Chapter 17
Parsers and Taggers [#]
17.1 Verb Group Chunker [#]
The rule-based verb chunker is based on a number of grammars of English [Cobuild 99, Azar 89]. We have developed 68 rules for the identification of non recursive verb groups. The rules cover finite (’is investigating’), non-finite (’to investigate’), participles (’investigated’), and special verb constructs (’is going to investigate’). All the forms may include adverbials and negatives. The rules have been implemented in JAPE. The finite state analyser produces an annotation of type ‘VG’ with features and values that encode syntactic information (‘type’, ‘tense’, ‘voice’, ‘neg’, etc.). The rules use the output of the POS tagger as well as information about the identity of the tokens (e.g. the token ‘might’ is used to identify modals).
The grammar for verb group identification can be loaded as a Jape grammar into the GATE architecture and can be used in any application: the module is domain independent.
17.2 Noun Phrase Chunker [#]
The NP Chunker application is a Java implementation of the Ramshaw and Marcus BaseNP chunker (in fact the files in the resources directory are taken straight from their original distribution) which attempts to insert brackets marking noun phrases in text which have been marked with POS tags in the same format as the output of Eric Brill’s transformational tagger. The output from this version should be identical to the output of the original C++/Perl version released by Ramshaw and Marcus.
For more information about baseNP structures and the use of transformation-based learning to derive them, see [Ramshaw & Marcus 95].
17.2.1 Differences from the Original
The major difference is the assumption is made that if a POS tag is not in the mapping file then it is tagged as ‘I’. The original version simply failed if an unknown POS tag was encountered. When using the GATE wrapper the chunk tag can be changed from ‘I’ to any other legal tag (B or O) by setting the unknownTag parameter.
17.2.2 Using the Chunker
The Chunker requires the Creole plugin ‘Parser_NP_Chunking’ to be loaded. The two loadtime parameters are simply urls pointing at the POS tag dictionary and the rules file, which should be set automatically. There are five runtime parameters which should be set prior to executing the chunker.
- annotationName: name of the annotation the chunker should create to identify noun phrases in the text.
- inputASName: The chunker requires certain types of annotations (e.g. Tokens with part of speech tags) for identifying noun chunks. This parameter tells the chunker which annotation set to use to obtain such annotations from.
- outputASName: This is where the results (i.e. new noun chunk annotations will be stored).
- posFeature: Name of the feature that holds POS tag information. ’
- unknownTag: it works as specified in the previous section.
The chunker requires the following PRs to have been run first: tokeniser, sentence splitter, POS tagger.
17.3 Tree Tagger [#]
The TreeTagger plugin (‘Tagger_TreeTagger’) has been deprecated in favour of the Tagger Framework plugin (‘Tagger_Framework’). The Tagger Framework is a generic wrapper around a number of different taggers including the TreeTagger. The TreeTagger plugin will be removed from future versions of GATE and so you should consider updating your applications to use the Tagger Framework, see Section 17.4 for full details.
The TreeTagger is a language-independent part-of-speech tagger, which currently supports English, French, German, Spanish, Italian and Bulgarian (although the latter two are not available in GATE). It is integrated with GATE using a GATE CREOLE wrapper, originally designed by the CLaC lab (Computational Linguistics at Concordia), Concordia University, Montreal (http://www.cs.concordia.ca/research/researchgroups/clac/).
The GATE wrapper calls TreeTagger as an external program, passing gate Tokens as input, and adding two new features to them, which hold the features as described below:
- Features of the TreeTaggerToken:
- category: the part-of-speech tag of the token;
- lemma: the lemma of the token
- Runtime parameters:
- document: the document to be processed
- treeTaggerBinary: a URL indicating the location of a (language-specific) GATE TreeTagger wrapper shell script. Note that the scripts used by GATE are different from the original TreeTagger scripts (in cmd), since the latter perform their own tokenisation, whereas the GATE scripts rely on Token annotations as they have been computed by a Tokeniser component. The GATE scripts reside in plugins/Tagger_TreeTagger/resources. Currently available are command scripts for German, French, and Spanish.
