Chapter 23
More (CREOLE) Plugins [#]
This chapter describes additional CREOLE resources which do not form part of ANNIE, and have not been covered in previous chapters.
23.1 Verb Group Chunker [#]
The rule-based verb chunker is based on a number of grammars of English [Cobuild 99, Azar 89]. We have developed 68 rules for the identification of non recursive verb groups. The rules cover finite (’is investigating’), non-finite (’to investigate’), participles (’investigated’), and special verb constructs (’is going to investigate’). All the forms may include adverbials and negatives. The rules have been implemented in JAPE. The finite state analyser produces an annotation of type ‘VG’ with features and values that encode syntactic information (‘type’, ‘tense’, ‘voice’, ‘neg’, etc.). The rules use the output of the POS tagger as well as information about the identity of the tokens (e.g. the token ‘might’ is used to identify modals).
The grammar for verb group identification can be loaded as a Jape grammar into the GATE architecture and can be used in any application: the module is domain independent. The grammar file is located within the ANNIE plugin, in the directory plugins/ANNIE/resources/VP.
23.2 Noun Phrase Chunker [#]
The NP Chunker application is a Java implementation of the Ramshaw and Marcus BaseNP chunker (in fact the files in the resources directory are taken straight from their original distribution) which attempts to insert brackets marking noun phrases in text which have been marked with POS tags in the same format as the output of Eric Brill’s transformational tagger. The output from this version should be identical to the output of the original C++/Perl version released by Ramshaw and Marcus.
For more information about baseNP structures and the use of transformation-based learning to derive them, see [Ramshaw & Marcus 95].
For the GATE Cloud version of the NP chunker, see:
https://cloud.gate.ac.uk/shopfront/displayItem/noun-phrase-chunker
23.2.1 Differences from the Original
The major difference is the assumption is made that if a POS tag is not in the mapping file then it is tagged as ‘I’. The original version simply failed if an unknown POS tag was encountered. When using the GATE wrapper the chunk tag can be changed from ‘I’ to any other legal tag (B or O) by setting the unknownTag parameter.
23.2.2 Using the Chunker
The Chunker requires the Creole plugin ‘Parser_NP_Chunking’ to be loaded. The two loadtime parameters are simply urls pointing at the POS tag dictionary and the rules file, which should be set automatically. There are five runtime parameters which should be set prior to executing the chunker.
-
annotationName: name of the annotation the chunker should create to identify noun phrases in the text.
-
inputASName: The chunker requires certain types of annotations (e.g. Tokens with part of speech tags) for identifying noun chunks. This parameter tells the chunker which annotation set to use to obtain such annotations from.
-
outputASName: This is where the results (i.e. new noun chunk annotations will be stored).
-
posFeature: Name of the feature that holds POS tag information. ’
-
unknownTag: it works as specified in the previous section.
The chunker requires the following PRs to have been run first: tokeniser, sentence splitter, POS tagger.
23.3 TaggerFramework [#]
The Tagger Framework is an extension of work originally developed in order to provide support for the TreeTagger plugin within GATE. Rather than focusing on providing support for a single external tagger this plugin provides a generic wrapper that can easily be customised (no Java code is required) to incorporate many different taggers within GATE.
The plugin currently provides example applications (see plugins/Tagger_Framework/resources) for the following taggers: GENIA (a biomedical tagger), Hunpos (providing support for English and Hungarian), TreeTagger (supporting German, French, Spanish and Italian as well as English), and the Stanford Tagger (supporting English, German and Arabic).
The basic idea behind this plugin is to allow the use of many external taggers. Providing such a generic wrapper requires a few assumptions. Firstly we assume that the external tagger will read from a file and that the contents of this file will be one annotation per line (i.e. one token or sentence per line). Secondly we assume that the tagger will write it’s response to stdout and that it will also be based on one annotation per line – although there is no assumption that the input and output annotation types are the same.
An important issue with most external taggers is tokenisation: Generally, when using a native GATE tagger in a pipeline, “Token” annotations are first generated by a tokeniser, and then processed by a POS tagger. Most external taggers, on the other hand, have built-in code to perform their own tokenisation. In this case, there are generally two options: (1) use the tokens generated by the external tagger and import them back into GATE (typically into a “Token” annotation type). Or (2), if the tagger accepts pre-tokenised text, the Tagger Framework can be configured to pass the annotations as generated by a GATE tokeniser to the external tagger. For details on this, please refer to the ‘updateAnnotations’ runtime parameter described below. However, if the tokenisation strategies are significantly different, this may lead to a degradation of the tagger’s performance.
-
Initialization Parameters
-
preProcessURL: The URL of a JAPE grammar that should be run over each document before running the tagger.
-
postProcessURL: The URL of a JAPE grammar that should be run over each document after running the tagger. This can be used, for example, to add chunk annotations using IOB tags output by the tagger and stored as features on Token annotations.
-
-
Runtime Parameters
-
debug: if set to true then a whole heap of useful information will be printed to the messages tab as the tagger runs. Defaults to false.
-
encoding: this must be set to the encoding that the tagger expects the input/output files to use. If this is incorrectly set is highly likely that either the tagger will fail or the results will be meaningless. Defaults to ISO-8859-1 as this seems to be the most commonly required encoding.
-
failOnUnmappableCharacter: What to do if a character is encountered in the document which cannot be represented in the selected encoding. If the parameter is true (the default), unmappable characters cause the wrapper to throw an exception and fail. If set to false, unmappable characters are replaced by question marks when the document is passed to the tagger. This is useful if your documents are largely OK but contain the odd character from outside the Latin-1 range.
-
failOnMissingInputAnnotations: if set to false, the PR will not fail with an ExecutionException if no input Annotations are found and instead only log a single warning message per session and a debug message per document that has no input annotations (default = true).
-
inputTemplate: template string describing how to build the line of input for the tagger corresponding to a single annotation. The template contains placeholders of the form ${feature} which will be replaced by the value of the corresponding feature from the annotation. The default template is ${string}, which simply passes the string feature of each annotation to the tagger. Typical variants would be ${string}\t${category} for an entity tagger that requires the string and the part of speech tag for each token, separated by a tab1. If a particular annotation does not have one of the specified features, the corresponding slot in the template will be left blank (i.e. replaced by an empty string). It is only an error if a particular annotation contains none of the features specified by the template.
-
regex: this should be a Java regular expression that matches a single line in the output from the tagger. Capturing groups should be used to define the sections of the expression which match the useful output.
-
featureMapping: this is a mapping from feature name to capturing group in the regular expression. Each feature will be added to the output annotations with a value equal to the specified capturing group. For example, the TreeTagger uses a regular expression (.+)\t(.+)\t(.+) to capture the three column output. This is then combined with the feature mapping {string=1, category=2, lemma=3} to add the appropriate feature/values to the output annotations.
-
inputASName: the name of the annotation set which should be used for input. If not specified the default (i.e. un-named) annotation set will be used.
-
inputAnnotationType: the name of the annotation used as input to the tagger. This will usually be Token. Note that the input annotations must contain a string feature which will be used as input to the tagger. Tokens usually have this feature but if, for example, you wish to use Sentence as the input annotation then you will need to add the string feature. JAPE grammars for doing this are provided in plugins/Tagger_Framework/resources.
-
outputASName: the name of the annotation set which should be used for output. If not specified the default (i.e. un-named) annotation set will be used.
-
outputAnnotationType: the name of the annotation to be provided as output. This is usually Token.
-
taggerBinary: a URL indicating the location of the external tagger. This is usually a shell script which may perform extra processing before executing the tagger. The plugins/Tagger_Framework/resources directory contains example scripts (where needed) for the supported taggers. These scripts may need editing (for example, to set the installation directory of the tagger) before they can be used.
-
taggerDir: the directory from which the tagger must be executed. This can be left unspecified.
-
taggerFlags: an ordered set of flags that should be passed to the tagger as command line options
-
updateAnnotations: If set to true then the plugin will attempt to update existing output annotations. This can fail if the output from the tagger and the existing annotations are created differently (i.e. the tagger does its own tokenization). Setting this option to false will make the plugin create new output annotations, removing any existing ones, to prevent the two sets getting out of sync. This is also useful when the tagger is domain specific and may do a better job than GATE. For example, the GENIA tagger is better at tokenising biomedical text than the ANNIE tokeniser. Defaults to true.
-
By default the GenericTagger PR simply tries to execute the taggerBinary using the normal Java Runtime.exec() mechanism. This works fine on Unix-style platforms such as Linux or Mac OS X, but on Windows it will only work if the taggerBinary is a .exe file. Attempting to invoke other types of program fails on Windows with a rather cryptic “error=193”.
To support other types of tagger programs such as shell scripts or Perl scripts, the GenericTagger PR supports a Java system property shell.path. If this property is set then instead of invoking the taggerBinary directly the PR will invoke the program specified by shell.path and pass the tagger binary as the first command-line parameter.
If the tagger program is a shell script then you will need to install the appropriate interpreter, such as sh.exe from the cygwin tools, and set the shell.path system property to point to sh.exe. For GATE Developer you can do this by adding the following line to build.properties (see Section 2.3, and note the extra backslash before each backslash and colon in the path):
run.shell.path: C\:\\cygwin\\bin\\sh.exe
Similarly, for Perl or Python scripts you should install a suitable interpreter and set shell.path to point to that.
You can also run taggers that are invoked using a Windows batch file (.bat). To use a batch file you do not need to use the shell.path system property, but instead set the taggerBinary runtime parameter to point to C:\WINDOWS\system32\cmd.exe and set the first two taggerFlags entries to “/c” and the Windows-style path to the tagger batch file (e.g. C:\MyTagger\runTagger.bat). This will cause the PR to run cmd.exe /c runTagger.bat which is the way to run batch files from Java.
In general most of the complexities of configuring a number of external taggers has already been determined and example pipelines are provided in the plugin’s resources directory. To use one of the supported taggers simply load one of the exampl applications and then check the runtime parameters of the Tagger_Framework PR in order to set paths correctly to your copy of the tagger you wish to use.
Some taggers require more complex configuration, details of which are covered in the remainder of this section.
23.3.1 TreeTagger—Multilingual POS Tagger [#]
The TreeTagger is a language-independent part-of-speech tagger, which supports a number of different languages through parameter files, including English, French, German, Spanish, Italian and Bulgarian. Originally made available in GATE through a dedicated wrapper, it is now fully supported through the Tagger Framework. You must install the TreeTagger separately from
http://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger/DecisionTreeTagger.html
Avoid installing it in a directory that contains spaces in its path.
Tokenisation and Command Scripts. When running the TreeTagger through the Tagger Framework, you can choose between passing Tokens generated within GATE to the TreeTagger for POS tagging or let the TreeTagger perform tokenisation as well, importing the generated Tokens into GATE annotations. If you need to pass the Tokens generated by GATE to the TreeTagger, it is important that you create your own command scripts to skip the tokenisation step done by default in the TreeTagger command scripts (the ones in the TreeTagger’s cmd directory). A few example scripts for passing GATE Tokens to the TreeTagger are available under plugins/Tagger_Framework/resources/TreeTagger, for example, tree-tagger-german-gate runs the German parameter file with existing “Token” annotations.
Note that you must set the paths in these command files to point to the location where you installed the TreeTagger:
BIN=/usr/local/durmtools/TreeTagger/bin CMD=/usr/local/durmtools/TreeTagger/cmd LIB=/usr/local/durmtools/TreeTagger/lib
The Tagger Framework will run the TreeTagger on any platform that supports the TreeTagger tool, including Linux, Mac OS X and Windows, but the GATE-specific scripts require a POSIX-style Bourne shell with the gawk, tr and grep commands, plus Perl for the Spanish tagger. For Windows this means that you will need to install the appropriate parts of the Cygwin environment from http://www.cygwin.com and set the system property treetagger.sh.path to contain the path to your sh.exe (typically C:\cygwin\bin\sh.exe).
POS Tags. For English the POS tagset is a slightly modified version of the Penn Treebank tagset, where the second letter of the tags for verbs distinguishes between ‘be’ verbs (B), ‘have’ verbs (H) and other verbs (V).
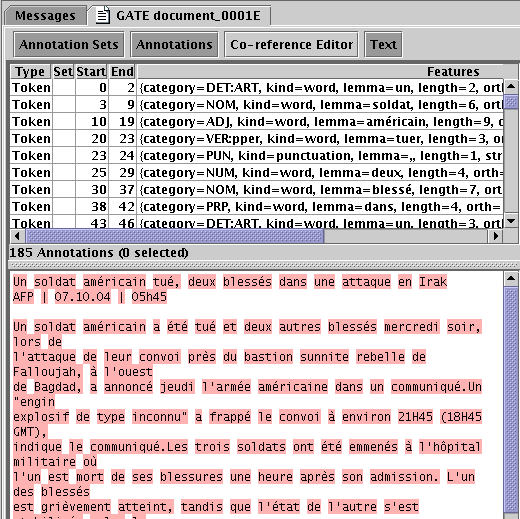
The tagsets for other languages can be found on the TreeTagger web site. Figure 23.1 shows a screenshot of a French document processed with the TreeTagger.
Potential Lemma Problems Sometimes the TreeTagger is either completely unable to determine the correct lemma, or may return multiple lemma for a token (separated by a |). In these cases any further processing that relies on the lemma feature (for example, the flexible gazetteer) may not function correctly. Both problems can be alleviated somewhat by using the resources/TreeTagger/fix-treetagger-lemma.jape JAPE grammar. This can be used either as a standalone grammar or as the post-process initialization feature of the Tagger_Framework PR.
23.3.2 GENIA and Double Quotes [#]
Documents that contain double quote characters can cause problems for the GENIA tagger. The issue arises because the in-built GENIA tokenizer converts double quotes to single quotes in the output which then do not match the document content, causing the tagger to fail. There are two possible solutions to this problem.
Firstly you can perform tokenization in GATE and disable the in-built GENIA tokenizer. Such a pipeline is provided as an example in the GENIA resources direcotry; geniatagger-en-no_tokenization.gapp. However, this may result in other problems for your subsequent code. If so, you may want to try the second solution.
The second solution is to use the GENIA tokenization via the other provided example pipeline: geniatagger-en-tokenization.gapp. If your documents do not contain double quotes then this gapp example should work as is. Otherwise, you must modify the GENIA tagger in order not to convert double quotes to single quotes. Fortunately this is fairly straightforward. In the resources directory you will find a modified copy of tokenize.cpp from v3.0.1 of the GENNIA tagger. Simply use this file to replace the copy in the normal GENIA distribution and recompile. For Windows users, a pre-compiled binary is also provided – simply replace your existing binary with this modified copy.
23.4 Chemistry Tagger [#]
This GATE module is designed to tag a number of chemistry items in running text. Currently the tagger tags compound formulas (e.g. SO2, H2O, H2SO4 ...) ions (e.g. Fe3+, Cl-) and element names and symbols (e.g. Sodium and Na). Limited support for compound names is also provided (e.g. sulphur dioxide) but only when followed by a compound formula (in parenthesis or commas).
23.4.1 Using the Tagger
The Tagger requires the Creole plugin ‘Tagger_Chemistry’ to be loaded. It requires the following PRs to have been run first: tokeniser and sentence splitter (the annotation set containing the Tokens and Sentences can be set using the annotationSetName runtime parameter). There are four init parameters giving the locations of the two gazetteer list definitions, the element mapping file and the JAPE grammar used by the tagger (in previous versions of the tagger these files were fixed and loaded from inside the ChemTagger.jar file). Unless you know what you are doing you should accept the default values.
The annotations added to documents are ‘ChemicalCompound’, ‘ChemicalIon’ and ‘ChemicalElement’ (currently they are always placed in the default annotation set). By default ‘ChemicalElement’ annotations are removed if they make up part of a larger compound or ion annotation. This behaviour can be changed by setting the removeElements parameter to false so that all recognised chemical elements are annotated.
23.5 TextRazor Annotation Service [#]
TextRazor (http://www.textrazor.com) is an online service offering entity and relation annotation, keyphrase extraction, and other similar services via an HTTP API. The Tagger_TextRazor plugin provides a PR to access the TextRazor entity annotation API and store the results as GATE annotations.
