Chapter 22
GATE Cloud [#]
The growth of unstructured content on the internet has resulted in an increased need for researchers in diverse fields to run language processing and text mining on large-scale datasets, many of which are impossible to process in reasonable time on standard desktops. However, in order to take advantage of the on-demand compute power and data storage on the cloud, NLP researchers currently have to re-write/adapt their algorithms.
Therefore, we have now adapted the GATE infrastructure (and its JAPE rule-based and machine learning engines) to the cloud and thus enabled researchers to run their GATE applications without a significant overhead. In addition to lowering the barrier to entry, GATE Cloud also reduces the time required to carry out large-scale NLP experiments by allowing researchers to harness the on-demand compute power of the cloud.
Cloud computing means many things in many contexts. On GATECloud.net it means:
- zero fixed costs: you don’t buy software licences or server hardware, just pay for the compute time that you use
- near zero startup time: in a matter of minutes you can specify, provision and deploy the type of computation that used to take months of planning
- easy in, easy out: if you try it and don’t like it, go elsewhere! you can even take the software with you, it’s all open source
- someone else takes the admin load: - the GATE team from the University of Sheffield make sure you’re running the best of breed technology for text, search and semantics
- cloud providers’ data center managers (we use Amazon Inc.) make sure the hardware and operating platform for your work is scaleable, reliable and cheap
GATE is (and always will be) free, but machine time, training, dedicated support and bespoke development is not. Using GATECloud you can rent cloud time to process large batches of documents on vast server farms, or academic clusters. You can push a terabyte of annotated data into an index server and replicate the data across the world. Or just purchase training services and support for the various tools in the GATE family.
22.1 GATE Cloud services: an overview [#]
At the time of writing, there are several kinds of services, offerred from GATE Cloud, but they will be growing significantly over the course of the next six months, so for an up-to-date list see https://gatecloud.net/shopfront.
- GATE Annotation Services: these allow you to run a GATE application, on the cloud, over large document collections. The GATE application can be created by the user in GATE Developer and uploaded on the cloud, or users can use some pre-packaged applications, e.g., ANNIE, ANNIE with Number and Measurement add-ons.
- GATE Teamware (Chapter 23): a web-based collaborative annotation tool, that supports distributed teams of manual annotators and data managers/curators to produce gold-standard corpora for evaluation and training.
- GATE MIMIR (Chapter 24): a multi-paradigm information management index and repository which can be used to index and search over text, annotations, semantic schemas (ontologies), and semantic meta-data (instance data). It allows queries that arbitrarily mix full- text, structural, linguistic and semantic queries and that can scale to terabytes of text.
22.2 Comparison with other systems [#]
There are several other text-analysis-as-a-service systems out there that do some of what we do. Here are some differences:
- We’re the only open source solution.
- We’re the only customisable solution we support a bring-your-own-annotator option – a GATE pipeline – as well as pre-packaged entity annotation services like other systems.
- We’re the only end-to-end full lifecycle solution. We don’t just do entity extraction – we do data preparation, inter-annotator agreement, quality assurance and control, data visualisation, indexing and search of full text/annotation graph/ontology/instance store, etc. etc. etc.
- Bulk upload of documents to process, no need to use programming APIs.
- No recurring monthly costs, pay-per-use, billed per hour.
- No daily limit on number of documents to process.
- No limit on document size.
- Costs of processing dependent on overall data size, not number of documents.
- Web-based collaborative annotation tool to correct mistakes and create training and evaluation data (see Chapter 23).
- Speed: other systems price per document (we price on processing time) – this makes it impossible to compare like with like (do you really want to compare the processing of individual tweets against 200 page technical reports?!). GATECloud is also heavily optimised for high volumes – if you want to do low volumes, you can do them on your netbook.
- Community: we’ve been here for more than 15 years, and our community of developers, users, third party suppliers and so on is second to none.