- encoding: The character encoding to use when passing data to and from the tagger. This must be ISO-8859-1 to work with the standard TreeTagger distribution – do not change it unless you know what you are doing.
- failOnUnmappableChar: What to do if a character is encountered in the document which cannot be represented in the selected encoding. If the parameter is true (the default), unmappable characters cause the wrapper to throw an exception and fail. If set to false, unmappable characters are replaced by question marks when the document is passed to the tagger. This is useful if your documents are largely OK but contain the odd character from outside the Latin-1 range.
- Requirement: The TreeTagger, which is available from
http://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger/DecisionTreeTagger.html,
must be correctly installed on the same machine as GATE. It must be installed in a directory
that does not contain any spaces in its path, otherwise the scripts will fail. Once the
TreeTagger is installed, the first two lines of the shell script may need to be modified to
indicate the installed location of the bin and lib directories of the tagger, as shown
below:
# THESE VARIABLES HAVE TO BE SET:
BIN=/usr/local/clactools/TreeTagger/bin
LIB=/usr/local/clactools/TreeTagger/lib
The TreeTagger plugin works on any platform that supports the tree tagger tool, including Linux, Mac OS X and Windows, but the GATE-specific scripts require a POSIX-style Bourne shell with the gawk, tr and grep commands, plus Perl for the Spanish tagger. For Windows this means that you will need to install the appropriate parts of the Cygwin environment from http://www.cygwin.com and set the system property treetagger.sh.path to contain the path to your sh.exe (typically C:\cygwin\bin\sh.exe). If this property is set, the TreeTagger plugin runs the shell given in the property and passes the tagger script as its first argument; without the property, the plugin will attempt to run the shell script directly, which fails on Windows with a cryptic ‘error=193’. For GATE Developer, put the following line in build.properties (see Section 2.3, and note the extra backslash before each backslash and colon in the path):
Figure 17.1 shows a screenshot of a French document processed with the TreeTagger.
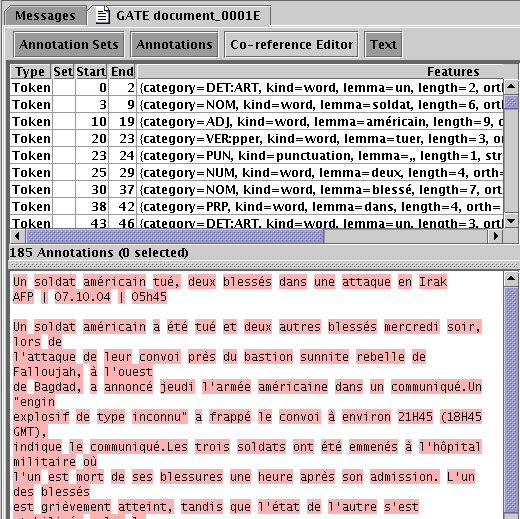
17.3.1 POS Tags
For English the POS tagset is a slightly modified version of the Penn Treebank tagset, where the second letter of the tags for verbs distinguishes between ‘be’ verbs (B), ‘have’ verbs (H) and other verbs (V).
The tagsets for French, German, Italian, Spanish and Bulgarian can be found in the original
TreeTagger documentation at
http://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger/DecisionTreeTagger.html..
17.4 TaggerFramework [#]
The Tagger Framework is an extension of work originally developed in order to provide support for the TreeTagger plugin within GATE. Rather than focusing on providing support for a single external tagger this plugin provides a generic wrapper that can easily be customised (no Java code is required) to incorporate many different taggers within GATE.
The plugin currently provides example applications (see plugins/Tagger_Framework/resources) for the following taggers: GENIA (a biomedical tagger), Hunpos (providing support for English and Hungarian), TreeTagger (supporting German, French, Spanish and Italian as well as English), and the Stanford Tagger (supporting English, German and Arabic).
The basic idea behind this plugin is to allow the use of many external taggers. Providing such a generic wrapper requires a few assumptions. Firstly we assume that the external tagger will read from a file and that the contents of this file will be one annotation per line (i.e. one token or sentence per line). Secondly we assume that the tagger will write it’s response to stdout and that it will also be based on one annotation per line – although there is no assumption that the input and output annotation types are the same.