The TextRazor Service PR is a simple wrapper around the TextRazor API which sends the text content of a GATE document to TextRazor and creates one annotation for each “entity” that the API returns. The PR invokes the “words” and “entities” extractors of the TextRazor API. The PR has one initialization parameter:
-
apiKey
-
your TextRazor API key – to obtain one you must sign up for an account at http://www.textrazor.com.
and one (optional) runtime parameter:
-
outputASName
-
the annotation set in which the output annotations should be created. If unset, the default annotation set is used.
The PR creates annotations of type TREntity with features
-
type
-
the entity type(s), as class names in the DBpedia ontology. The value of this feature is a List<String>.
-
freebaseTypes
-
FreeBase types for the entity. The value of this feature is a List<String>.
-
confidence
-
confidence score (java.lang.Double).
-
ent_id
-
canonical “entity ID” – typically the title of the Wikipedia page corresponding to the DBpedia instance.
-
link
-
URL of the entity’s Wikipedia page.
Since the key features are lists rather than single values they may be awkward to process in downstream components, so a JAPE grammar is provided in the plugin (resources/jape/TextRazor-to-ANNIE.jape) which can be run after the TextRazor PR to transform key types of TREntity into the corresponding ANNIE annotation types Person, Location and Organization.
23.6 Annotating Numbers [#]
The Tagger_Numbers creole repository contains a number of processing resources which are designed to annotate numbers appearing within documents. As well as annotating a given span as being a number the PRs also determine the exact numeric value of the number and add this as a feature of the annotation. This makes the annotations created by these PRs ideal for building more complex annotations such as measurements or monetary units.
All the PRs in this plugin produce Number annotations with the following standard features
-
type: this describes the types of tokens that make up the number, e.g. roman, words, numbers
-
value: this is the actual value (stored as a Double) of the number that has been annotated
Each PR might also create other features which are described, along with the PR, in the following sections.
23.6.1 Numbers in Words and Numbers [#]
| String | Value |
| 3^2 | 9 |
| 101 | 101 |
| 3,000 | 3000 |
| 3.3e3 | 3300 |
| 1/4 | 0.25 |
| 9^1/2 | 3 |
| 4x10^3 | 4000 |
| 5.5*4^5 | 5632 |
| thirty one | 31 |
| three hundred | 300 |
| four thousand one hundred and two | 4102 |
| 3 million | 3000000 |
| fünfundzwanzig | 25 |
| 4 score | 80 |
The “Numbers Tagger” annotates numbers made up from numbers or numeric words. If that wasn’t really clear enough then Table 23.1 shows numerous ways of representing numbers that can all be annotated by this tagger (depending upon the configuration files used).
To create an instance of the PR you will need to configure the following initialization time parameters (sensible defaults are provided):
-
configURL: the URL of the configuration file you wish to use (see below for details), defaults to resources/languages/all.xml which currently provides support for English, French, German, Spanish and a variety of number related Unicode symbols. If you want a single language the you can specify the appropriately named file, i.e. resources/languages/english.xml.
-
encoding: the encoding of the configuration file, defaults to UTF-8
-
postProcessURL: the URL of the JAPE grammar used for post-processing – don’t change this unless you know what you are doing!
<config> <description>Basic Example</description> <imports> <url encoding="UTF-8">symbols.xml</url> </imports> <words> <word value="0">zero</word> <word value="1">one</word> <word value="2">two</word> <word value="3">three</word> <word value="4">four</word> <word value="5">five</word> <word value="6">six</word> <word value="7">seven</word> <word value="8">eight</word> <word value="9">nine</word> <word value="10">ten</word> </words> <multipliers> <word value="2">hundred</word> <word value="2">hundreds</word> <word value="3">thousand</word> <word value="3">thousands</word> <word value </multipliers> <conjunctions> <word whole="true">and</word> </conjunctions> <decimalSymbol>.</decimalSymbol> <digitGroupingSymbol>,</digitGroupingSymbol> </config>
The configuration file is an XML document that specifies the words that can be used as numbers or multipliers (such as hundred, thousand, ...) and conjunctions that can then be used to combine sequences of numbers together. An example configuration file can be seen in Figure 23.2. This configuration file specifies a handful of words and multipliers and a single conjunction. It also imports another configuration file (in the same format) defining Unicode symbols.
The words are self-explanatory but the multipliers and conjunctions need further clarification.
There are three possible types of multiplier:
-
e: This is the default multiplier type (i.e. is used if the type is missing) and signifies base 10 exponential notation. For example, if the specified value is 2 then this is expanded to ×102, hence converting the text “3 hundred” into 3 × 102 or 300.
-
/: This type allows you to define fractions. For example you would define a half using the value 2 (i.e. you divide by 2). This allows text such as “three halves” to be normalized to 1.5 (i.e. 3∕2). Note that you can also use this type of multiplier to specify multiples greater than one. For example, the text “four score” should be normalized to 80 as a score represents 20 years. To specifiy such a multiplier we use the fraction type with a value of 0.05. This leads to normalized value being calculated as 4∕0.05 which is 80. To determine the value use the simple formula (100∕multipe)∕100
-
 : Multipliers of this type allow you to specify powers. For example, you could define
“squared” with a value of 2 to allow the text “three squared” to be normalized to the
number 9.
: Multipliers of this type allow you to specify powers. For example, you could define
“squared” with a value of 2 to allow the text “three squared” to be normalized to the
number 9.
In English conjunctions are whole words, that is they require white space on either side of them, e.g. three hundred and one. In other languages, however, numbers can be joined into a single word using a conjunction. For example, in German the conjunction ‘und’ can appear in a number without white space, e.g. twenty one is written as einundzwanzig. If the conjunction is a whole word, as in English, then the whole attribute should be set to true, but for conjunctions like ‘und’ the attribute should be set to false.
In order to support different number formats the symbols used to group numbers and to represent the decimal point can also be configured. These are optional elements in the XML configuration file which if not supplied default to a comma for the digit group symbol and a full stop for the decimal point. Whilst these are appropriate for many languages if you wanted, for example, to parse documents written in Bulgarian you would want to specify that the decimal symbol was a command and the grouping symbol was a space in order to recognise numbers such as 1 000 000,303.
Once created an instance of the PR can then be configured using the following runtime parameters:
-
allowWithinWords: digits can often occur within words (for example part numbers, chemical equations etc.) where they should not be interpreted as numbers. If this parameter is set to true then these instances will also be annotated as numbers (useful for annotating money and measurements where spaces are often omitted), however, the parameter defaults to false.
-
annotationSetName: the annotation set to use as both input and output for this PR (due to the way this PR works the two sets have to be the same)
-
failOnMissingInputAnnotations: if the input annotations (Tokens and Sentences) are missing should this PR fail or just not do anything, defaults to true to allow obvious mistakes in pipeline configuration to be captured at an early stage.
-
useHintsFromOriginalMarkups: often the original markups will provide hints that may be useful for correctly interpreting numbers within documents (i.e. numeric powers may be in <sup></sup> tags), if this parameter is set to true then these hints will be used to help parse the numbers, defaults to true.
There are no extra annotation features which are specific to this numbers PR. The type feature can take one of three values based upon the text that is annotated; words, numbers, wordsAndNumbers.
23.6.2 Roman Numerals [#]
The “Roman Numerals Tagger” annotates Roman numerals appearing in the document. The tagger is configured using the following runtime parameters:
-
allowLowerCase: traditionally Roman numerals must be all in uppercase. Setting this parameter to false, however, allows Roman numerals written in lowercase to also be annotated. This parameter defaults to false.
-
maxTailLength: Roman numerals are often used in labelling sections, figures, tables etc. and in such cases can be followed by additional information. For example, Table IVa, Appendix IIIb. These characters are referred to as the tail of the number and this parameter constrains the number of characters that can appear. The default value is 0 in which case strings such as ’IVa’ would not be annotated in any way.
-
outputASName: the name of the annotation set in which the Number annotations should be created.
As well as the normal Number annotation features (the type feature will always take the value ‘roman’) Roman numeral annotations also include the following features:
-
tail: contains the tail, if any, that appears after the Roman numeral.
23.7 Annotating Measurements [#]
For the GATE Cloud version of the measurement annotator, see:
https://cloud.gate.ac.uk/shopfront/displayItem/measurement-expression-annotator
Measurements mentioned in text documents can be difficult to accurately deal with. As well as the numerous ways in which numeric values can be written each type of measurement (distance, area, time etc.) can be written using a variety of different units. For example, lengths can be measured in metres, centimetres, inches, yards, miles, furlongs and chains, to mention just a few. Whilst measurements may all have different units and values they can, in theory be compared to one another. Extracting, normalizing and comparing measurements can be a useful IE process in many different domains. The Measurement Tagger (which can be found in the Tagger_Measurements plugin) attempts to provide such annotations for use within IE applications.
The Measurements Tagger uses a parser based upon a modified version of the Java port of the GNU Units package. This allows us to not only recognise and annotation spans of text as being a measurement but also to normalize the units to allow for easy comparison of different measurement values.
This PR actually produces two different annotations; Measurement and Ratio.
Measurement annotations represent measurements that involve a unit, e.g. 3mph, three pints, 4 m3. Single measurements (i.e. those not referring to a range or interval) are referred to as scalar measurements and have the following features:
-
type: for scalar measurements is always scalar
-
unit: the unit as recognised from the text. Note that this won’t necessarily be the annotated text. For example, an annotation spanning the text “three miles” would have a unit feature of “mile”.
-
value: a Double holding the value of the measurement (this usually comes directly from the value feature of a Number annotation).
-
dimension: the measurements dimension, e.g. speed, volume, area, length, time etc.
-
normalizedUnit: to enable measurements of the same dimension but specified in different units to be compared the PR reduces all units to their base form. A base form usually consists of a combination of SI units. For example, centimetre, mm, and kilometre are all normalized to m (for metre).
-
normalizedValue: a Double instance holding the normalized value, such that the combination of the normalized value and normalized unit represent the same measurement as the original value and unit.
-
normalized: a String representing the normalized measurement (usually a simple space separated concatenation of the normalized value and unit).
Annotations which represent an interval or range have a slightly different set of features. The type feature is set to interval, there is no normalized or unit feature and the value features (included the normalized version) are replaced by the following features, the values of which are simply copied from the Measurement annotations which mark the boundaries of the interval.
-
normalizedMinValue: a Double representing the minimum normalized number that forms part of the interval.
-
normalizedMaxValue: a Double representing the minimum normalized number that forms part of the interval.
Interval annotations do not replace scalar measurements and so multiple Measurement annotations may well overlap. They can of course be distinguished by the type feature.
As well as Measurement annotations the tagger also adds Ratio annotations to documents. Ratio annotations cover measurements that do not have a unit. Percentages are the most common ratios to be found in documents, but also amounts such as “300 parts per million” are annotated.
A Ratio annotation has the following features:
-
value: a Double holding the actual value of the ratio. For example, 20% will have a value of 0.2.
-
numerator: the numerator of the ratio. For example, 20% will have a numerator of 20.
-
denominator: the denominator of the ratio. For example, 20% will have a denominator of 100.
An instance of the measurements tagger is created using the following initialization parameters:
-
commonURL: this file defines units that are also common words and so should not be annotated as a measurement unless they form a compound unit involving two or more unit symbols. For example, C is the accepted abbreviation for coulomb but often appears in documents as part of a reference to a table or figure, i.e. Figure 3C, which should not be annotated as a measurement. The default file was hand tuned over a large patent corpus but may need to be edited when used with different domains.
-
encoding: the encoding to use when reading both of the configuration files, defaults to UTF-8.
-
japeURL: the URL of the JAPE grammar that drives the measurement parser. Unless you really know what you are doing, the value of this parameter should not be changed.
-
locale: the locale to use when parsing the units definition file, defaults to en_GB.
-
unitsURL: the URL of the main unit definition file to use. This should be in the same format as accepted by the GNU Units package.
The PR does not attempt to recognise or annotate numbers, instead it relies on Number annotations being present in the document. Whilst these annotations could be generated by any resource executed prior to the measurements tagger, we recommend using the Numbers Tagger described in Section 23.6. If you choose to produce Number annotations in some other way note that they must have a value feature containing a Double representing the value of the number. An example GATE application, showing how to configure and use the two PRs together, is provided with the measurements plugin.
Once created an instance of the tagger can be configured using the following runtime parameters:
-
consumeNumberAnnotations: if true then Number annotations used to find measurements will be consumed and removed from the document, defaults to true.
-
failOnMissingInputAnnotations: if the input annotations (Tokens) are missing should this PR fail or just not do anything, defaults to true to allow obvious mistakes in pipeline configuration to be captured at an early stage.
-
ignoredAnnotations: a list of annotation types in which a measurement can never occur, defaults to a set containing Date and Money.
-
inputASName: the annotation set used as input to this PR.
-
outputASName: the annotation set to which new annotations will be added.
The ability to prevent the tagger from annotating measurements which occur within other annotations is a very useful feature. The runtime parameters, however, only allow you to specify the names of annotations and not to restrict on feature values or any other information you may know about the documents being processed. Internally ignoring sections of a document is controlled by adding CannotBeAMeasurement annotations that span the text to be ignored. If you need greater control over the process than the ignoredAnnotations parameter allows then you can create CannotBeAMeasurement annotations prior to running the measurement tagger, for example a JAPE grammar placed before the tagger in the pipeline. Note that these annotations will be deleted by the measurements tagger once processing has completed.
23.8 Annotating and Normalizing Dates [#]
Many information extraction tasks benefit from or require the extraction of accurate date information. While ANNIE (Chapter 6) does produce Date annotations no attempt is made to normalize these dates, i.e. to firmly fix all dates, even partial or relative ones, to a timeline using a common date representation. The PR in the Tagger_DateNormalizer plugin attempts to fill this gap by normalizing dates against the date of the document (see below for details on how this is determined) in order to tie each Date annotation to a specific date. This includes normalizing dates such as April 1st, today, yesterday, and next Tuesday, as well as converting fully specified dates (ones in which the day, month and year are specified) into a common format.
Different cultures/countries have different conventions for writing dates, as well as different languages using different words for the days of the week and the months of the year. The parser underlying this PR makes use of the locale-specific information when parsing documents. When initializing an instance of the Date Normalizer you can specify the locale to use using ISO language and country codes along with Java specific variants (for details of these codes see the Java Locale documentation). So for example, to specify British English (which means the day usually comes before the month in a date) use en_GB, or for American English (where the month usually appears before the day in a date) specify en_US. If you need to override the locale on a document basis then you can do this by setting a document feature called locale to a string encoded as above. If neither the initialization parameter or document feature are present or do not represent a valid locale then the default locale of the JVM running GATE will be used.
Once initialized and added to a pipeline the Date Normalizer has the following runtime parameters that can be used to control it’s behaviour.
-
annotationName: the annotation type created by this PR, defaults to Date.
-
dateFormat: the format that dates should be normalized to. The format of this parameter is the same as that use by the Java SimpleDateFormat whose documentation describes the full range of possible formats (note you must use MM for month and not mm). This defaults to dd/MM/yyyy. Note that this parameter is only required if the numericOuput parameter is set to false.
-
failOnMissingInputAnnotations: if the input annotations (Tokens) are missing should this PR fail or just not do anything, defaults to true to allow obvious mistakes in pipeline configuration to be captured at an early stage.
-
inputASName: the annotation set used as input to this PR.
-
normalizedDocumentFeature: if set then the normalized version of the document date will be stored in a document feature with this name. This parameter defaults to normalized-date although it can be left blank to suppress storage of the document date.
-
numericOutput: if true then instead of formatting the normalized dates as String features of the Date annotations they are instead converted into a numeric representation. Specifically the first converted to the form yyyyMMdd and then cast to a Double. This is useful as dates can then be sorted numerical (which is fast) into order. If false then the formatting string in the dateFormat parameter is used instead to create a string representation. This defaults to false.
-
outputASName: the annotation set to which new annotations will be added.