22.3 How to buy services [#]
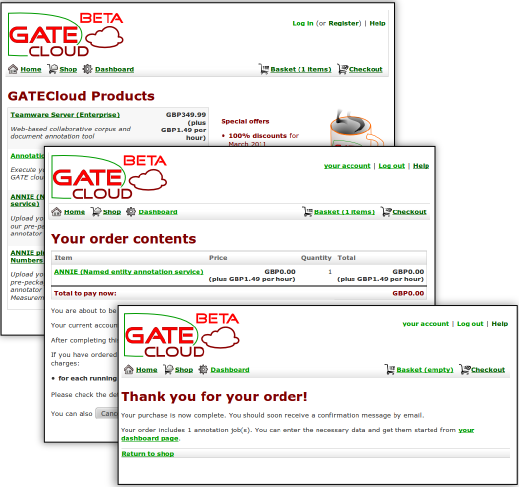
Before you can buy any of our cloud based offerings you need to create an account on GATECloud.net, use the Register link at the top right of any page and follow the instructions.
Once registered and logged in you can browse through the shop and decided on the services you wish to purchase.
The shop does not handle money but works instead with vouchers bought from the University of Sheffield’s on-line shop. Vouchers are available in multiples of £5, the amount you need to purchase will depend upon the services you wish to use. Once you are ready to buy time on GATECloud.net create an account with the University shop and then buy the appropriate amount credit vouchers. Be sure to use the same email address when buying vouchers as when registering for a GATECloud.net account so that credit you purchase can automatically be added to your GATECloud.net account.
Once you have enough credit you can click through to the checkout where you can review your basket before finalizing your order.
Annotation job purchases should appear instantly within your dashboard. Teamware servers take a little longer to create and we will e-mail you when the server is ready for use.
All past purchases can be monitored and controlled via your dashboard.
22.4 Pricing and discounts [#]
We run your jobs in the cloud and we pass on the cloud costs, plus a small premium. We do not have our own private cloud, so each job we run costs us money. Therefore we can’t run a zero cost service, but we do supply discounts and freebies for people wanting to try the service. To get a discount:
- create an account
- use the GATE Cloud contact page to send us your user name and request for discount
- we apply a pricing rule to your account
- you then shop in the normal manner, as described in Section 22.3 above.
A last word on pricing: the underlying software is all open source, so there’s nothing to stop you rolling your own if you can’t afford the cloud costs.
22.5 Annotation Jobs on GATECloud.net [#]
GATECloud.net annotation jobs provide a way to quickly process large numbers of documents using a GATE application, with the results exported to files in GATE XML or XCES format and/or sent to a Mimir server for indexing. Annotation jobs are optimized for the processing of large batches of documents (tens of thousands or more) rather than processing a small number of documents on the fly (GATE Developer is best suited for the latter).
To submit an annotation job you first choose which GATE application you want to run. GATECloud.net provides some standard pre-packaged applications (e.g., ANNIE), or you can provide your own application (see Section 22.6). You then upload the documents you wish to process packaged up into ZIP or (optionally compressed) TAR archives, or ARC files (as produced by the Heritrix web crawler), and decide which annotations you would like returned as output, and in what format.
When the job is started, GATECloud.net takes the document archives you provided and divides them up into manageable-sized batches of up to 15,000 documents. Each batch is then processed using the GATE paralleliser and the generated output files are packaged up and made available for you to download from the GATECloud.net site when the job has completed.
22.5.1 The Annotation Service Charges Explained
GATECloud.net annotation jobs run on a public commercial cloud, which charges us per hour for the processing time we consume. As GATECloud.net allows you to run your own GATE application, and different GATE applications can process radically different numbers of documents in a given amount of time (depending on the complexity of the application) we cannot adopt the "£x per thousand documents" pricing structure used by other similar services. Instead, GATECloud.net passes on to you, the user, the per-hour charges we pay to the cloud provider plus a small mark-up to cover our own costs.
For a given annotation job, we add up the total amount of compute time taken to process all the individual batches of documents that make up your job (counted in seconds), round this number up to the next full hour and multiply this by the hourly price for the particular job type to get the total cost of the job. For example, if your annotation job was priced at £1 per hour and split into three batches that each took 56 minutes of compute time then the total cost of the job would be £3 (178 minutes of compute time, rounded up to 3 hours). However, if each batch took 62 minutes to process then the total cost would be £4 (184 minutes, rounded up to 4 hours).