- Initialization Parameters
- preProcessURL: The URL of a JAPE grammar that should be run over each document before running the tagger.
- postProcessURL: The URL of a JAPE grammar that should be run over each document after running the tagger. This can be used, for example, to add chunk annotations using IOB tags output by the tagger and stored as features on Token annotations.
- Runtime Parameters
- debug: if set to true then a whole heap of useful information will be printed to the messages tab as the tagger runs. Defaults to false.
- encoding: this must be set to the encoding that the tagger expects the input/output files to use. If this is incorrectly set is highly likely that either the tagger will fail or the results will be meaningless. Defaults to ISO-8859-1 as this seems to be the most commonly required encoding.
- failOnUnmappableCharacter: What to do if a character is encountered in the document which cannot be represented in the selected encoding. If the parameter is true (the default), unmappable characters cause the wrapper to throw an exception and fail. If set to false, unmappable characters are replaced by question marks when the document is passed to the tagger. This is useful if your documents are largely OK but contain the odd character from outside the Latin-1 range.
- regex: this should be a Java regular expression that matches a single line in the output from the tagger. Capturing groups should be used to define the sections of the expression which match the useful output.
- featureMapping: this is a mapping from feature name to capturing group in the regular expression. Each feature will be added to the output annotations with a value equal to the specified capturing group. For example, the TreeTagger uses a regular expression (.+)\t(.+)\t(.+) to capture the three column output. This is then combined with the feature mapping {string=1, category=2, lemma=3} to add the appropriate feature/values to the output annotations.
- inputASName: the name of the annotation set which should be used for input. If not specified the default (i.e. un-named) annotation set will be used.
- inputAnnotationType: the name of the annotation used as input to the tagger. This will usually be Token. Note that the input annotations must contain a string feature which will be used as input to the tagger. Tokens usually have this feature but if, for example, you wish to use Sentence as the input annotation then you will need to add the string feature. JAPE grammars for doing this are provided in plugins/Tagger_Framework/resources.
- outputASName: the name of the annotation set which should be used for output. If not specified the default (i.e. un-named) annotation set will be used.
- outputAnnotationType: the name of the annotation to be provided as output. This is usually Token.
- taggerBinary: a URL indicating the location of the external tagger. This is usually a shell script which may perform extra processing before executing the tagger. The plugins/Tagger_Framework/resources directory contains example scripts (where needed) for the supported taggers. These scripts may need editing (for example, to set the installation directory of the tagger) before they can be used.
- taggerDir: the directory from which the tagger must be executed. This can be left unspecified.
- taggerFlags: an ordered set of flags that should be passed to the tagger as command line options
- updateAnnotations: If set to true then the plugin will attempt to update existing output annotations. This can fail if the output from the tagger and the existing annotations are created differently (i.e. the tagger does it’s own tokenization). Setting this option to false will make the plugin create new output annotations, removing any existing ones, to prevent the two sets getting out of sync. This is also useful when the tagger is domain specific and may do a better job than GATE. For example, the GENIA tagger is better at tokenizing biomedical text than the ANNIE tokenizer. Defaults to true.
By default the GenericTagger PR simply tries to execute the taggerBinary using the normal Java Runtime.exec() mechanism. This works fine on Unix-style platforms such as Linux or Mac OS X, but on Windows it will only work if the taggerBinary is a .exe file. Attempting to invoke other types of program fails on Windows with a rather cryptic “error=193”.
To support other types of tagger programs such as shell scripts or Perl scripts, the GenericTagger PR supports a Java system property shell.path. If this property is set then instead of invoking the taggerBinary directly the PR will invoke the program specified by shell.path and pass the tagger binary as the first command-line parameter.
If the tagger program is a shell script then you will need to install the appropriate interpreter, such as sh.exe from the cygwin tools, and set the shell.path system property to point to sh.exe. For GATE Developer you can do this by adding the following line to build.properties (see Section 2.3, and note the extra backslash before each backslash and colon in the path):
Similarly, for Perl or Python scripts you should install a suitable interpreter and set shell.path to point to that.