-
sourceOfDocumentDate: this parameter is a list of the names of annotations, annotation features (encoded as Annotation.feature), and document features to inspect when trying to determine the date of the document. The PR works through the list getting the text of feature or under the annotation (if no feature is specified) and then parsing this to find a fully specified date, i.e. one where the day, month and year are all present. Once a date is found processing of the list stops and the date is used as the date of the document. If you specify an annotation that can occur multiple times in a document then they are sorted based on a numeric priority feature (which defaults to 0) or their order within the document. The idea here is that there are multiple ways in which to determine the date of a document but most are domain specific and this allows previous PRs in an application to determine the document date. This defaults to an empty list which is taken to assume that the document was written on the day it is being processed. The same assumption applies if no fully-specified date can be found once the whole list has been processed. Note that a common mistake is to think you can use a date annotated by this PR as the document date. The document date is determined before the document is processed, so any annotation you wish to use to represent the document date must exist before this PR executes.
It is important to note that rather this plugin creates new Date annotations and so if you run it in the same pipeline as the ANNIE NE Transducer you will likely end up with overlapping Date annotations. Depending on your needs it may be that you need a JAPE grammar to delete ANNIE Date annotations before running this PR. In practice we have found that the Date annotations added by ANNIE can be a good source of document dates and so a JAPE grammar that uses ANNIE Dates to add new DocumentDate annotations and to delete other Date annotations can be a useful step before running this PR.
The annotations created by this PR have the following features:
-
normalize: the normalized date in the format specified through the relevant runtime parameters of the PR.
-
inferred: an integer which specifies which specifes which parts of the date had to be inferred. The value is actually a bit mask created from the following flagd: day = 1, month = 2, and year = 4. You can find which (if any) flags are set by using the code (inferred & FLAG) == FLAG, i.e. to see if the day of the month had to be inferred you would do (inferred & 1) == 1.
-
complete: if no part of the date had to be inferred (i.e. inferred = 0) then this will be true, false otherwise.
-
relative: can take the values past, present or future to show how this specific date relates to the document date.
23.9 Snowball Based Stemmers [#]
The stemmer plugin, ‘Stemmer_Snowball’, consists of a set of stemmers PRs for the following 11 European languages: Danish, Dutch, English, Finnish, French, German, Italian, Norwegian, Portuguese, Russian, Spanish and Swedish. These take the form of wrappers for the Snowball stemmers freely available from http://snowball.tartarus.org. Each Token is annotated with a new feature ‘stem’, with the stem for that word as its value. The stemmers should be run as other PRs, on a document that has been tokenised.
There are three runtime parameters which should be set prior to executing the stemmer on a document.
-
annotationType: This is the type of annotations that represent tokens in the document. Default value is set to ‘Token’.
-
annotationFeature: This is the name of a feature that contains tokens’ strings. The stemmer uses value of this feature as a string to be stemmed. Default value is set to ‘string’.
-
annotationSetName: This is where the stemmer expects the annotations of type as specified in the annotationType parameter to be.
23.9.1 Algorithms
The stemmers are based on the Porter stemmer for English [Porter 80], with rules implemented in Snowball e.g.
define Step_1a as ( [substring] among ( ’sses’ (<-’ss’) ’ies’ (<-’i’) ’ss’ () ’s’ (delete) )
23.10 GATE Morphological Analyzer [#]
The Morphological Analyser PR can be found in the Tools plugin. It takes as input a tokenized GATE document. Considering one token and its part of speech tag, one at a time, it identifies its lemma and an affix. These values are than added as features on the Token annotation. Morpher is based on certain regular expression rules. These rules were originally implemented by Kevin Humphreys in GATE1 in a programming language called Flex. Morpher has a capability to interpret these rules with an extension of allowing users to add new rules or modify the existing ones based on their requirements. In order to allow these operations with as little effort as possible, we changed the way these rules are written. More information on how to write these rules is explained later in Section 23.10.1.
Two types of parameters, Init-time and run-time, are required to instantiate and execute the PR.
-
rulesFile (Init-time) The rule file has several regular expression patterns. Each pattern has two parts, L.H.S. and R.H.S. L.H.S. defines the regular expression and R.H.S. the function name to be called when the pattern matches with the word under consideration. Please see 23.10.1 for more information on rule file.
-
caseSensitive (init-time) By default, all tokens under consideration are converted into lowercase to identify their lemma and affix. If the user selects caseSensitive to be true, words are no longer converted into lowercase.
-
document (run-time) Here the document must be an instance of a GATE document.
-
affixFeatureName (run-time) Name of the feature that should hold the affix value.
-
rootFeatureName (run-time) Name of the feature that should hold the root value.
-
annotationSetName (run-time) Name of the annotationSet that contains Tokens.
-
considerPOSTag (run-time) Each rule in the rule file has a separate tag, which specifies which rule to consider with what part-of-speech tag. If this option is set to false, all rules are considered and matched with all words. This option is very useful. For example if the word under consideration is "singing". "singing" can be used as a noun as well as a verb. In the case where it is identified as a verb, the lemma of the same would be "sing" and the affix "ing", but otherwise there would not be any affix.
-
failOnMissingInputAnnotations (run-time) If set to true (the default) the PR will terminate with an Exception if none of the required input Annotations are found in a document. If set to false the PR will not terminate and instead log a single warning message per session and a debug message per document that has no input annotations.
23.10.1 Rule File [#]
GATE provides a default rule file, called default.rul, which is available under the gate/plugins/Tools/morph/resources directory. The rule file has two sections.
-
Variables
-
Rules
Variables
The user can define various types of variables under the section defineVars. These variables can be used as part of the regular expressions in rules. There are three types of variables:
-
Range With this type of variable, the user can specify the range of characters. e.g. A ==> [-a-z0-9]
-
Set With this type of variable, user can also specify a set of characters, where one character at a time from this set is used as a value for the given variable. When this variable is used in any regular expression, all values are tried one by one to generate the string which is compared with the contents of the document. e.g. A ==> [abcdqurs09123]
-
Strings Where in the two types explained above, variables can hold only one character from the given set or range at a time, this allows specifying strings as possibilities for the variable. e.g. A ==> ‘bb’ OR ‘cc’ OR ‘dd’
Rules
All rules are declared under the section defineRules. Every rule has two parts, LHS and RHS. The LHS specifies the regular expression and the RHS the function to be called when the LHS matches with the given word. ‘==>’ is used as delimiter between the LHS and RHS.
The LHS has the following syntax:
< ” ∗ ”|”verb”|”noun” >< regularexpression >.
User can specify which rule to be considered when the word is identified as ‘verb’ or ‘noun’. ‘*’ indicates that the rule should be considered for all part-of-speech tags. If the part-of-speech should be used to decide if the rule should be considered or not can be enabled or disabled by setting the value of considerPOSTags option. Combination of any string along with any of the variables declared under the defineVars section and also the Kleene operators, ‘+’ and ‘*’, can be used to generate the regular expressions. Below we give few examples of L.H.S. expressions.
-
<verb>"bias"
-
<verb>"canvas"{ESEDING} "ESEDING" is a variable defined under the defineVars section. Note: variables are enclosed with "{" and "}".
-
<noun>({A}*"metre") "A" is a variable followed by the Kleene operator "*", which means "A" can occur zero or more times.
-
<noun>({A}+"itis") "A" is a variable followed by the Kleene operator "+", which means "A" can occur one or more times.
-
< ∗ >"aches" "< ∗ >" indicates that the rule should be considered for all part-of-speech tags.
On the RHS of the rule, the user has to specify one of the functions from those listed below. These rules are hard-coded in the Morph PR in GATE and are invoked if the regular expression on the LHS matches with any particular word.
-
stem(n, string, affix) Here,
-
n = number of characters to be truncated from the end of the string.
-
string = the string that should be concatenated after the word to produce the root.
-
affix = affix of the word
-
-
irreg_stem(root, affix) Here,
-
root = root of the word
-
affix = affix of the word
-
null_stem() This means words are themselves the base forms and should not be analyzed.
-
-
semi_reg_stem(n,string) semir_reg_stem function is used with the regular expressions that end with any of the {EDING} or {ESEDING} variables defined under the variable section. If the regular expression matches with the given word, this function is invoked, which returns the value of variable (i.e. {EDING} or {ESEDING}) as an affix. To find a lemma of the word, it removes the n characters from the back of the word and adds the string at the end of the word.
23.11 Flexible Exporter [#]
The Flexible Exporter enables the user to save a document (or corpus) in its original format with added annotations. The user can select the name of the annotation set from which these annotations are to be found, which annotations from this set are to be included, whether features are to be included, and various renaming options such as renaming the annotations and the file.
At load time, the following parameters can be set for the flexible exporter:
-
includeFeatures - if set to true, features are included with the annotations exported; if false (the default status), they are not.
-
useSuffixForDumpFiles - if set to true (the default status), the output files have the suffix defined in suffixForDumpFiles; if false, no suffix is defined, and the output file simply overwrites the existing file (but see the outputFileUrl runtime parameter for an alternative).
-
suffixForDumpFiles - this defines the suffix if useSuffixForDumpFiles is set to true. By default the suffix is .gate.
-
useStandOffXML - if true then the format will be the GATE XML format that separates nodes and annotations inside the file which allows overlapping annotations to be saved.
The following runtime parameters can also be set (after the file has been selected for the application):
-
annotationSetName - this enables the user to specify the name of the annotation set which contains the annotations to be exported. If no annotation set is defined, it will use the Default annotation set.
-
annotationTypes - this contains a list of the annotations to be exported. By default it is set to Person, Location and Date.
-
dumpTypes - this contains a list of names for the exported annotations. If the annotation name is to remain the same, this list should be identical to the list in annotationTypes. The list of annotation names must be in the same order as the corresponding annotation types in annotationTypes.
-
outputDirectoryUrl - this enables the user to specify the export directory where the file is exported with its original name and an extension (provided as a parameter) appended at the end of filename. Note that you can also save a whole corpus in one go. If not provided, use the temporary directory.
23.12 Configurable Exporter [#]
The Configurable Exporter allows the user to export arbitrary annotation texts and feature values according to a format specified in a configuration file. It is written with machine learning in mind, where features might be required in a comma separated format or similar, though it could be equally well applied to any purpose where data are required in a spreadsheet format or a simple format for further processing. An example of the kind of output that can be obtained using the PR is given below, although significant variation on the theme is possible, showing typical instance IDs, classes and attributes:
10000004, A, "Some text .." 10000005, A, "Some more text .." 10000006, B, "Further text .." 10000007, B, "Additional text .." 10000008, B, "Yet more text .."
Central to the PR is the concept of an instance; each line of output will relate to an instance, which might be a document for example, or an annotation type within a GATE document such as a sentence, tweet, or indeed any other annotation type. Instance is specified as a runtime parameter (see below). Whatever you want one per line of, that is your instance.
The PR has one required initialisation parameter, which is the location of the configuration file. If you edit your configuration file, you must reinitialise the PR. The configuration file comprises a single line specifying the output format. Annotation and feature names are surrounded by triple angle brackets, indicating that they are to be replaced with the annotation/feature. The rest of the text in the configuration file is passed unchanged into the output file. Where an annotation type is specified without a feature, the text spanned by that annotation will be used. Dot notation is used to indicate that a feature value is to be used. The example output given above might be obtained by a configuration file something like this, in which index, class and content are annotation types:
{index}, {class}, "{content}"
Alternatively, in this example, class is a feature on the instance annotation:
{index}, {instance.class}, "{content}"
Runtime parameters are as follows:
-
inputASName - this is the annotation set which will be used to create the export file. All annotations must be in this set, both instance annotations and export annotations. If left blank, the default annotation set will be used.
-
instanceName - this is the annotation type to be used as instance. If left blank, the document will be used as instance.
-
outputURL - this is the location of the output file to which the data will be exported. If left blank, data will be output to the messages tab/standard out.
Note that where more than one annotation of the specified type occurs within the span of the instance annotation, the first will be used to create the output. It is not currently supported to output more than one annotation of the same type per instance. If you need to export, for example, all the words in the sentence, then you would have to export the sentence rather than the individual words.
23.13 Annotation Set Transfer [#]
The Annotation Set Transfer allows copying or moving annotations to a new annotation set if they lie between the beginning and the end of an annotation of a particular type (the covering annotation). For example, this can be used when a user only wants to run a processing resource over a specific part of a document, such as the Body of an HTML document. The user specifies the name of the annotation set and the annotation which covers the part of the document they wish to transfer, and the name of the new annotation set. All the other annotations corresponding to the matched text will be transferred to the new annotation set. For example, we might wish to perform named entity recognition on the body of an HTML text, but not on the headers. After tokenising and performing gazetteer lookup on the whole text, we would use the Annotation Set Transfer to transfer those annotations (created by the tokeniser and gazetteer) into a new annotation set, and then run the remaining NE resources, such as the semantic tagger and coreference modules, on them.
The Annotation Set Transfer has no loadtime parameters. It has the following runtime parameters:
-
inputASName - this defines the annotation set from which annotations will be transferred (copied or moved). If nothing is specified, the Default annotation set will be used.
-
outputASName - this defines the annotation set to which the annotations will be transferred. This default value for this parameter is ‘Filtered’. If it is left blank the Default annotation set will be used.
-
tagASName - this defines the annotation set which contains the annotation covering the relevant part of the document to be transferred. This default value for this parameter is ‘Original markups’. If it is left blank the Default annotation set will be used.
-
textTagName - this defines the type of the annotation covering the annotations to be transferred. The default value for this parameter is ‘BODY’. If this is left blank, then all annotations from the inputASName annotation set will be transferred. If more than one covering annotation is found, the annotation covered by each of them will be transferred. If no covering annotation is found, the processing depends on the copyAllUnlessFound parameter (see below).
-
copyAnnotations - this specifies whether the annotations should be moved or copied. The default value false will move annotations, removing them from the inputASName annotation set. If set to true the annotations will be copied.
-
transferAllUnlessFound - this specifies what should happen if no covering annotation is found. The default value is true. In this case, all annotations will be copied or moved (depending on the setting of parameter copyAnnotations) if no covering annotation is found. If set to false, no annotation will be copied or moved.
-
annotationTypes - if annotation type names are specified for this list, only candidate annotations of those types will be transferred or copied. If an entry in this list is specified in the form OldTypeName=NewTypeName, then annotations of type OldTypeName will be selected for copying or transfer and renamed to NewTypeName in the output annotation set.
For example, suppose we wish to perform named entity recognition on only the text covered by the BODY annotation from the Original Markups annotation set in an HTML document. We have to run the gazetteer and tokeniser on the entire document, because since these resources do not depend on any other annotations, we cannot specify an input annotation set for them to use. We therefore transfer these annotations to a new annotation set (Filtered) and then perform the NE recognition over these annotations, by specifying this annotation set as the input annotation set for all the following resources. In this example, we would set the following parameters (assuming that the annotations from the tokenise and gazetteer are initially placed in the Default annotation set).
-
inputASName: Default
-
outputASName: Filtered
-
tagASName: Original markups
-
textTagName: BODY
-
copyAnnotations: true or false (depending on whether we want to keep the Token and Lookup annotations in the Default annotation set)
-
copyAllUnlessFound: true
The AST PR makes a shallow copy of the feature map for each transferred annotation, i.e. it creates a new feature map containing the same keys and values as the original. It does not clone the feature values themselves, so if your annotations have a feature whose value is a collection and you need to make a deep copy of the collection value then you will not be able to use the AST PR to do this. Similarly if you are copying annotations and do in fact want to share the same feature map between the source and target annotations then the AST PR is not appropriate. In these sorts of cases a JAPE grammar or Groovy script would be a better choice.
23.14 Schema Enforcer [#]
One common use of the Annotation Set Transfer (AST) PR (see Section 23.13) is to create a ‘clean’ or final annotation set for a GATE application, i.e. an annotation set containing only those annotations which are required by the application without any temporary or intermediate annotations which may also have been created. Whilst really useful the AST suffers from two problems 1) it can be complex to configure and 2) it offers no support for modifying or removing features of the annotations it copies.