While the job is running, we apply charges to your account whenever a job has consumed ten CPU hours since the last charge (which takes considerably less than ten real hours as several batches will typically execute in parallel). If your GATECloud.net account runs out of funds at any time, all your currently-executing annotation jobs will be suspended. You will be able to resume the suspended jobs once you have topped up your account to clear the negative balance. Note that it is not possible to download the result files from completed jobs if your GATECloud.net account is overdrawn.
22.5.2 Annotation Job Execution in Detail
Each annotation job on GATECloud.net consists of a number of individual tasks:
- First a single "split" task which takes the initial document archives that were
provided when the job was configured and splits them into manageable batches for
processing.
- ARC files are not currently split - each complete ARC file will be processed as a single processing task.
- ZIP files that are smaller than 50MB will not be split, and will be processed as a single processing task.
- ZIP files larger than 50MB, and all TAR files, will be split into chunks of maximum size 50MB (compressed size) or 15,000 documents, whichever is the smaller. Each chunk will be processed as a separate processing task.
- One or more processing tasks, as determined by the split task described above. Each processing task will run the GATE application over the documents from its input chunk as defined by the input specification, and save any output files in ZIP archives of no more than 100MB, which will be available to download once the job is complete.
- A final "join" task to collate the execution logs from the processing tasks and produce an overall summary report.
Note that because ZIP and TAR input files may be split into chunks, it is important that each input document in the archive should be self-contained, for example XML files should not refer to a DTD stored elsewhere in the ZIP file. If your documents do have external dependencies such as DTDs then you have two choices, you can either (a) use GATE Developer to load your original documents and re-save them as GATE XML format (which is self contained), or (b) use a custom annotation job (see below) and include the additional files in your application ZIP, and refer to them using absolute paths.
22.6 Running Custom Annotation Jobs on GATECloud.net [#]
GATECloud.net provides a way for you to run pretty much any GATE application on the cloud. You develop your application in the usual way using GATE Developer and then save it as a single self-contained ZIP file, typically using the "Export for GATECloud.net" option. This section tells you what you need to know to ensure that your application will run on GATECloud.net.
22.6.1 Preparing Your Application: The Basics
You supply your GATE application to GATECloud.net as a single ZIP file, which is expected to contain a saved application state in the usual ".xgapp" format, along with all the GATE plugins, JAPE grammars and other resources that the application requires. The saved application state must be named application.xgapp and must be located at the ’root directory’ of the zip file (i.e. when the ZIP is unpacked it must leave a file named application.xgapp in the directory where the ZIP is unpacked and not in a sub-directory). All URL paths used by the application should be relative paths that do not contain any ’..’ components, so they will point to files in the same directory as application.xgapp or a sub-directory under this location.
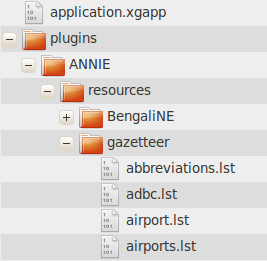
The easiest way to build such a package is simply to save your application in GATE Developer using the "Export for GATECloud.net" option, which produces a ZIP file containing an application.xgapp and all its required resources in one click.
22.6.2 The GATECloud.net environment
For many GATE applications that just use the standard pure-Java ANNIE components, the basic information above is all you need to know to run your application on GATECloud.net. But for more advanced applications that involve custom PRs, platform-specific native helpers (such as an external tagger), or other components that need to know the path where they are installed, you will need to know a little more about the environment in which your application will be running.
Hardware and software
GATECloud.net annotation jobs are executed on virtual 64-bit (x86_64) Linux servers in the cloud, specifically Ubuntu 10.10 (Maverick Meerkat). The GATE application is run using the open-source GCP tool1 on Sun Java 6 (1.6.0_21). The current offering uses the Amazon EC2 cloud, and runs jobs on their ’m1.xlarge’ machines which provide 4 virtual CPU cores and 15GB of memory, of which 13GB is available to the GCP process.
The GCP (GATE Cloud Paralleliser) process is configured for ’headless’ operation (-Djava.awt.headless=true), and your code should not assume that a GUI display is available.