You can also run taggers that are invoked using a Windows batch file (.bat). To use a batch file you do not need to use the shell.path system property, but instead set the taggerBinary runtime parameter to point to C:\WINDOWS\system32\cmd.exe and set the first two taggerFlags entries to “/c” and the Windows-style path to the tagger batch file (e.g. C:\MyTagger\runTagger.bat). This will cause the PR to run cmd.exe /c runTagger.bat which is the way to run batch files from Java.
17.5 Chemistry Tagger [#]
This GATE module is designed to tag a number of chemistry items in running text. Currently the tagger tags compound formulas (e.g. SO2, H2O, H2SO4 ...) ions (e.g. Fe3+, Cl-) and element names and symbols (e.g. Sodium and Na). Limited support for compound names is also provided (e.g. sulphur dioxide) but only when followed by a compound formula (in parenthesis or commas).
17.5.1 Using the Tagger
The Tagger requires the Creole plugin ‘Tagger_Chemistry’ to be loaded. It requires the following PRs to have been run first: tokeniser and sentence splitter (the annotation set containing the Tokens and Sentences can be set using the annotationSetName runtime parameter). There are four init parameters giving the locations of the two gazetteer list definitions, the element mapping file and the JAPE grammar used by the tagger (in previous versions of the tagger these files were fixed and loaded from inside the ChemTagger.jar file). Unless you know what you are doing you should accept the default values.
The annotations added to documents are ‘ChemicalCompound’, ‘ChemicalIon’ and ‘ChemicalElement’ (currently they are always placed in the default annotation set). By default ‘ChemicalElement’ annotations are removed if they make up part of a larger compound or ion annotation. This behaviour can be changed by setting the removeElements parameter to false so that all recognised chemical elements are annotated.
17.6 ABNER [#]
ABNER is A Biomedical Named Entity Recogniser. It uses machine learning (linear-chain conditional random fields, CRFs) to find entities such as genes, cell types, and DNA in text. Full details of ABNER can be found at http://pages.cs.wisc.edu/ bsettles/abner/
The ABNER plugin, called ‘Tagger_Abner’, contains a single PR, called AbnerTagger, which wraps ABNER. To use AbnerTagger, first load the Tagger_Abner plugin through the plugins console, and then create a new AbnerTagger PR in the usual way. The AbnerTagger PR has no loadtime parameters (apart from Name). It does not require any other PRs to be run prior to execution.
The AbnerTagger has two runtime parameters:
- abnerMode The Abner model that will be used for tagging. The plugin can use one
of two previously trained machine learning models for tagging text, as provided by
Abner:
- BIOCREATIVE trained on the BioCreative corpus
- NLPBA trained on the NLPBA corpus
- outputASName The name of the output annotation set to which AbnerTagger output will be written.
The AbnerTagger creates annotations of type ‘Tagger’ with a feature and value ‘source=abner’. Each annotation may also have features of ‘class’ and ‘type’ set by Abner to values such as:
- Protein
- DNA
- RNA
- Cell Line
- Cell Type
- Gene
Abner does support training of models on other data, but this functionality is not, however, supported by the GATE wrapper.
For further details please refer to the Abner documentation at http://pages.cs.wisc.edu/ bsettles/abner/
17.7 Stemmer [#]
The stemmer plugin, ‘Stemmer_Snowball’, consists of a set of stemmers PRs for the following 11 European languages: Danish, Dutch, English, Finnish, French, German, Italian, Norwegian, Portuguese, Russian, Spanish and Swedish. These take the form of wrappers for the Snowball stemmers freely available from http://snowball.tartarus.org. Each Token is annotated with a new feature ‘stem’, with the stem for that word as its value. The stemmers should be run as other PRs, on a document that has been tokenised.
There are three runtime parameters which should be set prior to executing the stemmer on a document.
- annotationType: This is the type of annotations that represent tokens in the document. Default value is set to ‘Token’.