Many GATE applications are developed through a process which starts with experts manually annotating documents in order for the application developer to understand what is required and which can later be used for testing and evaluation. This is usually done using either GATE Teamware or within GATE Developer using the Schema Annotation Editor (Section 3.4.6). Either approach requires that each of the annotation types being created is described by an XML based Annotation Schema. The Schema Enforcer (part of the Schema_Tools plugin) uses these same schemas to create an annotation set, the contents of which, strictly matches the provided schemas.
The Schema Enforcer will copy an annotation if and only if....
-
the type of the annotation matches one of the supplied schemas
-
all required features are present and valid (i.e. meet the requirements for being copied to the ’clean’ annotation)
Each feature of an annotation is copied to the new annotation if and only if....
-
the feature name matches a feature in the schema describing the annotation
-
the value of the feature is of the same type as specified in the schema
-
if the feature is defined, in the schema, as an enumerated type then the value must match one of the permitted values
The Schema Enforcer has no initialization parameters and is configured via the following runtime parameters:
-
inputASName - - this defines the annotation set from which annotations will be copied. If nothing is specified, the default annotation set will be used.
-
outputASName - this defines the annotation set to which the annotations will be transferred. This must be an empty or non-existent annotation set.
-
schemas - a list of schemas that will be enforced when duplicating the input annotation set.
-
useDefaults - if true then the default value for required features (specified using the value attribute in the XML schema) will be used to help complete an otherwise invalid annotation, defaults to false.
Whilst this PR makes the creation of a clean output set easy (given the schemas) it is worth noting that schemas can only define features which have basic types; string, integer, boolean, float, double, short, and byte. This means that you cannot define a feature which has an object as it’s value. For example, this prevents you defining a feature as a list of numbers. If this is an issue then it is trivial to write JAPE to copy extra features not specified in the schemas as the annotations have the same ID in both the input and output annotation sets. An example JAPE file for copying the matches feature created by the Orthomatcher PR (see Section 6.8) is provided.
23.15 Information Retrieval in GATE [#]
GATE comes with a full-featured Information Retrieval (IR) subsystem that allows queries to be performed against GATE corpora. This combination of IE and IR means that documents can be retrieved from the corpora not only based on their textual content but also according to their features or annotations. For example, a search over the Person annotations for ‘Bush’ will return documents with higher relevance, compared to a search in the content for the string ‘bush’. The current implementation is based on the most popular open source full-text search engine - Lucene (available at http://jakarta.apache.org/lucene/) but other implementations may be added in the future.
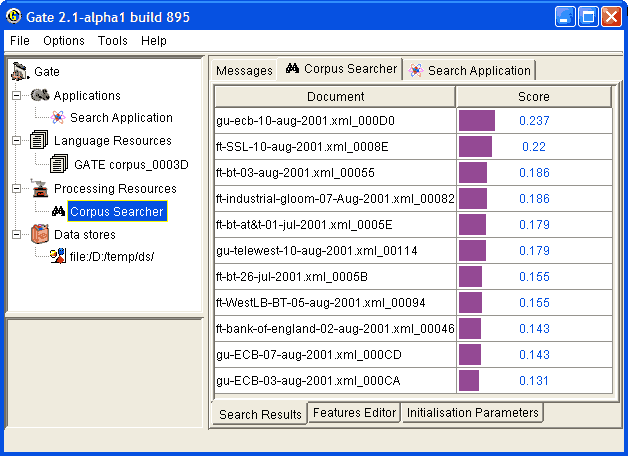
An Information Retrieval system is most often considered a system that accepts as input a set of documents (corpus) and a query (combination of search terms) and returns as input only those documents from the corpus which are considered as relevant according to the query. Usually, in addition to the documents, a proper relevance measure (score) is returned for each document. There exist many relevance metrics, but usually documents which are considered more relevant, according to the query, are scored higher.
Figure 23.3 shows the results from running a query against an indexed corpus in GATE.
| term1 | term2 | ... | ... | termk | |
| doc1 | w1,1 | w1,2 | ... | ... | w1,k |
| doc2 | w2,1 | w2,1 | ... | ... | w2,k |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| docn | wn, 1 | wn,2 | ... | ... | wn,k |
Information Retrieval systems usually perform some preprocessing one the input corpus in order to create the document-term matrix for the corpus. A document-term matrix is usually presented as in Table 23.2, where doci is a document from the corpus, termj is a word that is considered as important and representative for the document and wi,j is the weight assigned to the term in the document. There are many ways to define the term weight functions, but most often it depends on the term frequency in the document and in the whole corpus (i.e. the local and the global frequency). Note that the machine learning plugin described in Chapter 19 can produce such document-term matrix (for detailed description of the matrix produced, see Section 19.1).
Note that not all of the words appearing in the document are considered terms. There are many words (called ‘stop-words’) which are ignored, since they are observed too often and are not representative enough. Such words are articles, conjunctions, etc. During the preprocessing phase which identifies such words, usually a form of stemming is performed in order to minimize the number of terms and to improve the retrieval recall. Various forms of the same word (e.g. ‘play’, ‘playing’ and ‘played’) are considered identical and multiple occurrences of the same term (probably ‘play’) will be observed.
It is recommended that the user reads the relevant Information Retrieval literature for a detailed explanation of stop words, stemming and term weighting.
IR systems, in a way similar to IE systems, are evaluated with the help of the precision and recall measures (see Section 10.1 for more details).
23.15.1 Using the IR Functionality in GATE
In order to run queries against a corpus, the latter should be ‘indexed’. The indexing process first processes the documents in order to identify the terms and their weights (stemming is performed too) and then creates the proper structures on the local file system. These file structures contain indexes that will be used by Lucene (the underlying IR engine) for the retrieval.
Once the corpus is indexed, queries may be run against it. Subsequently the index may be removed and then the structures on the local file system are removed too. Once the index is removed, queries cannot be run against the corpus.
Indexing the Corpus
In order to index a corpus, the latter should be stored in a serial datastore. In other words, the IR functionality is unavailable for corpora that are transient or stored in a RDBMS datastores (though support for the latter may be added in the future).
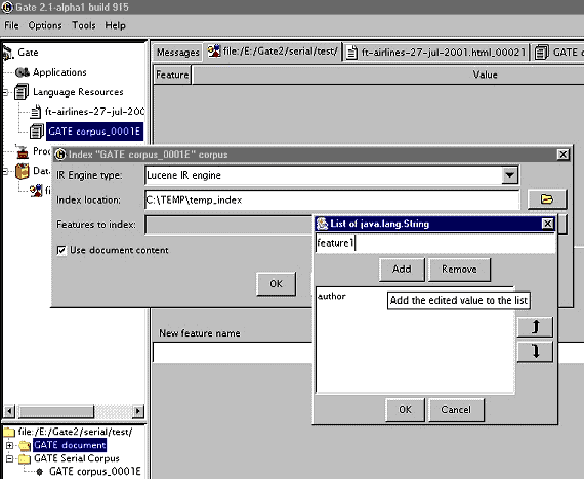
To index the corpus, follow these steps:
-
Select the corpus from the resource tree (top-left pane) and from the context menu (right button click) choose ‘Index Corpus’. A dialogue appears that allows you to specify the index properties.
-
In the index properties dialogue, specify the underlying IR system to be used (only Lucene is supported at present), the directory that will contain the index structures, and the set of properties that will be indexed such as document features, content, etc (the same properties will be indexed for each document in the corpus).
-
Once the corpus in indexed, you may start running queries against it. Note that the directory specified for the index data should exist and be empty. Otherwise an error will occur during the index creation.
Querying the Corpus
To query the corpus, follow these steps:
-
Create a SearchPR processing resource. All the parameters of SearchPR are runtime so they are set later.
-
Create a “pipeline” application (not a “corpus pipeline”) containing the SearchPR.
-
Set the following SearchPR parameters:
-
The corpus that will be queried.
-
The query that will be executed.
-
The maximum number of documents returned.
A query looks like the following:
{+/-}field1:term1 {+/-}field2:term2 ? {+/-}fieldN:termNwhere field is the name of a index field, such as the one specified at index creation (the document content field is body) and term is a term that should appear in the field.
For example the query:
+body:government +author:CNNwill inspect the document content for the term ‘government’ (together with variations such as ‘governments’ etc.) and the index field named ‘author’ for the term ‘CNN’. The ‘author’ field is specified at index creation time, and is either a document feature or another document property.
-
-
After the SearchPR is initialized, running the application executes the specified query over the specified corpus.
-
Finally, the results are displayed (see fig.1) after a double-click on the SearchPR processing resource.
Removing the Index
An index for a corpus may be removed at any time from the ‘Remove Index’ option of the context menu for the indexed corpus (right button click).
23.15.2 Using the IR API
The IR API within GATE Embedded makes it possible for corpora to be indexed, queried and results returned from any Java application, without using GATE Developer. The following sample indexes a corpus, runs a query against it and then removes the index.
2// open a serial datastore
3SerialDataStore sds =
4Factory.openDataStore("gate.persist.SerialDataStore",
5"/tmp/datastore1");
6sds.open();
7
8//set an AUTHOR feature for the test document
9Document doc0 = Factory.newDocument(new URL("/tmp/documents/doc0.html"));
10doc0.getFeatures().put("author","John Smith");
11
12Corpus corp0 = Factory.newCorpus("TestCorpus");
13corp0.add(doc0);
14
15//store the corpus in the serial datastore
16Corpus serialCorpus = (Corpus) sds.adopt(corp0,null);
17sds.sync(serialCorpus);
18
19//index the corpus − the content and the AUTHOR feature
20
21IndexedCorpus indexedCorpus = (IndexedCorpus) serialCorpus;
22
23DefaultIndexDefinition did = new DefaultIndexDefinition();
24did.setIrEngineClassName(
25 gate.creole.ir.lucene.LuceneIREngine.class.getName());
26did.setIndexLocation("/tmp/index1");
27did.addIndexField(new IndexField("content",
28 new DocumentContentReader(), false));
29did.addIndexField(new IndexField("author", null, false));
30indexedCorpus.setIndexDefinition(did);
31
32indexedCorpus.getIndexManager().createIndex();
33//the corpus is now indexed
34
35//search the corpus
36Search search = new LuceneSearch();
37search.setCorpus(ic);
38
39QueryResultList res = search.search("+content:government +author:John");
40
41//get the results
42Iterator it = res.getQueryResults();
43while (it.hasNext()) {
44QueryResult qr = (QueryResult) it.next();
45System.out.println("DOCUMENT_ID=" + qr.getDocumentID()
46 + ", score=" + qr.getScore());
47}
23.16 WordNet in GATE [#]
GATE currently supports versions 1.6 and newer of WordNet, so in order to use WordNet in GATE, you must first install a compatible version of WordNet on your computer. WordNet is available at http://wordnet.princeton.edu/. The next step is to configure GATE to work with your local WordNet installation. Since GATE relies on the Java WordNet Library (JWNL) for WordNet access, this step consists of providing one special xml file that is used internally by JWNL. This file describes the location of your local copy of the WordNet index files. An example of this wn-config.xml file is shown below:
<?xml version="1.0" encoding="UTF-8"?>
<jwnl_properties language="en">
<version publisher="Princeton" number="3.0" language="en"/>
<dictionary class="net.didion.jwnl.dictionary.FileBackedDictionary">
<param name="morphological_processor"
value="net.didion.jwnl.dictionary.morph.DefaultMorphologicalProcessor">
<param name="operations">
<param value=
"net.didion.jwnl.dictionary.morph.LookupExceptionsOperation"/>
<param value="net.didion.jwnl.dictionary.morph.DetachSuffixesOperation">
<param name="noun"
value="|s=|ses=s|xes=x|zes=z|ches=ch|shes=sh|men=man|ies=y|"/>
<param name="verb"
value="|s=|ies=y|es=e|es=|ed=e|ed=|ing=e|ing=|"/>
<param name="adjective"
value="|er=|est=|er=e|est=e|"/>
<param name="operations">
<param
value="net.didion.jwnl.dictionary.morph.LookupIndexWordOperation"/>
<param
value="net.didion.jwnl.dictionary.morph.LookupExceptionsOperation"/>
</param>
</param>
<param value="net.didion.jwnl.dictionary.morph.TokenizerOperation">
<param name="delimiters">
<param value=" "/>
<param value="-"/>
</param>
<param name="token_operations">
<param
value="net.didion.jwnl.dictionary.morph.LookupIndexWordOperation"/>
<param
value="net.didion.jwnl.dictionary.morph.LookupExceptionsOperation"/>
<param
value="net.didion.jwnl.dictionary.morph.DetachSuffixesOperation">
<param name="noun"
value="|s=|ses=s|xes=x|zes=z|ches=ch|shes=sh|men=man|ies=y|"/>
<param name="verb"
value="|s=|ies=y|es=e|es=|ed=e|ed=|ing=e|ing=|"/>
<param name="adjective" value="|er=|est=|er=e|est=e|"/>
<param name="operations">
<param value=
"net.didion.jwnl.dictionary.morph.LookupIndexWordOperation"/>
<param value=
"net.didion.jwnl.dictionary.morph.LookupExceptionsOperation"/>
</param>
</param>
</param>
</param>
</param>
</param>
<param name="dictionary_element_factory" value=
"net.didion.jwnl.princeton.data.PrincetonWN17FileDictionaryElementFactory"/>
<param name="file_manager" value=
"net.didion.jwnl.dictionary.file_manager.FileManagerImpl">
<param name="file_type" value=
"net.didion.jwnl.princeton.file.PrincetonRandomAccessDictionaryFile"/>
<param name="dictionary_path" value="/home/mark/WordNet-3.0/dict/"/>
</param>
</dictionary>
<resource class="PrincetonResource"/>
</jwnl_properties>
There are three things in this file which you need to configure based upon the version of WordNet you wish to use. Firstly change the number attribute of the version element to match the version of WordNet you are using. Then edit the value of the dictionary_path parameter to point to your local installation of WordNet (this is /usr/share/wordnet/ if you have installed the Ubuntu or Debian wordnet-base package.)
Finally, if you want to use version 1.6 of WordNet then you also need to alter the dictionary_element_factory to use net.didion.jwnl.princeton.data.PrincetonWN16FileDictionaryElementFactory. For full details of the format of the configuration file see the JWNL documentation at http://sourceforge.net/projects/jwordnet.
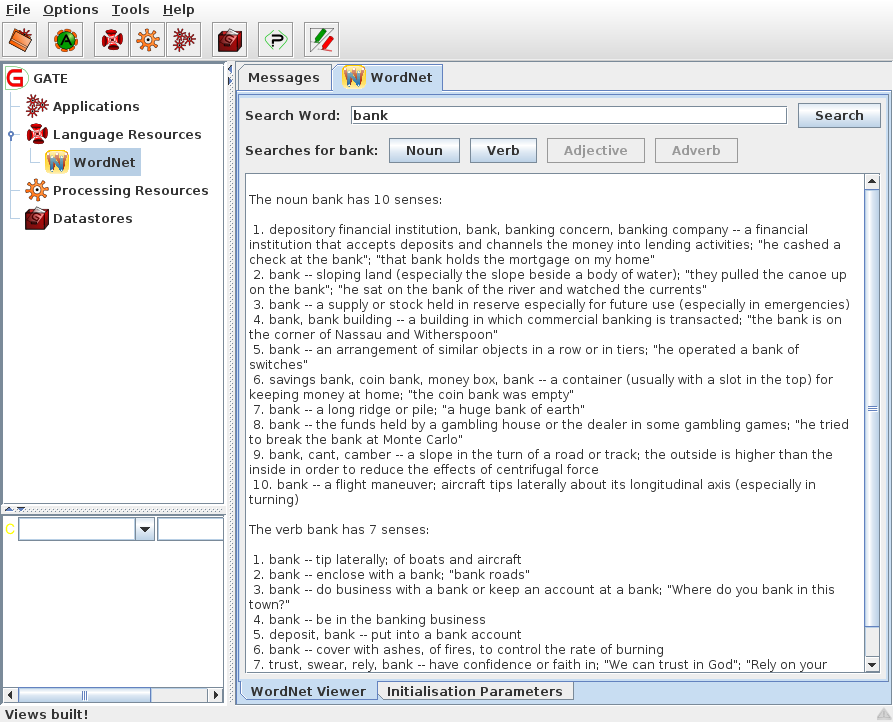
After configuring GATE to use WordNet, you can start using the built-in WordNet browser or API. In GATE Developer, load the WordNet plugin via the Plugin Management Console. Then load WordNet by selecting it from the set of available language resources. Set the value of the parameter to the path of the xml properties file which describes the WordNet location (wn-config).