GCP loads one copy of your application.xgapp in the usual way using the PersistenceManager. It then uses the GATE duplication mechanism to make a further 5 independent copies of the loaded application, and runs 6 parallel threads to process your documents. For most PRs this duplication process is essentially equivalent to loading the original application.xgapp 6 times but if you are writing a custom PR you may wish to consider implementing a custom duplication strategy.
Directories
The application ZIP file will always be unpacked in a directory named /gatecloud/application
on the cloud server. Thus the application file will always be
/gatecloud/application/application.xgapp and if any of your components need to
know the absolute path to their resource files you can work this out by prepending
/gatecloud/application/ to the path of the entry inside your ZIP package. The user account
that runs the GCP process has full read and write access in the /gatecloud/application
directory, so if any of your components need to create temporary files then this is a good place to
put them. Any files created under /gatecloud/application will be lost when the current batch of
documents has been processed.
The directory /gatecloud/batch/output is where GCP will write any output files specified by the output definitions you supply when running an annotation job. All files created under this directory will be packaged up into ZIP files when the batch of documents has been processed and made available for download when the job has completed. Thus, any additional output files that your application creates and that need to be returned to the user should be placed under /gatecloud/batch/output.
Your code should not assume it has permission to read and write any files outside these two locations.
Native code components
Many PRs are simply wrappers around non-Java tools, for example third-party taggers of various kinds. If your application requires the use of any non-Java components you must ensure that the version you include in your ZIP package is the one that will run on Linux x86_64, and in particular on Ubuntu 10.10. The cloud processing servers have a reasonable set of packages installed by default, including a basic install of Perl and Python, sed, awk and bash. To request additional packages please contact GATE Cloud support with your requirements. If you want to be sure your code will work on GATECloud.net then the best approach is to sign up for your own account at Amazon Web Services, run your own instance of the same machine image that GATECloud.net uses and test the software yourself. As Amazon charges by the hour with no up-front fees this should cost you very little.
As your code will be running in a Linux environment, remember that any native executable or script that your application needs to call must be marked with execute permission on the filesystem. GATECloud.net uses the standard Info-ZIP "unzip" tool to unpack the application ZIP package, which respects permission settings specified in the ZIP file, so if you build your package using the corresponding "zip" tool the permissions will be preserved. However, many ZIP file creation tools (including GATE’s "Export for GATECloud.net") do not preserve permissions in this way. Therefore GATECloud.net also supports an alternative mechanism to mark files as executable.
Once the application ZIP has been unpacked, we look through the resulting directory tree for files named .executables. If any such file is found, we treat each line in the file as a relative path, and set the execute flag on the corresponding file in the file system. For example, imagine the following structure:
plugins
- MyTagger
- resources
- tagger.sh
- postprocessor.pl
Here, tagger.sh and postprocessor.pl are scripts that need to be marked as executable, so we could create a file plugins/MyTagger/.executables containing the two lines:
resources/postprocessor.pl
or equivalently, create plugins/MyTagger/resources/.executables containing
postprocessor.pl
Either way, the effect would be to make the GATECloud.net processing machine mark the relevant files as executable before running your application.
Security and privacy
GATECloud.net does not run a separate machine for each annotation job. Instead it splits each annotation job up into manageable pieces (referred to as tasks), puts these tasks into a queue, and runs a collection of processing machines (referred to as "nodes") that simply take the next task from the queue whenever they have finished processing their previous task. While a task is running it has exclusive use of that particular node - we never run more than one task on the same node at the same time - but once the task is complete the same node will then run another task (which may or may not be part of the same annotation job).
To ensure the security and privacy of your code and data, the node takes the following precautions:
- All GCP processes are run as an unprivileged user account which only has write permission in a restricted area of the filesystem (see above).
- At the end of every task, all processes running under that user ID are forcibly terminated (so there’s no risk of a stray or malicious background process started by a previous task being able to read your data).
- The /gatecloud/application and /gatecloud/batch directories are completely deleted at the end of every task (whether the task completed successfully or failed) so your data will not be left for the following task to see.
1Source code is available in the subversion repository at
https://gate.svn.sourceforge.net/svnroot/gate/gcp/trunk