- annotationFeature: This is the name of a feature that contains tokens’ strings. The stemmer uses value of this feature as a string to be stemmed. Default value is set to ‘string’.
- annotationSetName: This is where the stemmer expects the annotations of type as specified in the annotationType parameter to be.
17.7.1 Algorithms
The stemmers are based on the Porter stemmer for English [Porter 80], with rules implemented in Snowball e.g.
( [substring] among (
’sses’ (<-’ss’)
’ies’ (<-’i’)
’ss’ () ’s’ (delete)
)
17.8 GATE Morphological Analyzer [#]
The Morphological Analyser PR can be found in the Tools plugin. It takes as input a tokenized GATE document. Considering one token and its part of speech tag, one at a time, it identifies its lemma and an affix. These values are than added as features on the Token annotation. Morpher is based on certain regular expression rules. These rules were originally implemented by Kevin Humphreys in GATE1 in a programming language called Flex. Morpher has a capability to interpret these rules with an extension of allowing users to add new rules or modify the existing ones based on their requirements. In order to allow these operations with as little effort as possible, we changed the way these rules are written. More information on how to write these rules is explained later in Section 17.8.1.
Two types of parameters, Init-time and run-time, are required to instantiate and execute the PR.
- rulesFile (Init-time) The rule file has several regular expression patterns. Each pattern has two parts, L.H.S. and R.H.S. L.H.S. defines the regular expression and R.H.S. the function name to be called when the pattern matches with the word under consideration. Please see 17.8.1 for more information on rule file.
- caseSensitive (init-time) By default, all tokens under consideration are converted into lowercase to identify their lemma and affix. If the user selects caseSensitive to be true, words are no longer converted into lowercase.
- document (run-time) Here the document must be an instance of a GATE document.
- affixFeatureName (run-time) Name of the feature that should hold the affix value.
- rootFeatureName (run-time) Name of the feature that should hold the root value.
- annotationSetName (run-time) Name of the annotationSet that contains Tokens.
- considerPOSTag (run-time) Each rule in the rule file has a separate tag, which specifies which rule to consider with what part-of-speech tag. If this option is set to false, all rules are considered and matched with all words. This option is very useful. For example if the word under consideration is ”singing”. ”singing” can be used as a noun as well as a verb. In the case where it is identified as a verb, the lemma of the same would be ”sing” and the affix ”ing”, but otherwise there would not be any affix.
- failOnMissingInputAnnotations (run-time) If set to true (the default) the PR will terminate with an Exception if none of the required input Annotations are found in a document. If set to false the PR will not terminate and instead log a single warning message per session and a debug message per document that has no input annotations.
17.8.1 Rule File [#]
GATE provides a default rule file, called default.rul, which is available under the gate/plugins/Tools/morph/resources directory. The rule file has two sections.
- Variables
- Rules
Variables
The user can define various types of variables under the section defineVars. These variables can be used as part of the regular expressions in rules. There are three types of variables:
- Range With this type of variable, the user can specify the range of characters. e.g. A ==> [-a-z0-9]
- Set With this type of variable, user can also specify a set of characters, where one character at a time from this set is used as a value for the given variable. When this variable is used in any regular expression, all values are tried one by one to generate the string which is compared with the contents of the document. e.g. A ==> [abcdqurs09123]
- Strings Where in the two types explained above, variables can hold only one character from the given set or range at a time, this allows specifying strings as possibilities for the variable. e.g. A ==> ‘bb’ OR ‘cc’ OR ‘dd’
Rules
All rules are declared under the section defineRules. Every rule has two parts, LHS and RHS. The LHS specifies the regular expression and the RHS the function to be called when the LHS matches with the given word. ‘==>’ is used as delimiter between the LHS and RHS.
The LHS has the following syntax:
< ” * ”—”verb”—”noun” >< regularexpression >.
User can specify which rule to be considered when the word is identified as ‘verb’ or ‘noun’. ‘*’ indicates that the rule should be considered for all part-of-speech tags. If the part-of-speech should be used to decide if the rule should be considered or not can be enabled or disabled by setting the value of considerPOSTags option. Combination of any string along with any of the variables declared under the defineVars section and also the Kleene operators, ‘+’ and ‘*’, can be used to generate the regular expressions. Below we give few examples of L.H.S. expressions.