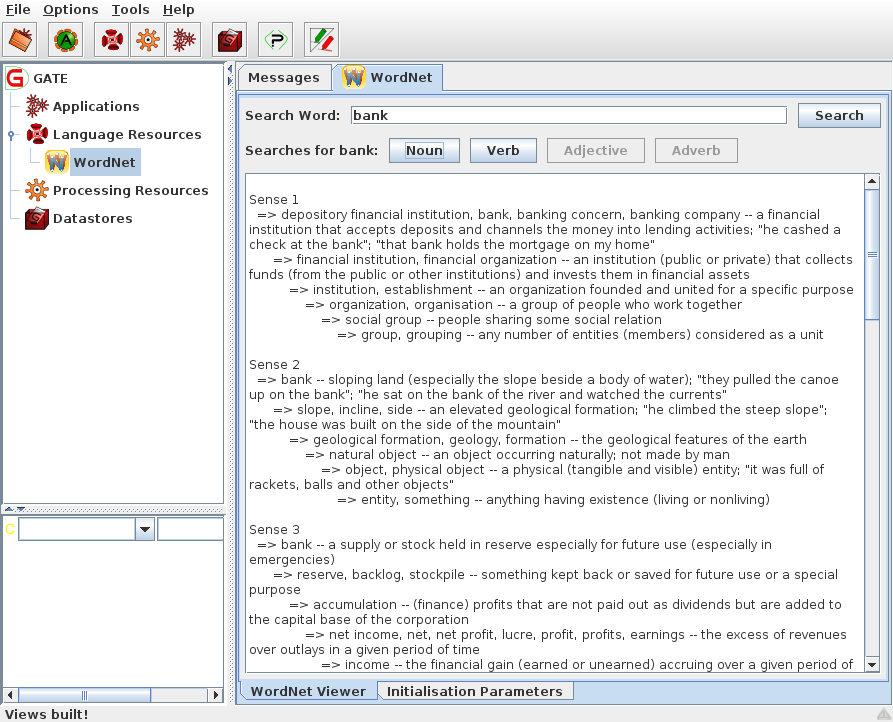
Once WordNet is loaded in GATE Developer, the well-known interface of WordNet will appear. You can search Word Net by typing a word in the box next to to the label ‘SearchWord” and then pressing ‘Search’. All the senses of the word will be displayed in the window below. Buttons for the possible parts of speech for this word will also be activated at this point. For instance, for the word ‘play’, the buttons ‘Noun’, ‘Verb’ and ‘Adjective’ are activated. Pressing one of these buttons will activate a menu with hyponyms, hypernyms, meronyms for nouns or verb groups, and cause for verbs, etc. Selecting an item from the menu will display the results in the window below.
To upgrade any existing GATE applications to use this improved WordNet plugin simply replace your existing configuration file with the example above and configure for WordNet 1.6. This will then give results identical to the previous version – unfortunately it was not possible to provide a transparent upgrade procedure.
More information about WordNet can be found at http://wordnet.princeton.edu/
More information about the JWNL library can be found at http://sourceforge.net/projects/jwordnet
An example of using the WordNet API in GATE is available on the GATE examples page at http://gate.ac.uk/wiki/code-repository/index.html.
23.16.1 The WordNet API
GATE Embedded offers a set of classes that can be used to access the WordNet Lexical Database. The implementation of the GATE API for WordNet is based on Java WordNet Library (JWNL). There are just a few basic classes, as shown in Figure 23.7. Details about the properties and methods of the interfaces/classes comprising the API can be obtained from the JavaDoc. Below is a brief overview of the interfaces:
-
WordNet: the main WordNet class. Provides methods for getting the synsets of a lemma, for accessing the unique beginners, etc.
-
Word: offers access to the word’s lemma and senses
-
WordSense: gives access to the synset, the word, POS and lexical relations.
-
Synset: gives access to the word senses (synonyms) in the synset, the semantic relations, POS etc.
-
Verb: gives access to the verb frames (not working properly at present)
-
Adjective: gives access to the adj. position (attributive, predicative, etc.).
-
Relation: abstract relation such as type, symbol, inverse relation, set of POS tags, etc. to which it is applicable.
-
LexicalRelation
-
SemanticRelation
-
VerbFrame
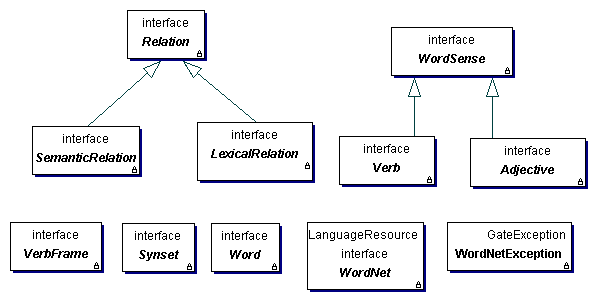
23.17 Kea - Automatic Keyphrase Detection [#]
Kea is a tool for automatic detection of key phrases developed at the University of Waikato in New Zealand. The home page of the project can be found at http://www.nzdl.org/Kea/.
This user guide section only deals with the aspects relating to the integration of Kea in GATE. For the inner workings of Kea, please visit the Kea web site and/or contact its authors.
In order to use Kea in GATE Developer, the ‘Keyphrase_Extraction_Algorithm’ plugin needs to be loaded using the plugins management console. After doing that, two new resource types are available for creation: the ‘KEA Keyphrase Extractor’ (a processing resource) and the ‘KEA Corpus Importer’ (a visual resource associated with the PR).
23.17.1 Using the ‘KEA Keyphrase Extractor’ PR
Kea is based on machine learning and needs to be trained before it can be used to extract keyphrases. In order to do this, a corpus is required where the documents are annotated with keyphrases. Corpora in the Kea format (where the text and keyphrases are in separate files with the same name but different extensions) can be imported into GATE using the ‘KEA Corpus Importer’ tool. The usage of this tool is presented in a subsection below.
Once an annotated corpus is obtained, the ‘KEA Keyphrase Extractor’ PR can be used to build a model:
-
load a ‘KEA Keyphrase Extractor’
-
create a new ‘Corpus Pipeline’ controller.
-
set the corpus for the controller
-
set the ‘trainingMode’ parameter for the PR to ‘true’
-
set the ‘inputAS’ parameter for the PR to ‘Key’ (or wherever the ‘Keyphrase’ annotations are to be found)
-
run the application.
After these steps, the Kea PR contains a trained model. This can be used immediately by switching the ‘trainingMode’ parameter to ‘false’ and running the PR over the documents that need to be annotated with keyphrases. Another possibility is to save the model for later use, by right-clicking on the PR name in the right hand side tree and choosing the ‘Save model’ option.
When a previously built model is available, the training procedure does not need to be repeated, the existing model can be loaded in memory by selecting the ‘Load model’ option in the PR’s context menu.
The Kea PR uses several parameters as seen in Figure 23.8:
-
document
-
The document to be processed.
-
inputAS
-
The input annotation set. This parameter is only relevant when the PR is running in training mode and it specifies the annotation set containing the keyphrase annotations.
-
outputAS
-
The output annotation set. This parameter is only relevant when the PR is running in application mode (i.e. when the ‘trainingMode’ parameter is set to false) and it specifies the annotation set where the generated keyphrase annotations will be saved.
-
minPhraseLength
-
the minimum length (in number of words) for a keyphrase.
-
minNumOccur
-
the minimum number of occurrences of a phrase for it to be a keyphrase.
-
maxPhraseLength
-
the maximum length of a keyphrase.
-
phrasesToExtract
-
how many different keyphrases should be generated.
-
keyphraseAnnotationType
-
the type of annotations used for keyphrases.
-
dissallowInternalPeriods
-
should internal periods be disallowed.
-
trainingMode
-
if ‘true’ the PR is running in training mode; otherwise it is running in application mode.
-
useKFrequency
-
should the K-frequency be used.
23.17.2 Using Kea Corpora
The authors of Kea provide on the project web page a few manually annotated corpora that can be used for training Kea. In order to do this from within GATE, these corpora need to be converted to the format used in GATE (i.e. GATE documents with annotations). This is possible using the ‘KEA Corpus Importer’ tool which is available as a visual resource associated with the Kea PR. The importer tool can be made visible by double-clicking on the Kea PR’s name in the resources tree and then selecting the ‘KEA Corpus Importer’ tab, see Figure 23.9.
The tool will read files from a given directory, converting the text ones into GATE documents and the ones containing keyphrases into annotations over the documents.
The user needs to specify a few values:
-
Source Directory
-
the directory containing the text and key files. This can be typed in or selected by pressing the folder button next to the text field.
-
Extension for text files
-
the extension used for text fields (by default .txt).
-
Extension for keyphrase files
-
the extension for the files listing keyphrases.
-
Encoding for input files
-
the encoding to be used when reading the files (to work propertly all the .txt and .key files must be in the same encoding).
-
Corpus name
-
the name for the GATE corpus that will be created.
-
Output annotation set
-
the name for the annotation set that will contain the keyphrases read from the input files.
-
Keyphrase annotation type
-
the type for the generated annotations.
Sample training and test sets are available from the KEA Github repository2 for English, French, and Spanish.
23.18 Annotation Merging Plugin [#]
If we have annotations about the same subject on the same document from different annotators, we may need to merge the annotations.
This plugin implements two approaches for annotation merging.
MajorityVoting takes a parameter numMinK and selects the annotation on which at least numMinK annotators agree. If two or more merged annotations have the same span, then the annotation with the most supporters is kept and other annotations with the same span are discarded.
MergingByAnnotatorNum selects one annotation from those annotations with the same span, which the majority of the annotators support. Note that if one annotator did not create the annotation with the particular span, we count it as one non-support of the annotation with the span. If it turns out that the majority of the annotators did not support the annotation with that span, then no annotation with the span would be put into the merged annotations.
The annotation merging methods are available via the Annotation Merging plugin. The plugin can be used as a PR in a pipeline or corpus pipeline. To use the PR, each document in the pipeline or the corpus pipeline should have the annotation sets for merging. The annotation merging PR has no loading parameters but has several run-time parameters, explained further below.
The annotation merging methods are implemented in the GATE API, and are available in GATE Embedded as described in Section 7.18.
-
annSetOutput: the annotation set in the current document for storing the merged annotations. You should not use an existing annotation set, as the contents may be deleted or overwritten.
-
annSetsForMerging: the annotation sets in the document for merging. It is an optional parameter. If it is not assigned with any value, the annotation sets for merging would be all the annotation sets in the document except the default annotation set. If specified, it is a sequence of the names of the annotation sets for merging, separated by ‘;’. For example, the value ‘a-1;a-2;a-3’ represents three annotation set, ‘a-1’, ‘a-2’ and ‘a-3’.
-
annTypeAndFeats: the annotation types in the annotation set for merging. It is an optional parameter. It specifies the annotation types in the annotation sets for merging. For each type specified, it may also specify an annotation feature of the type. The parameter is a sequence of names of annotation types, separated by ‘;’. A single annotation feature can be specified immediately following the annotation type’s name, separated by ‘->’ in the sequence. For example, the value ‘SENT->senRel;OPINION_OPR;OPINION_SRC->type’ specifies three annotation types, ‘SENT’, ‘OPINION_OPR’ and ‘OPINION_SRC’ and specifies the annotation feature ‘senRel’ and ‘type’ for the two types SENT and OPINION_SRC, respectively but does not specify any feature for the type OPINION_OPR. If the annTypeAndFeats parameter is not set, the annotation types for merging are all the types in the annotation sets for merging, and no annotation feature for each type is specified.
-
keepSourceForMergedAnnotations: should source annotations be kept in the annSetsForMerging annotation sets when merged? True by default.
-
mergingMethod: specifies the method used for merging. Possible values are MajorityVoting and MergingByAnnotatorNum, referring to the two merging methods described above, respectively.
-
minimalAnnNum: specifies the minimal number of annotators who agree on one annotation in order to put the annotation into merged set, which is needed by the merging method MergingByAnnotatorNum. If the value of the parameter is smaller than 1, the parameter is taken as 1. If the value is bigger than total number of annotation sets for merging, it is taken to be total number of annotation sets. If no value is assigned, a default value of 1 is used. Note that the parameter does not have any effect on the other merging method MajorityVoting.
23.19 Copying Annotations between Documents [#]
Sometimes a document has two copies, each of which was annotated by different annotators for the same task. We may want to copy the annotations in one copy to the other copy of the document. This could be in order to use less resources, or so that we can process them with some other plugin, such as annotation merging or IAA. The Copy_Annots_Between_Docs plugin does exactly this.
The plugin is available with the GATE distribution. When loading the plugin into GATE, it is represented as a processing resource, Copy Anns to Another Doc PR. You need to put the PR into a Corpus Pipeline to use it. The plugin does not have any initialisation parameters. It has several run-time parameters, which specify the annotations to be copied, the source documents and target documents. In detail, the run-time parameters are:
-
sourceFilesURL specifies a directory in which the source documents are in. The source documents must be GATE xml documents. The plugin copies the annotations from these source documents to target documents.
-
inputASName specifies the name of the annotation set in the source documents. Whole annotations or parts of annotations in the annotation set will be copied.
-
annotationTypes specifies one or more annotation types in the annotation set inputASName which will be copied into target documents. If no value is given, the plugin will copy all annotations in the annotation set.
-
outputASName specifies the name of the annotation set in the target documents, into which the annotations will be copied. If there is no such annotation set in the target documents, the annotation set will be created automatically.
The Corpus parameter of the Corpus Pipeline application containing the plugin specifies a corpus which contains the target documents. Given one (target) document in the corpus, the plugin tries to find a source document in the source directory specified by the parameter sourceFilesURL, according to the similarity of the names of the source and target documents. The similarity of two file names is calculated by comparing the two strings of names from the start to the end of the strings. Two names have greater similarity if they share more characters from the beginning of the strings. For example, suppose two target documents have the names aabcc.xml and abcab.xml and three source files have names abacc.xml, abcbb.xml and aacc.xml, respectively. Then the target document aabcc.xml has the corresponding source document aacc.xml, and abcab.xml has the corresponding source document abcbb.xml.
23.20 LingPipe Plugin [#]
LingPipe is a suite of Java libraries for the linguistic analysis of human language3. We have provided a plugin called ‘LingPipe’ with wrappers for some of the resources available in the LingPipe library. In order to use these resources, please load the ‘LingPipe’ plugin. Currently, we have integrated the following five processing resources.
-
LingPipe Tokenizer PR
-
LingPipe Sentence Splitter PR
-
LingPipe POS Tagger PR
-
LingPipe NER PR
-
LingPipe Language Identifier PR
Please note that most of the resources in the LingPipe library allow learning of new models. However, in this version of the GATE plugin for LingPipe, we have only integrated the application functionality. You will need to learn new models with Lingpipe outside of GATE. We have provided some example models under the ‘resources’ folder which were downloaded from LingPipe’s website. For more information on licensing issues related to the use of these models, please refer to the licensing terms under the LingPipe plugin directory.
Due to licensing conditions LingPipe is still a directory plugin and does not appear in the default list of plugins shown in the plugin manager. To use the plugin you will need to download the latest release from https://github.com/GateNLP/gateplugin-LingPipe/releases and then add it as a directory plugin via the plugin manager.
23.20.1 LingPipe Tokenizer PR [#]
As the name suggests this PR tokenizes document text and identifies the boundaries of tokens. Each token is annotated with an annotation of type ‘Token’. Every annotation has a feature called ‘length’ that gives a length of the word in number of characters. There are no initialization parameters for this PR. The user needs to provide the name of the annotation set where the PR should output Token annotations.
