described in Section 23.18. They are:
-
The Method public static void mergeAnnotation(AnnotationSet[] annsArr, String nameFeat, HashMap<Annotation,String>mergeAnns, int numMinK, boolean isTheSameInstances) merges the annotations stored in the array annsArr. The merged annotation is put into the map mergeAnns, with a key of the merged annotation and value of a string containing the indices of elements in the annotation set array annsArr which contain that annotation. NumMinK specifies the minimal number of the annotators supporting one merged annotation. The boolean parameter isTheSameInstances indicate if or not those annotation sets for merging are based on the same instances.
-
Method public static void mergeAnnotationMajority(AnnotationSet[] annsArr, String nameFeat, HashMap<Annotation, String>mergeAnns, boolean isTheSameInstances) selects the annotations which the majority of the annotators agree on. The meanings of parameters are the same as those in the above method.
7.19 Using Resource Helpers to Extend the API [#]
Resource Helpers (see Section 4.8.2) are an easy way of adding new features to existing resources within GATE Developer. Currently most Resource Helpers provide additional ways of loading or exporting documents, and it would also be useful to have the same features available via the API. While you could compile embedded code against the plugin classes or use reflection, this can quickly become difficult to manage, and rather negates the whole plugin philosophy. Fortunately the Resource Helper API makes it easy to access these new features from embedded code.
Here is a pseudo example:
2ResourceHelper rh =
3 (ResourceHelper)Gate.getCreoleRegister()
4 .getAllInstances("gate.example.ResourceHelperExample").iterator()
5 .next();
6
7// create a simple test document
8Document doc =
9 Factory.newDocument("A test of the Resource Handler API access");
10
11// use the Resource Helper to "analyse" the document
12rh.call("analyse", doc);
The comments should make the code fairly self-explanatory, but the main feature is on line 12 which uses the ResourceHandler.call(String, Resource, Object...) method. This essentially allows you to call a named method of the Resource Helper (in the example “analyse”), for a given Resource instance (here we are using a Document instance), supplying any necessary parameters. This allows you to access any public instance method of a Resource Helper that takes a Resource as it’s first parameter.
The only downside to this approach is that there is no compile time checking that the method you are trying to call actually exists or that the parameters are of the correct type so testing is important.
7.20 Converting a Directory Plugin to a Maven Plugin [#]
Prior to GATE version 8.5 plugins were distributed as direcories containing a creole.xml at their root. This approach was fragile (required relative paths for dependencies etc.) and did not properly support versioning making it difficult to gurantee reproducability. From GATE version 8.5 onwards the recommended way to both build and distribute plugins is via the Apache Maven build tool. In this approach a plugin is represented by a JAR file containing the compiled code, default resources, and CREOLE metadata. For best results you should use Maven 3.5.2 or later.
As discussed in Section 7.12 GATE provides a Maven archetype to create the skeleton of a new plugin. That example contains a sample processing resource. We also provide an archetype which produces an empty plugin and which can easy the process of converting a directory plugin to a new Maven style plugin. To use this archetype run the following Maven command (which has been split over several lines for clarity, but should be run as a single command):
mvn archetype:generate -DarchetypeGroupId=uk.ac.gate \ -DarchetypeArtifactId=gate-plugin-archetype \ -DarchetypeVersion=8.5
Replace “8.5” with the version of gate-core that you wish to depend on. You will be prompted for several values by Maven:
-
groupId
-
the group ID to use in the generated project POM. In Maven terms a “group” is a set of related JARs maintained and released by the same developer or group – conventionally this is based on the same convention as Java package names, using a reversed form of a DNS domain you own. You can use any value you like here, except that you should not use a group ID starting uk.ac.gate, as that is reserved for core plugins from the GATE team.
-
artifactId
-
the artifact ID for the generated project POM – this will be used as the directory name for the new project on disk and as the first part of the name of the final JAR file.
-
version
-
the initial version number for your new plugin – this should always end with -SNAPSHOT in capital letters, which is a Maven convention denoting work-in-progress code where the same version number can refer to different JAR files over time. The Maven dependency mechanism assumes that only -SNAPSHOT versions can ever change, and JAR files for non-SNAPSHOT versions are immutable and can be cached forever.
Once the directory structure has been corrected existing code and resources can be copied in from your old directory based plugin as follows:
-
Source Code
-
should be copied into src/main/java or src/test/java as appropriate
-
Resources
-
should be copied into src/main/resources/resources. Note that the repeated directory name is deliberate to ensure that any resources end up in a folder called resources at the root of the plugin JAR file.
Code libraries (usually found in lib in directory plugins) are now handled via Maven and so do not need to be transfered over from the old plugin but should be detailed in the Maven pom.xml file. See Section 7.12 for full details on developing a Maven based plugin, all of which applies to upgrading a plugin once the source and resources have been copied into the correct directory structure.
One other recommendation when converting a plugin is to switch from using URL as a parameter type to using ResourceReference as these allow users to easily access resources inside plugins. See Section 12.3.2 for details on how to use ResourceReference values within your plugins.
1CREOLE stands for Collection of REusable Objects for Language Engineering
2Fully qualified name: gate.Factory
3Alternatively a string giving the document source may be provided.
4In the common case where the getter/setter pair are simple accessors for a private field whose name matches the Java Bean property name, the annotation may be applied to the field rather than to the setter.
5Spring 5 no longer supports commons-pool version 1
6to the gate.groovy.ScriptableController Log4J logger