- <verb>”bias”
- <verb>”canvas”{ESEDING} ”ESEDING” is a variable defined under the defineVars section. Note: variables are enclosed with ”{” and ”}”.
- <noun>({A}*”metre”) ”A” is a variable followed by the Kleene operator ”*”, which means ”A” can occur zero or more times.
- <noun>({A}+”itis”) ”A” is a variable followed by the Kleene operator ”+”, which means ”A” can occur one or more times.
- < * >”aches” ”< * >” indicates that the rule should be considered for all part-of-speech tags.
On the RHS of the rule, the user has to specify one of the functions from those listed below. These rules are hard-coded in the Morph PR in GATE and are invoked if the regular expression on the LHS matches with any particular word.
- stem(n, string, affix) Here,
- n = number of characters to be truncated from the end of the string.
- string = the string that should be concatenated after the word to produce the root.
- affix = affix of the word
- irreg_stem(root, affix) Here,
- root = root of the word
- affix = affix of the word
- null_stem() This means words are themselves the base forms and should not be analyzed.
- semi_reg_stem(n,string) semir_reg_stem function is used with the regular expressions that end with any of the {EDING} or {ESEDING} variables defined under the variable section. If the regular expression matches with the given word, this function is invoked, which returns the value of variable (i.e. {EDING} or {ESEDING}) as an affix. To find a lemma of the word, it removes the n characters from the back of the word and adds the string at the end of the word.
17.9 MiniPar Parser [#]
MiniPar is a shallow parser. In its shipped version, it takes one sentence as an input and determines the dependency relationships between the words of a sentence. It parses the sentence and brings out the information such as:
- the lemma of the word;
- the part of speech of the word;
- the head modified by this word;
- name of the dependency relationship between this word and the head;
- the lemma of the head.
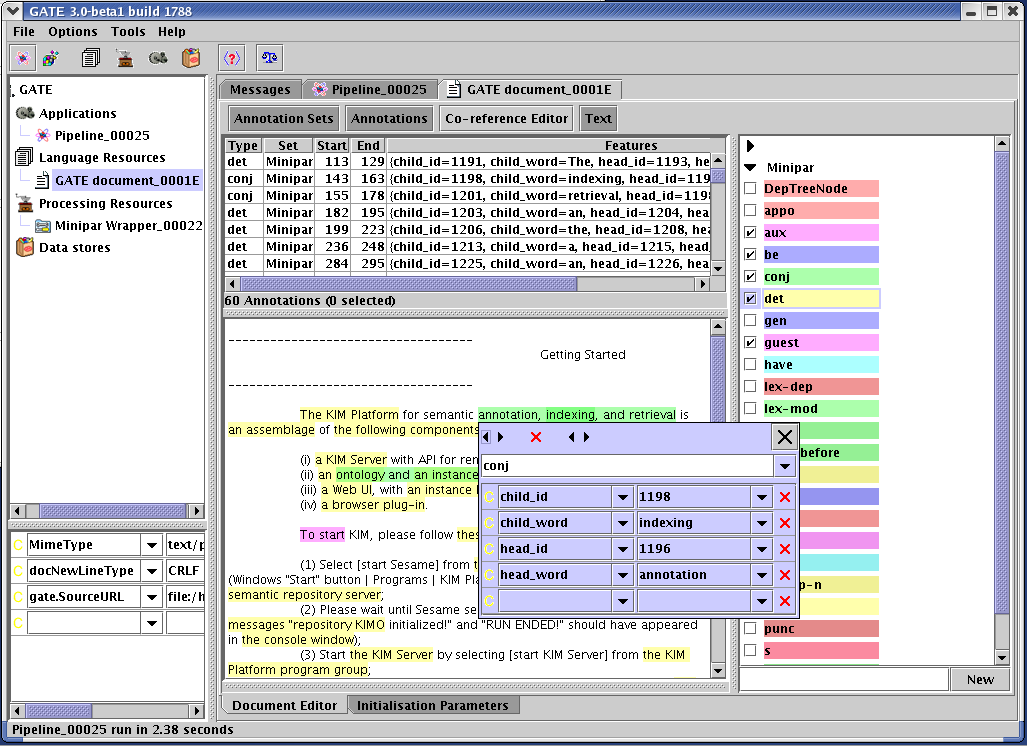
In the version of MiniPar integrated in GATE (‘Parser_Minipar’ plugin), it generates annotations of type ‘DepTreeNode’ and the annotations of type ‘[relation]’ that exists between the head and the child node. The document is required to have annotations of type ‘Sentence’, where each annotation consists of a string of the sentence.