23.20.2 LingPipe Sentence Splitter PR [#]
As the name suggests, this PR splits document text in sentences. It identifies sentence boundaries and annotates each sentence with an annotation of type ‘Sentence’. There are no initialization parameters for this PR. The user needs to provide name of the annotation set where the PR should output Sentence annotations.
23.20.3 LingPipe POS Tagger PR [#]
The LingPipe POS Tagger PR is useful for tagging individual tokens with their respective part of speech tags. Each document must already have been processed with a tokenizer and a sentence splitter (any kinds in GATE, not necessarily the LingPipe ones) since this PR has Token and Sentence annotations as prerequisites. This PR adds a category feature to each token.
This PR requires a model (dataset from training the tagger on a tagged corpus), which must be provided as an initialization parameter. Several models are included in this plugin’s resources directory. Additional models can be downloaded from the LingPipe website4 or trained according to LingPipe’s instructions5.
Two models for Bulgarian are now available in GATE: bulgarian-full.model and bulgarian-simplified.model, trained on a transformed version of the BulTreeBank-DP [Osenova & Simov 04, Simov & Osenova 03, Simov et al. 02, Simov et al. 04a]. The full model uses the complete tagset [Simov et al. 04b] whereas the simplified model uses tags truncated before any hyphens (for example, Pca–p, Pca–s-f, Pca–s-m, Pca–s-n, and Pce-as-m are all merged to Pca) to improve performance. This reduces the set from 573 to 249 tags and saves memory.
This PR has the following run-time parameters.
-
inputASName
-
The name of the annotation set with Token and Sentence annotations.
-
applicationMode
-
The POS tagger can be applied on the text in three different modes.
-
FIRSTBEST
-
The tagger produces one tag for each token (the one that it calculates is best) and stores it as a simple String in the category feature.
-
CONFIDENCE
-
The tagger produces the best five tags for each token, with confidence scores, and stores them as a Map<String, Double> in the category feature. This application mode requires more memory than the others.
-
NBEST
-
The tagger produces the five best taggings for the whole document and then stores one to five tags for each token (with document-based scores) as a Map<String, List<Double» in the category feature. This application mode is noticeably slower than the others.
-
23.20.4 LingPipe NER PR [#]
The LingPipe NER PR is used for named entity recognition. The PR recognizes entities such as Persons, Organizations and Locations in the text. This PR requires a model which it then uses to classify text as different entity types. An example model is provided under the ‘resources’ folder of this plugin. It must be provided at initialization time. Similar to other PRs, this PR expects users to provide name of the annotation set where the PR should output annotations.
23.20.5 LingPipe Language Identifier PR [#]
As the name suggests, this PR is useful for identifying the language of a document or span of text. This PR uses a model file to identify the language of a text. A model is provided in this plugin’s resources/models subdirectory and as the default value of this required initialization parameter. The PR has the following runtime parameters.
-
annotationType
-
If this is supplied, the PR classifies the text underlying each annotation of the specified type and stores the result as a feature on that annotation. If this is left blank (null or empty), the PR classifies the text of each document and stores the result as a document feature.
-
annotationSetName
-
The annotation set used for input and output; ignored if annotationType is blank.
-
languageIdFeatureName
-
The name of the document or annotation feature used to store the results.
Unlike most other PRs (which produce annotations), this one adds either document features or annotation features. (To classify both whole documents and spans within them, use two instances of this PR.) Note that classification accuracy is better over long spans of text (paragraphs rather than sentences, for example). More information on the languages supported can be found in the LingPipe documentation.
23.21 OpenNLP Plugin [#]
OpenNLP provides java-based tools for sentence detection, tokenization, pos-tagging, chunking, parsing, named-entity detection, and coreference. See the OpenNLP website for details.
In order to use these tools via GATE Cloud, see
In order to use these tools as GATE processing resources, load the ‘OpenNLP’ plugin via the Plugin Management Console. Alternatively, the OpenNLP system for English can be loaded from the GATE GUI by simply selecting Applications → Ready Made Applications → OpenNLP → OpenNLP IE System. Two sample applications are also provided for Dutch and German in this plugin’s resources directory, although you need to download the relevant models from Sourceforge.
We have integrated six OpenNLP tools into GATE processing resources:
-
OpenNLP Tokenizer
-
OpenNLP Sentence Splitter
-
OpenNLP POS Tagger
-
OpenNLP Chunker
-
OpenNLP Parser
-
OpenNLP NER (named entity recognition)
In general, these PRs can be mixed with other PRs of similar types. For example, you could create a pipeline that uses the OpenNLP Tokenizer, and the ANNIE POS Tagger. You may occasionally have problems with some combinations, and different OpenNLP models use different POS and chunk tags. Notes on compatibility and PR prerequisites are given for each PR in the sections below.
Note also that some of the OpenNLP tools use quite large machine learning models, which the PRs need to load into memory. You may find that you have to give additional memory to GATE in order to use the OpenNLP PRs comfortably. See the FAQ on the GATE Wiki for an example of how to do this.
23.21.1 Init parameters and models [#]
Most OpenNLP PRs have a model parameter, a URL that points to a valid maxent model trained for the relevant tool. (The OpenNLP POS tagger no longer requires a separate dictionary file.)
Because the NER PR uses multiple models, it has a config parameter, a URL that points to a configuration file, described in more detail in Section 23.21.2; the sample files models/english/en-ner.conf and models/dutch/nl-ner.conf can be easily copied, modified, and imitated.
For details of training new models (outside of the GATE framework), see Section 23.21.3
23.21.2 OpenNLP PRs [#]
OpenNLP Tokenizer [#]
This PR has no prerequisites. It adds Token and SpaceToken annotations to the annotationSetName run-time parameter’s set. Both kinds of annotations get a feature source=OpenNLP, and Token annotations get a string feature with the underlying string as its value.
OpenNLP Sentence Splitter [#]
This PR has no prerequisites. It adds Sentence annotations (with a feature and value source=OpenNLP) and Split annotations (similar to ANNIE’s, with the same kind feature, as described in Section 23.21) to the annotationSetName run-time parameter’s set.
OpenNLP POS Tagger [#]
This PR adds a category feature to each Token annotation.
This PR requires Sentence and Token annotations to be present in the annotation set specified by inputASName. (They do not have to come from OpenNLP PRs.) If the outputASName is different, this PR will copy each Token annotation and add the category feature to the output copy.
The tagsets vary according to the models.
OpenNLP NER (NameFinder) [#]
This PR finds standard named entities and adds annotations for them.
This PR requires Sentence and Token annotations to be present in the annotation set specified by the inputASName run-time parameter. (They do not have to come from OpenNLP PRs.) The Token annotations do not need to have a category feature (so a POS tagger is not a prerequisite to this PR).
This PR creates annotations in the outputASName run-time parameter’s set with types specified in the configuration file, whose URL was specified as an init parameter so it cannot be changed after initialization. (The contents of the config file and the files it points to, however, can be changed—reinitializing the PR clears out any models in memory, reloads the config file, and loads the models now specified in that file.) A configuration file should consist of two whitespace-separated columns, as in this example.
en-ner-date.bin Date en-ner-location.bin Location en-ner-money.bin Money en-ner-organization.bin Organization en-ner-percentage.bin Percentage en-ner-person.bin Person en-ner-time.bin Time
The first entry in each row contains a path to a model file (relative to the directory where the config file is located, so in this example the models are all in the same directory with the config file), and the second contains the annotation type to be generated from that model. More than one model file can generate the same annotation type.
OpenNLP Chunker [#]
This PR marks noun, verb, and other chunks using features on Token annotations.
This PR requires Sentence and Token annotations to be present in inputASName run-time parameter’s set, and requires category features on the Token annotations (so a POS tagger is a prerequisite).
If the outputASName and inputASName run-time parameters are the same, the PR adds a feature named according to the chunkFeature run-time parameter to each Token annotation. If the annotation sets are different, the PR copies each Token and adds the feature to the output copy. The feature uses the common BIO values, as in the following examples:
-
-
B-NP token begins of a noun phrase;
-
-
I-NP token is inside a noun phrase;
-
-
B-VP token begins a verb phrase;
-
-
I-VP token is inside a verb phrase;
-
-
O token is outside any phrase;
-
-
B-PP token begins a prepositional phrase;
-
-
B-ADVP token begins an adverbial phrase.
OpenNLP Parser [#]
This PR performs a syntactic parse. It expects Sentence and Token annotations to be present in the annotation set specified by inputASName (they do not necessarily have to come from OpenNLP PRs), and will create SyntaxTreeNode annotations in the same set to represent the parse results. These node annotations are compatible with the GATE Developer syntax tree viewer provided in the Tools plugin.
23.21.3 Obtaining and generating models [#]
More models for various languages are available to download from Sourceforge. The OpenNLP tools (outside of GATE) can be used to produce additional models fro training corpora; please refer to the OpenNLP document for details.
23.22 Stanford CoreNLP [#]
GATE supports some of the NLP tools from Stanford, collectively known as Stanford CoreNLP. It currently supports named entity recognition, part-of-speech tagging, and parsing. Note that Stanford CoreNLP models are often not compatible between its different versions.
23.22.1 Stanford Tagger [#]
This tool is a cyclic-dependency based machine-learning PoS tagger [Toutanova et al. 03]. To use the Stanford Part-of-Speech tagger6 within GATE you need first to load the Stanford_CoreNLP plugin.
The PR is configured using the following initialization time parameters:
-
modelFile: the URL to the POS tagger model. This defaults to a fast English model but further models for other languages are available from the tagger’s homepage.
Further configuration of the tagger is via the following runtime parameters:
-
baseSentenceAnnotationType: the input annotation type which represents sentences; defaults to Sentence.
-
baseTokenAnnotationType: the input annotation type which represents tokens; defaults to Token
-
failOnMissingInputAnnotations: if true and no annotations of the types specified in the previous two options are found then an an exception will be thrown halting any further processing. If false, a warning will be printed instead and processing will continue. Defaults to true to help quickly catch misconfiguration during application development.
-
inputASName: the name of the annotation set that serves as input to the tagger (i.e. where the tagger will look for sentences and tokens to process); defaults to the default unnamed annotation set.
-
outputASName: the name of the annotation set into which the results of running the tagger will be stored; defaults to the default unnamed annotation set.
-
outputAnnotationType: the annotation type which will be created, or updated, with the results of running the tagger; defaults to Token.
-
posTagAllTokens: if true all tokens will be processed, including those that do not fall within a sentence; defaults to true.
-
useExistingTags: if true, any tokens that already have a “category” feature will be assumed to have been pre-tagged, and these tags will be preserved. Furthermore, the pre-existing tags for these tokens will be fed through to the tagger and may influence the tags of their surrounding context by constraining the possible sequences of tags for the sentence as a whole (see also [Derczynski et al. 13]). If false, existing category features are ignored and overwritten with the output of the tagger. Defaults to true.
23.22.2 Stanford Parser [#]
The GATE interface to the Stanford Parser is detailed in Section 18.2.
23.22.3 Stanford Named Entity Recognition [#]
Stanford NER provides a CRF-based approach to finding named entity chunks [Finkel et al. 05], based on an externally-learned model file.
The PR is configured using the following initialization time parameters:
-
modelFile: the URL to the named entity recognition model. This defaults to a fast English model but further models for other languages are available from downloads on the Stanford NER homepage.
Further configuration of the NER tool is via the following runtime parameters:
-
baseSentenceAnnotationType: the input annotation type which represents sentences; defaults to Sentence.
-
baseTokenAnnotationType: the input annotation type which represents tokens; defaults to Token
-
failOnMissingInputAnnotations: if true and no annotations of the types specified in the previous two options are found then an an exception will be thrown halting any further processing. If false, a warning will be printed instead and processing will continue. Defaults to true to help quickly catch misconfiguration during application development.
-
inputASName: the name of the annotation set that serves as input to the tagger (i.e. where the tagger will look for sentences and tokens to process); defaults to the default unnamed annotation set.
-
outputASName: the name of the annotation set into which the results of running the tagger will be stored; defaults to the default unnamed annotation set.
-
outsideLabel: the label assigned to tokens outside of an entity; e.g., the “O" in a BIO labelling scheme; defaults to O.
23.23 Content Detection Using Boilerpipe [#]
When working in a closed domain it is often possible to craft a few JAPE rules to separate real document content from the boilerplate headers, footers, menus, etc. that often appear, especially when dealing with web documents. As the number of document sources increases, however, it becomes difficult to separate content from boilerplate using hand crafted rules and a more general approach is required.
The ‘Tagger_Boilerpipe’ plugin contains a PR that can be used to apply the boilerpipe library (see http://code.google.com/p/boilerpipe/) to GATE documents in order to annotate the content sections. The boilerpipe library is based upon work reported in [Kohlschütter et al. 10], although it has seen a number of improvements since then. Due to the way in which the library works not all features are currently available through the GATE PR.
The PR is configured using the following runtime parameters:
-
allContent: this parameter defines how the mime type parameter should be interpreted and if documents should, instead of being processed, by assumed to contain nothing but actual content. defaults to ‘If Mime Type is NOT Listed’ which means that any document with a mime type not listed is assumed to be all content.
-
annotateBoilerplate: should we annotate the boilerplate sections of the document, defaults to false.
-
annotateContent: should we annotate the main content of the document, defaults to true.
-
boilerplateAnnotationName: the name of the annotation type to annotate sections determined to be boilerplate, defaults to ‘Boilerplate’. Whilst this parameter is optional it must be specified if annotateBoilerplate is set to true.
-
contentAnnotationName: the name of the annotation type to annotate sections determined to be content, defaults to ‘Content’. Whilst this parameter is optional it must be specified if annotateContent is set to true.
-
debug: if true then annotations created by the PR will contain debugging info, defaults to false.
-
extractor: specifies the boilerpipe extractor to use, defaults to the default extractor.
-
failOnMissingInputAnnotations: if the input annotations (Tokens) are missing should this PR fail or just not do anything, defaults to true to allow obvious mistakes in pipeline configuration to be captured at an early stage.
-
inputASName: the name of the input annotation set
-
mimeTypes: a set of mime types that control document processing, defaults to text/html. The exact behaviour of the PR is dependent upon both this parameter and the value of the allContent parameter.
-
ouputASName: the name of the output annotation set
-
useHintsFromOriginalMarkups: often the original markups will provide hints that may be useful for correctly identifying the main content of the document. If true, useful markup (currently the title, body, and anchor tags) will be used by the PR to help detect content, defaults to true.
If the debug option is set to true, the following features are added to the content and boilerplate annotations (see the Boilerpipe library for more information):
-
ld: link density (float)
-
nw: number of words (int)
-
nwiat: number of words in anchor text (int)
-
end: block end offset (int)
-
start: block start offset (int)
-
tl: tag level (int)
-
td: text density (float)
-
content: is the text block content (boolean)
-
nwiwl: number of words in wrapped lines (int)
-
nwl: number of wrapped lines (int)
23.24 Inter Annotator Agreement
The IAA plugin, “Inter_Annotator_Agreement”, computes interannotator agreement measures for various tasks. For named entity annotations, it computes the F-measures, namely Precision, Recall and F1, for two or more annotation sets. For text classification tasks, it computes Cohen’s kappa and some other IAA measures which are more suitable than the F-measures for the task. This plugin is fully documented in Section 10.5. Chapter 10 introduces various measures of interannotator agreement and describes a range of tools provided in GATE for calculating them.
23.25 Schema Annotation Editor
The plugin ‘Schema_Annotation_Editor’ constrains the annotation editor to permitted types. See Section 3.4.6 for more information.
23.26 Coref Tools Plugin [#]
The ‘Coref_Tools’ plugin provides a framework for co-reference type tasks, with a main focus on time efficiency. Included is the OrthoRef PR, that uses the Coref Framework to perform orthographic co-reference, in a manner similar to the Orthomatcher 6.8.
The principal elements of the Coref Framework are defined as follows:
-
anaphor
-
an annotation that is a reference to some real-world entity. Examples include Person, Location, Organization.
-
co-reference
-
two anaphors are said to be co-referring when they refer to the same entity.
-
Tagger
-
a software module that emits a set of tags (arbitrary strings) when provided with an anaphor. When two anaphors have tags in common, that is an indication that they may be co-referring.