Minipar takes one sentence at a time as an input and generates the tokens of type ‘DepTreeNode’. Later it assigns relation between these tokens. Each DepTreeNode consists of feature called ‘word’: this is the actual text of the word.
For each and every annotation of type ‘[Rel]’, where ‘Rel’ is obj, pred etc. This is the name of the dependency relationship between the child word and the head word (see Section 17.9.5). Every ‘[Rel]’ annotation is assigned four features:
- child_word: this is the text of the child annotation;
- child_id: IDs of the annotations which modify the current word (if any).
- head_word: this is the text of the head annotation;
- head_id: ID of the annotation modified by the child word (if any);
Figure 17.2 shows a MiniPar annotated document in GATE Developer.
17.9.1 Platform Supported
MiniPar in GATE is supported for the Linux and Windows operating systems. Trying to instantiate this PR on any other OS will generate the ResourceInstantiationException.
17.9.2 Resources
MiniPar in GATE is shipped with four basic resources:
- MiniparWrapper.jar: this is a JAVA Wrapper for MiniPar;
- creole.XML: this defines the required parameters for MiniPar Wrapper;
- minipar.linux: this is a modified version of pdemo.cpp.
- minipar-windows.exe : this is a modified version of pdemo.cpp compiled to work on windows.
17.9.3 Parameters
The MiniPar wrapper takes six parameters:
- annotationTypeName: new annotations are created with this type, default is ”DepTreeNode”;
- annotationInputSetName: annotations of Sentence type are provided as an input to MiniPar and are taken from the given annotationSet;
- annotationOutputSetName: All annotations created by Minipar Wrapper are stored under the given annotationOutputSet;
- document: the GATE document to process;
- miniparBinary: location of the MiniPar Binary file (i.e. either minipar.linux or minipar-windows.exe. These files are available under gate/plugins/minipar/ directory);
- miniparDataDir: location of the ‘data’ directory under the installation directory of MINIPAR. default is ”%MINIPAR_HOME%/data”.
17.9.4 Prerequisites
The MiniPar wrapper requires the MiniPar library to be available on the underlying Linux/Windows machine. It can be downloaded from the MiniPar homepage.
17.9.5 Grammatical Relationships [#]
aux "should <-aux-- resign"
be "is <-be-- sleeping"
c "that <-c-- John loves Mary"
comp1 first complement
det "the <-det ‘-- hat"
gen "Jane’s <-gen-- uncle"
i the relationship between a C clause and its I clause
inv-aux inverted auxiliary: "Will <-inv-aux-- you stop it?"
inv-be inverted be: "Is <-inv-be-- she sleeping"
inv-have inverted have: "Have <-inv-have-- you slept"
mod the relationship between a word and its adjunct modifier
pnmod post nominal modifier
p-spec specifier of prepositional phrases
pcomp-c clausal complement of prepositions
pcomp-n nominal complement of prepositions
post post determiner
pre pre determiner
pred predicate of a clause
rel relative clause
vrel passive verb modifier of nouns
wha, whn, whp: wh-elements at C-spec positions
obj object of verbs
obj2 second object of ditransitive verbs
subj subject of verbs
s surface subjec
17.10 RASP Parser [#]
RASP (Robust Accurate Statistical Parsing) is a robust parsing system for English, developed by the Natural Language and Computational Linguistics group at the University of Sussex.