-
Matcher
-
a software module that checks whether two anaphors are co-referring or not.
The plugin also includes the gate.creole.core.CorefBase abstract class that implements the following workflow:
-
enumerate all anaphors in the input document. This selects all annotations of types marked as input in the configuration file, and sorts them in the order they appear in the document.
-
for each anaphor:
-
obtain the set of associated tags, by interrogating all taggers registered for that annotation type;
-
construct a list of antecedents, containing the previous anaphors that have tags in common with the current anaphor. For each of them:
-
find all the matchers registered for the correct anaphor and antecedent annotation type.
-
antecedents for which at least on matcher confirms a positive match get added to the list of candidates.
-
-
generate a coref relation between the current anaphor and the most recent candidate.
-
The CorefBase class is a Processing Resource implementation and accepts the following parameters:
-
annotationSetName
-
a String value, representing the name of the annotation set that contains the anaphor annotations. The resulting relations are produced in the relation set associated with this annotation set (see Section 7.7 for technical details).
-
configFileUrl
-
a java.net.URL value, pointing to a file in the format specified below that describes the set of taggers and matchers to be used.
-
maxLookBehind
-
an Integer value, specifying the maximum distance between the current anaphor and the most distant antecedent that should be considered. A value of 1 requires the system to only consider the immediately preceding antecedent; the default value is 10. To disable this function, set this parameter to a negative value, in which case all antecedents will be considered. This is probably not a good idea in the general co-reference setting, as it will likely produce undesired results. The execution speed will also be negatively affected on very large documents.
The most important parameter listed above is configFileUrl, which should point to a file describing which taggers and matchers should be used. The file should be in XML format, and the easiest way of producing one is to modify the provided example. From a technical point of view, the configuration file is actually an XML serialisation of a gate.creole.coref.Config object, using the XStream library ( http://xstream.codehaus.org/). The XStream serialiser is configured to make the XML file more user-friendly and less verbose. A shortened example is included below for reference:
2 <taggers>
3 <default.taggers.DocumentText annotationType="Organization"/>
4 <default.taggers.Initials annotationType="Organization"/>
5 <default.taggers.MwePart annotationType="Organization"/>
6 ...
7 </taggers>
8
9 <matchers>
10 <!−− ## Organization ## −−>
11 <!−− Identity −−>
12 <default.matchers.DocumentText annotationType="Organization"
13 antecedentType="Organization"/>
14
15 <!−− Heuristics, but only if they match all references
16 in the chain −−>
17 <default.matchers.TransitiveAnd annotationType="Organization"
18 antecedentType="Organization">
19 <default.matchers.Or annotationType="Organization"
20 antecedentType="Organization">
21 <!−− Identical references always match −−>
22 <default.matchers.DocumentText annotationType="Organization"
23 antecedentType="Organization"/>
24 <default.matchers.Initials annotationType="Organization"
25 antecedentType="Organization"/>
26 <default.matchers.MwePart annotationType="Organization"
27 antecedentType="Organization"/>
28 </default.matchers.Or>
29 </default.matchers.TransitiveAnd>
30
31 ...
32 </matchers>
33</coref.Config>
Actual co-reference PRs can be implemented by extending the CorefBase class and providing appropriate default values for some of the parameters, and, if required, additional functionality.
The Coref_Tools plugin includes some ready-made Tagger and Matcher implementations.
The following Taggers are available:
-
Alias
-
This tagger requires an external configuration file, containing aliases, e.g. person names and associated nicknames. Each line in the configuration file contains the base form, the alias, and optionally a confidence score, all separated by tab characters. If the document text for the provided anaphor (or any of its parts in the case of multi-word expressions) is a known base form or an alias, then the tagger will emit both the base form and the alias as tags.
-
AnnType
-
A tagger that simply returns the annotation type for the given anaphor.
-
Collate
-
A compound tagger that wraps a list of sub-taggers. For each anaphor it produces a set of tags that consists of all possible combinations of tags produced by its sub-taggers.
-
DocumentText
-
A simple tagger that uses the normalised document text as a tag. The normalisation performed includes removing whitespace at the start and end of the annotations, and replacing all internal sequences of whitespace with a single space character.
-
FixedTags
-
A tagger that always returns the same fixed set of tags, regardless of the provided anaphor.
-
Initials
-
If the document text for the provided anaphor is a multi-word-expression, where each constituent starts with an upper case letter, this tagger returns two tags: one containing the initials, and the other containing the initials, each followed by a full stop. For example, Internation Business Machines would produce IBM and I.B.M..
-
MwePart
-
If the document text for the provided anaphor is a multi-word-expression, where each constituent starts with an upper case letter, this tagger returns the set of constituent parts as tags.
The following Matchers are available:
-
Alias
-
A matcher that matches when the document text for the anaphor and the antecedent (or their constituent parts, in the case of multi-word expressions) are aliases of each other.
-
And
-
A compound matcher that matches when all of its sub-matchers match.
-
AnnType
-
A matcher that matches when the annotation type for the anaphor and its antecedent are the same.
-
DocumentText
-
A matcher that matches if the normalised document text of the anaphor and its antecedent are the same.
-
False
-
A matcher that never matches.
-
Initials
-
A matcher that matches when the document texts for the anaphor and its antecedent are initials of each other.
-
MwePart
-
A matcher that matches when the anaphor and its antecedent are a multi-word-expression and one of its parts, respectively.
-
Or
-
A compound matcher that matches when any of its sub-matchers match.
-
TransitiveAnd
-
A matcher that wraps a sub-matcher. Given an anaphor and an antecedent, the following workflow is followed:
-
calculate the coref transitive closure for the antecedent: a set containing the antecedent, and all the annotations that are in a coref relation with another annotation from this set).
-
return a positive match if and only if the provided anaphor matches all the antecedents in the closure set, according to the wrapped sub-matcher.
-
-
True
-
A matcher that always matches.
The OrthoRef Processing Resource included in the plugin uses some of these taggers and matchers to perform orthographic co-reference. This means anaphors are considered to be co-referent or not based on similarities between their surface forms (the document text). The OrthoRef PR also serves as an example of how to use the Coref framework.
Also included with the Coref_Tools plugin is a Processing Resource named Legacy Coref Data Writer. Its role is convert to eh relations-based co-reference data into document features into the legacy format used by the Coref Editor. This PR constitutes a bridge between the new relations-based data model and the old document features based one.
23.27 Pubmed Format [#]
This plugin contains format analysers for the textual formats used by PubMed7 and the Cochrane Library8. The title and abstract of the input document are used to produce the content for the GATE document; all other fields are converted into GATE document features.
To use it, simply load the Format_Pubmed plugin; this will register the document formats with GATE.
If the input files use .pubmed.txt or .cochrane.txt extensions, then GATE should automatically find the correct document format. If your files come with different extensions, then you can force the use of the correct document format by explicitly specifying the mime type value as text/x-pubmed or text/x-cochrane, as appropriate. This will work both when directly creating a new GATE document and when populating a corpus.
23.28 MediaWiki Format [#]
This plugin contains format analysers for documents using MediaWiki markup9.
To use it, simply load the Format_MediaWiki plugin; this will register the document formats with GATE. When loading a document into GATE you must then specify the appropriate mime type: text/x-mediawiki for plain text documents containing MediaWiki markup, or text/xml+mediawiki for XML dump files (such as those produced by Wikipedia10). This will work both when directly creating a new GATE document and when populating a corpus.
Note that if loading an XML dump file containing more than one page, then you should right click on the corpus you wish to populate and choose the "Populate from MediaWiki XML Dump" option rather than creating a single document from the XML file.
23.29 Fast Infoset Document Format [#]
Fast Infoset11 is a binary compression format for XML that when used to store GATE XML files gives a space saving of, on average, 80%. Fast Infoset documents are also quicker to load than the same document stored as XML (about twice as fast in some small experiments with GATE documents). This makes Fast Infoset an ideal encoding for the long term storage of large volumes of prcoessed GATE documents.
In order to read and write Fast Infoset documents you need to load the Format_FastInfoset plugin to register the document format with GATE. The format will automatically be used to load documents with the .finf extension or when the MIME type is expicitly set to application/fastinfoset. This will work both when directly creating a single new GATE document and when populating a corpus.
Single documents or entire corpora can be exported as Fast Infoset files from within GATE Developer by choosing the "Save as Fast Infoset XML" option from the right-click menu of the relevant corpus or document.
A GCP12 output handler is also provided by the Format_FastInfoset plugin.
23.30 GATE JSON Document Format [#]
The Format_JSON plugin provides support for a storing GATE documents as JSON files. This format supports round tripping; i.e. documents saved in this format can be reloaded into GATE without loss of information.
The format is inspired by the original Twitter JSON format (i.e. prior to the addition of the extended information in the Twitter JSON to support 280 characters and quoted tweets). In essense each document is saved to a JSON object which contains two properties text and entities.
The text field is simply the text of the document, while the entities field contains the annotations and their features. The format of this field is that same as that used by Twitter to store entities, namely a map from annotation type to an array of objects each of which contains the offsets of the annotation as "indices":[start,end] and any other properties which become features of the entity annotation. The indices count in terms of Unicode characters or “codepoints”, i.e. supplementary characters such as emoji count as one “place” – this is different from how GATE (and Java in general) count string offsets but the format handles the conversion automatically.
{
"text": "This is the text of an example document",
"entities": {
"Token":[
{"indices": [0,4], "string": "This"},
{"indices": [5,7], "string": "is"},
...
],
"DocType":[
{"indices": [23,30], "kind": "example"}
]
}
}
You can load documents using this format by specifying text/json as the mime type. If your JSON documents don’t quite match this format you can still extract the text from them by specifying the path through the JSON to the text element as a dot separated string as a parameter to the mime type. For example, assume the text in your document was in a field called text but this wasn’t at the root of the JSON document but inside an object named document, then you would load this by specifying the mime type text/json;text-path=document.text.
{
"metadata":{ ... },
"document":{
"text": "This JSON has its text more deeply nested"
}
}
The plugin also provides a new right-click action for Corpora allowing a file containing multiple JSON objects in a single file to be split into individual documents to populate the corpus. This can handle multiple multiple objects in one file, represented as any of:
-
a top-level JSON array [{...},{...}]
-
or simply concatenated together, optionally with white space or newline characters between adjacent objects (this is the format returned by Twitter’s streaming APIs).
23.31 Bdoc Format (JSON, YAML, MsgPack) [#]
The Format_Bdoc plugin provides support for a storing GATE documents as JSON, YAML, compressed JSON, compressed YAML and MsgPack files. This format supports round tripping; i.e. documents saved in this format can be reloaded into GATE without loss of information.
The format is different from the “GATE JSON Document Format” in what representation is used for the JSON / YAML / MsgPack serialization which is closer to the abstractions GATE uses.
The format is inspired by the original Twitter JSON format (i.e. prior to the addition of the extended information in the Twitter JSON to support 280 characters and quoted tweets). In essense each document is saved to a JSON object which contains two properties text and entities.
The documentation for this plugin is online here https://gatenlp.github.io/gateplugin-Format_Bdoc/
The JSON/YAML/MsgPack serializations can also be read and written by the Python gatenlp package ( https://gatenlp.github.io/python-gatenlp/)
23.32 DataSift Document Format [#]
The Format_DataSift plugin provides support for loading JSON files in the DataSift format into GATE. The format will automatically be used when loading documents with the datasift.json extension of when the MIME type is explicityl set to text/x-json-datasift.
Documents loaded using this plugin are constructed by conconcatenating the content property of each Interaction map within the JSON file. An Interaction annotation is created over the relevant text spans and all other associated data is added to the annotations FeatureMap.
23.33 CSV Document Support [#]
The Format_CSV plugin provides support for both importing from a CSV (Comma Separated Value) file and exporting annnotations into CSV files.
As CSV files vary widly in their content, support for loading such files is provided through a new right-click option on corpus instances. This new option will display a dialog which allows you to choose the CSV file (if you select a directory then it will process all CSV files within the directory), which column contains the text data (note that the columns are numbered from 0 upwards), if the first row contains column labels, and if one GATE document should be created per CSV file or per row within a file.
If you create a new document per row, then a further option allows you to state that the document cell contains not the text of the document but the URL of the document which should be loaded. This not only allows you to refer to external documents from within a large CSV file, but you can also use this feature to populate a corpus from a plain text file with just one URL per line should you find that useful. Please note that no rate limiting is implemented within this feature so you may need to be careful about the number of rows processed if they all refer to the same external domain etc.
As mentioned the plugin also supports exporting of annotations to a CSV file. This support is accessed via the usual “Save as...” menu available on both documents and corpora. The export is configured via the following parameters:
-
annoationSetName: The annotation set from which to read annotations
-
annotationType: Produce one row per annotation of this type, or one row per document if this is not set (which is the default).
-
columnHeaders: a list of static strings to use as the first row, i.e. column headings, of the output file.
-
columns: List of columns to produce. These are defined as <Annotation>.<Feature>. If you have just .<Feature> then that is assumed to be a document feature, whereas just <Annotation> is the text under the annotation. Note that if more than one instance of an annotation type appears within the document (or specifiec annotationType) only the first will be output.
-
containedOnly: if true (which is the default) only use annotations strictly within the row annotation (i.e. the value of annotationType), else allow those which partially overlap.
-
encoding: the character encoding used to save the output file. This defaults to UTF-8 which is probably the best choice in most cases.
-
quoteCharacter: the character used to quote text fields when necessary. This defaults to ' which means that within a cell ' will be escaped (this is done by duplicating the character).
-
separatorCharacter: the character used to separate the columns in the exported file. This defaults to using a comma to generate a CSV file but you can use \t if you want to generate a TSV (Tab Separated File) instead of a CSV.
23.34 TermRaider term extraction tools [#]
TermRaider is a set of term extraction and scoring tools developed in the NeOn and ARCOMEM projects. Although some parts of the plugin are still experimental, we are now including it in GATE as a response to frequent requests from GATE users who have read publications related to those projects.
The easiest way to try TermRaider is to populate a corpus with related documents, load the sample application (plugins/TermRaider/applications/termraider-eng.gapp), and run it. This application will process the documents and create instances of three termbank language resources with sensible parameters.
All the language resources in TermRaider are serializable and can be stored in GATE datastores.
23.34.1 Termbank language resources [#]
A Termbank is a GATE language resource derived from term candidate annotations on one or more GATE corpora. All termbanks have the following init parameters.
-
corpora: a Set<gate.Corpus> from which the termbank is generated.
-
inputASName (String): the annotation set name in which to find the term candidates.
-
inputAnnotationTypes (Set<String>): annotation types which are treated as term candidates.
-
inputAnnotationFeature (String): the feature of each annotation used as the term string (if the feature is missing from the annotation, the underlying document content will be whitespace-trimmed and used). Note that these values are case-sensitive; normally the lemma (root feature from the GATE Morphological Analyser) is used for consistency.
-
languageFeature (String): the feature of each annotation identifying the language of the term. (Annotations without the feature will get an empty string as a language code, which can match language-coded terms more flexibly in some situations.)
-
scoreProperty (String): a description of the principal output score, used in the termbank’s GUI and CSV output and in the Termbank Score Copier PR. (A sensible default is provided for each termbank type.)
-
debugMode (Boolean): this sets the verbosity of the output while creating the termbank.
Each type of termbank has one or more score types, shown as columns in the Details tab of the GUI and listed in the Type pull-down menu in the Term Cloud tab. The first score is always the principal one named by the scoreProperty parameter above.
The Term class is defined in terms of the term string itself, the language code, and the annotation type, so it is possible (after preprocessing the documents properly) to distinguish affect(english, Noun) from affect(english, Verb), and gift(english, Noun) from gift(german, Noun).
DocumentFrequencyBank [#]
This termbank counts the number of documents in which each term is found, and is used primarily as input to the TfIdf Termbank. Document frequency can thus be determined from a reference corpus in advance and used in subsequent calcuations of tf.idf over other corpora. This type of termbank has only the principal score type.
A document frequency bank can be constructed from one or more corpora, from one or more existing document frequency banks, or from a combination of both, so that document frequency counts from different sources can be compiled together.
It has two additional parameters:
-
inputBanks zero or more other instances of DocumentFrequencyBank.
-
segmentAnnotationType if this is left blank (the default), a term’s frequency is determined by the number of whole documents in which it is found; if an annotation type is specified, the frequency is the number of instances of that annotation type in which the term is found (and terms found outside of the segments are ignored).
When a TfIdf Termbank queries this type of termbank for the reference document frequency, it asks for a strictly matching term (same string, language code, and annotation type), but if that is not found, a lax match is used (if the requested term or the matching term has an empty language code—in case some applications have been run without language identification PRs). If the term is not in the DocumentFrequencyBank at all, 0 is returned. (The idf calculation, described in the next section, has +1 terms to prevent division by zero.)
TfIdf Termbank [#]
This termbank calculates tf.idf scores over all the term candidates in the set of corpora. It has the following additional init parameters.
-
docFreqSource: an instance of DocumentFrequencyBank, which could be derived from another set of corpora (as described above); if this parameter is null (<none> in the GUI), an instance of DocumentFrequencyBank will be constructed from this LR’s corpora parameter and used here.
-
idfCalculation: an enum (pull-down menu in the GUI) with the following options for adjusting inverted document frequency (all adjusted to prevent division by zero):
-
LogarithmicScaled: idf = log 2
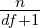 ;
;
-
Logarithmic: idf = log 2
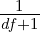 ;
;
-
Scaled: idf =
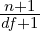 ;
;
-
Natural: idf =
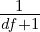 .
.
-
-
tfCalculation: an enum (pull-down) with the following options for adjusting term frequency:
-
Natural: atf = tf ;
-
Sqrt: atf =
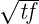 ;
;
-
Logarithmic: atf = 1 + log 2tf .
-
-
normalization: an enum (pull-down) with the following options for normalizing the raw score s, where s = atf ×idf :
-
None: s′ = s (this may return numbers in a low range);
-
Hundred: s′ = 100s (this makes the sliders easier to use);
-
Sigmoid: s′ =
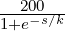 − 100 (this maps all raw scores monotonically to values in
the 0–100 range, so that 0→0 and ∞→100).
− 100 (this maps all raw scores monotonically to values in
the 0–100 range, so that 0→0 and ∞→100).
-
For the calculations above, tf is the term frequency (number of individual occurrences of the term in the current corpora), whereas df is the document frequency of the term according to the DocumentFrequencySource and n is the total number of documents in the DocumentFrequencySource. The raw (unnormalized) score s = atm ×idf .
This type of termbank has five score types: the principal one (normalized, s′ above), the raw score (s above, with the principal name plus the suffix “.raw”), termFrequency, localDocFrequency (number of documents in the current corpora containing the term; not used in the tf.idf calculation), and refDocFrequency (df above; this will be the same as localDocFrequency if no other docFreqSource was specified).
Annotation Termbank [#]
This termbank collects the values of scoring features on all the term candidate annotations, and for each term determines the minimum, maximum, or mean according to the mergingMode parameter. It has the following additional parameters.
-
inputScoreFeature: an annotation feature whose value should be a Number or interpretable as a number.
-
mergingMode: an enum (pull-down menu in the GUI) with the options MINIMUM, MEAN, or MAXIMUM.
-
normalization: the same normalization options as for the TfIdf Termbank above. To produce augmented tf.idf scores (as in the sample application), it is generally better to augment the tfIdfScore.raw values, compile them into an Annotation Termbank, and normalize the results (rather than carrying out augmentation on the normalized tf.idf scores).
This type of termbank has four score types: the principal one (normalized), the raw score (minimum, maximum, or mean, determined as described above; with the principal name plus the suffix “.raw”), termFrequency, and localDocFrequency (the last two are not used in the calculation).
Hyponymy Termbank [#]
This termbank calculates KYOTO Domain Relevance [Bosma & Vossen 10] over all the term candidates. It has the following additional init parameter.
-
inputHeadFeatures (List<String>): annotation features on term candidates containing the head of the expression.
-
normalization: the same normalization options as for the TfIdf Termbank above.
Head information is generated by the multiword JAPE grammar included in the application. This LR treats T1 a hyponym of T0 if and only if T0’s head feature’s value ends with T1’s head or string feature’s value. (This depends on head-final construction of compound nouns, as used in English and German.) The raw score s(T0) = df × (1 + h), where h is the number of hyponyms of T0.
This type of termbank has five score types: the principal one (normalized), the raw score (s above, with the principal name plus the suffix “.raw”), termFrequency (not used in the scoring), hyponymCount (number of distinct hyponyms found in the current corpora), and localDocFrequency.
23.34.2 Termbank Score Copier [#]
This processing resource copies the scores from a termbank onto features of the term annotations. It has no init parameters and two runtime parameters.
-
annotationSetName
-
termbank
This PR uses the annotation types, string and language code features, and scores from the selected termbank. It treats any annotation with a matching type and matching string and language feature as a match (although a missing language feature matches the empty string used as a “not found” code), and copies all the termbank’s scores to features on the annotation with the scores’ names. (The principal score name is determined by the termbank’s scoreProperty feature.)
23.34.3 The PMI bank language resource [#]
Like termbanks, the PMI Bank is a GATE language resource derived from annotations on one or more GATE corpora. The PMI Bank, however, works on collocations—pairs of “inner” annotations (e.g., Token or named entity types) within a sliding window defined as a number of “outer” annotations (usually 1 or 2 Sentence annotations).
The documents need to be processed to create the required inner and outer annotations, as shown in the pmi-example.gapp sample application provided in this plugin. The PMI Bank can then be created with the following init parameters.
-
allowOverlapCollocations
-
default false
-
corpora
-
-
debugMode
-
default false
-
innerAnnotationTypes
-
default [Entity]
-
inputASName
-
-
inputAnnotationFeature
-
default canonical
-
languageFeature
-
default lang
-
outerAnnotationType
-
default Sentence
-
outerAnnotationWindow
-
default 2
-
requireTypeDifference
-
default false
-
scoreProperty
-
default pmiScore
23.35 Document Normalizer [#]
A problem that occurs quite frequently when processing text documents created with modern WYSIWYG editors (Word is the main culprit) is that standard punctuation symbols, such as apostrophes and hyphens, are silently replaced by symbols that look “nicer”. While there may be a good reason behind this substitution (i.e. printouts look better) it plays havoc with text processing. For example, a tokenizer that handles words with apostrophes in them will produce different output, and gazetteers are likely to use standard ASCII characters for hyphens and apostrophise.
Whilst it may be possible to modify all processing resources to handle all different forms of each punctuation symbol it would be both a tedious and error prone process. A better solution would be to modify the documents as part of the processing pipeline to replace these characters with their normalized version.
This plugin normalizes the punctuation (or any other characters) by editing the document content to replace them. Note that as this plugin edits the document content it should be run as the first PR in the pipeline in order to avoid problems with changes in annotation spans etc.
The normalizations are controlled via a simple configuration file in which a pair of lines describes a single normalization; the first line is a regular expression describing the text to replace, and the second line is the replacement.
23.36 Developer Tools [#]
The Developer Tools plugin currently contains five tools useful for developers of either GATE itself or plugins and applications.
The ‘EDT Monitor’ is useful when developing GUI code and will print a warning when any Swing component is updated from anywhere but the Event Dispatch Thread. Updating Swing components from the wrong thread can lead to unexpected behaviour, including the UI locking up, so any reported issues should be investigated. All issues are reported to the console rather than the message pane as updates to the message pane may not appear if the UI is locked.
The ‘Show/Hide Resources’ tool adds a new entry to the right-click menu of all resources allowing them to be hidden from the GUI. On it’s own this is not particularly useful, but it also provides a Tool menu entry to show all hidden resources. This is useful for looking at PR instances created internally by other PRs etc.
‘The Duplicator’ tool adds a new entry to the right click-menu of all resources allowing them to be easily duplicated. This uses the Factory.duplicate(Resource) method and makes testing of custom duplication easy from within GATE Developer.
The ‘Java Heap Dumper’ tool adds a new entry to the Tools menu which allows a heap dump of the JVM in which GATE is running to be saved to a file of the users choosing from within the GUI.
The ‘Log4J Level: ALL’ tool adds a new entry to the Tools menu which switches the Log4J level of all loggers and appenders to ALL so that you can quickly see all logging activity in both the GUI and the log files.
23.37 Linguistic Simplifier [#]
This plugin provides a linguistically based document simplifier and is based upon work supported by the EU ForgetIT project.
The idea behind this plugin is to simplify sentences by removing words or phrases which are not required to convey the main point of the sentence. This can can be viewed as a first step in document summarization and also mirrors the way people remember conversations; the details and not the exact words used. The approach presented here uses accomplishes this task using a number of linguistically motived rules in conjunction with WordNet. Examples sentences which can be simplified include:
-
For some reason people will actually buy a pink coloured car.
-
The tub of ice-cream was unusually large in size.
-
There was a big explosion, which shook the windows, and people ran into the street.
-
The function of this department is the collection of accounts.
For best results the PR should be run after running the following pre-processing PRs: tokenizer, sentence splitter, POS tagger, morphological analyser, and the noun chunker. The output of the PR is stored as Redundant annotations (in the annotation set specified by the annotationSetName runtime parameter). To produce a simplified document the text under each Redundant annotation should be removed, and replaced, if present, by the annotations replacement feature. Two document exporter plugins are also provided to output simplified documents as either plain text or HTML.
The plugin contains a demo application (available from the Ready-Made menu if the plugin has been loaded), which allows the techniques to be demonstrated. The performance of the approach can be improved by passing a WordNet LR instance to the PR as a runtime param. This is not provided in the demo application, as it is not possible to provide this in an easily portable way. See Section 23.16 for details of how to load WordNet into GATE.
23.38 GATE-Time [#]
This plugin provides a number of components and applications for annotating time related information and events within documents.
23.38.1 DCTParser
If processing news (news-style and also colloquial) documents, it is important that later components (based around HeidelTime) know the document creation time (DCT) of the documents.
Note that it is not the time when the documents have been loaded into GATE. Instead, it is the time when the document was written, e.g., when a news document was published. To provide the DCT of a document / all documents in the corpus, the DCTParser can be used. It can be used in two ways:
-
to parse the DCT out of TimeML-style xml documents, e.g., the corpora TempEval-3 TimeBank, TempEval-3 Aquaint, and TempEval-3 platinum contain DCT information in this format. (cf. very last section)
-
to manually set the DCT for a document or a full corpus.
It is crucial to know that if a corpus contains many documents, then, the documents typically have differing DCTs. Currently, the DCT can only be parsed if it is available in TimeML-style format, or it can be manually provided for the document or the full corpus. If HeidelTime processes news doc- uments with wrong DCT information, relative and underspecified expressions will, of course, be normalized incorrectly. If the documents that are to be processed are narrative documents (e.g., Wikipedia documents), no document creation time is required. The HeidelTime GATE wrapper can handle this automatically if the domain of the HeidelTime component is set to “narratives” (see next section).
The DCTParser is configured through the following runtime parameters:
-
timeml or manualdate
-
name of the annotation set where DCT is stored
-
if format is set to “manualdate”, the user can set a date manually and this date is stored as DCT by DCTParser
-
name of annotation set for output
23.38.2 HeidelTime
HeidelTime can be used for many languages and four domains (in particular news and narrative, but also colloquial and autonomic for English — see Heideltime standalone Manual). Note that HeidelTime can perform linguistic preprocessing for all the languages if respective tools are installed correctly and configured correctly in the config.props file.
If processing HeidelTime narrative-style documents, it is not important that DCT information is available for the documents. If news-style (and colloquial) documents are processed, then DCT information is crucial and processing fails, if no DCT information is available. For this, creationDateAnnotationType has to contain information about the DCT annotation (see above).
HeidelTime can be used in such a way that the linguistic preprocessing is performed internally. For this further tools have to be set-up and the parameter doPreprocessing has to be set to true. In this case, some other parameters are ignored (about Sentence, Token, POS). If other preprocessing annotations shall be used (e.g., those of ANNIE) then doPreprocessing has to be set to false and the other parameters (about Sentence, Token, POS) have to be provided correctly.
HeidelTime is configured via three init parameters: different models have to be loaded depending on language and domain.
-
the location of the config.props file
-
narratives, news, colloquial, or scientific
-
english, german, dutch, .......
and the following runtime parameters:
-
if DCTParser is used to set the DCT, then the value is “DCT”
-
set to false to use existing annotations, true if you want HeidelTime to pre-process the document
-
name of annotation set, where token, sentence, pos information are stored (if any)
-
name of annotation set for output
-
name of the part-of-speech feature of the Token annotations (if using ANNIE, this is category)
-
type of the sentence annotation (if using ANNIE, this is Sentence)
-
type of the token annotation (if using ANNIE, this is Token)
23.38.3 TimeML Event Detection
The plugin also contains a “Ready Made” application for detecting TimeML based events.
23.39 StringAnnotation Plugin [#]
This plugin provides the ExtendedGazetter (see Section 13.11) and the FeatureGazetteer (see Section 13.12) and in addition the JavaRegexpAnnotator which makes it easy to use Java regular expressions to annotate GATE documents. An arbitrary number of regular expressions can be used and they can be matched using several different matching strategies. For each regular expression, new annotations and features can be created, optionally based on the content of matching groups from the regular expression.
More detailed documentation of the StringAnnotation plugin is available online at https://gatenlp.github.io/gateplugin-StringAnnotation, the documentation for the JavaRegexpAnnotation is at https://gatenlp.github.io/gateplugin-StringAnnotation/JavaRegexpAnnotator.
23.40 CorpusStats Plugin [#]
This plugin provides the following processing resources:
-
CorpusStatsTfIdfPR for gathering statistics on the frequencies of terms used in a corpus
-
CorposStatsCollocationsPR for gathering statistics on the frequencies of term pairs/collocations in a corpus
-
AssignStatsTfIdfPR for assigning the statistics previously gathered on a corpus to the terms in a document
These processing resources can be used with multiprocessing/duplication to process very large corpora.
More detailed documentation of the plugin is available online at https://gatenlp.github.io/gateplugin-CorpusStats/
23.41 ModularPipelines Plugin [#]
This plugin provides the following processing resources:
-
Pipeline PR for loading another pipeline from a file as part of a containing pipeline. This allows to build more complex pipelines by combining sub-pipelines which can be kept and maintained separately.
-
Parametrized Corpus Controller A conditional corpus controller which can be configured from a config file, i.e. the parameters of the contained processing resources can be set from the config file. This allows to run pipelines with different settings without changing the pipeline files.
More detailed documentation of the plugin is available online at https://github.com/GateNLP/gateplugin-ModularPipelines/wiki
23.42 Java Plugin [#]
This plugin provides the Java Scripting PR processing resource, which allows the use of Java code created/edited from within the GATE GUI to process GATE documents (similar to the Groov Scripting PR, see Section 7.16.2).
More detailed documentation of the plugin is available online at https://github.com/GateNLP/gateplugin-Java/wiki/JavaScriptingPR
23.43 Python Plugin [#]
This plugin provides the PythonPr processing resource, which allows the use of Python code created/edited from within the GATE GUI to process GATE documents.
The python code makes use of the Python gatenlp package to manipulate GATE documents.
More detailed documentation of the plugin is available online at http://gatenlp.github.io/gateplugin-Python/
More detailed documentation of the Python gatenlp package is available online at https://gatenlp.github.io/python-gatenlp/
1Java string escape sequences such as \t will be decoded before the template is expanded.
2see https://github.com/EUMSSI/KEA
3see http://alias-i.com/lingpipe/
4 http://alias-i.com/lingpipe/web/models.html
5 http://alias-i.com/lingpipe/demos/tutorial/posTags/read-me.html
6 http://www-nlp.stanford.edu/software/tagger.shtml
7 http://www.ncbi.nlm.nih.gov/pubmed/
8 http://www.thecochranelibrary.com/
9 http://www.mediawiki.org/wiki/Help:Formatting
10 http://en.wikipedia.org/wiki/Wikipedia:Database_download