This plugin, ‘Parser_RASP’, developed by DigitalPebble, provides four wrapper PRs that call the RASP modules as external programs, as well as a JAPE component that translates the output of the ANNIE POS Tagger (Section 6.6).
- RASP2 Tokenizer
- This PR requires Sentence annotations and creates Token annotations with a string feature. Note that sentence-splitting must be carried out before tokenization; the the RegEx Sentence Splitter (see Section 6.5) is suitable for this. (Alternatively, you can use the ANNIE Tokenizer (Section 6.2) and then the ANNIE Sentence Splitter (Section 6.4); their output is compatible with the other PRs in this plugin).
- RASP2 POS Tagger
- This requires Token annotations and creates WordForm annotations with pos, probability, and string features.
- RASP2 Morphological Analyser
- This requires WordForm annotations (from the POS Tagger) and adds lemma and suffix features.
- RASP2 Parser
- This requires the preceding annotation types and creates multiple Dependency annotations to represent a parse of each sentence.
- RASP POS Converter
- This PR requires Token annotations with a category feature as produced by the ANNIE POS Tagger (see Section 6.6 and creates WordForm annotations in the RASP Format. The ANNIE POS Tagger and this Converter can together be used as a substitute for the RASP2 POS Tagger.
Here are some examples of corpus pipelines that can be correctly constructed with these PRs.
- RegEx Sentence Splitter
- RASP2 Tokenizer
- RASP2 POS Tagger
- RASP2 Morphological Analyser
- RASP2 Parser
- RegEx Sentence Splitter
- RASP2 Tokenizer
- ANNIE POS Tagger
- RASP POS Converter
- RASP2 Morphological Analyser
- RASP2 Parser
- ANNIE Tokenizer
- ANNIE Sentence Splitter
- RASP2 POS Tagger
- RASP2 Morphological Analyser
- RASP2 Parser
- ANNIE Tokenizer
- ANNIE Sentence Splitter
- ANNIE POS Tagger
- RASP POS Converter
- RASP2 Morphological Analyser
- RASP2 Parser
Further documentation is included in the directory gate/plugins/Parser\_RASP/doc/.
The RASP package, which provides the external programs, is available from the RASP web page.
RASP is only supported for Linux operating systems. Trying to run it on any other operating systems will generate an exception with the message: ‘The RASP cannot be run on any other operating systems except Linux.’
It must be correctly installed on the same machine as GATE, and must be installed in a directory whose path does not contain any spaces (this is a requirement of the RASP scripts as well as the wrapper). Before trying to run scripts for the first time, edit rasp.sh and rasp_parse.sh to set the correct value for the shell variable RASP, which should be the file system pathname where you have installed the RASP tools (for example, RASP=/opt/RASP or RASP=/usr/local/RASP. You will need to enter the same path for the initialization parameter raspHome for the POS Tagger, Morphological Analyser, and Parser PRs.
(On some systems the arch command used in the scripts is not available; a work-around is to comment that line out and add arch=’ix86_linux’, for example.)
(The previous version of the RASP plugin can now be found in plugins/Obsolete/rasp.)
17.11 SUPPLE Parser [#]
SUPPLE is a bottom-up parser that constructs syntax trees and logical forms for English sentences. The parser is complete in the sense that every analysis licensed by the grammar is produced. In the current version only the ‘best’ parse is selected at the end of the parsing process. The English grammar is implemented as an attribute-value context free grammar which consists of subgrammars for noun phrases (NP), verb phrases (VP), prepositional phrases (PP), relative phrases (R) and sentences (S). The semantics associated with each grammar rule allow the parser to produce logical forms composed of unary predicates to denote entities and events (e.g., chase(e1), run(e2)) and binary predicates for properties (e.g. lsubj(e1,e2)). Constants (e.g., e1, e2) are used to represent entity and event identifiers. The GATE SUPPLE Wrapper stores syntactic information produced by the parser in the gate document in the form of parse annotations containing a bracketed representation of the parse; and semantics annotations that contains the logical forms produced by the parser. It also produces SyntaxTreeNode annotations that allow viewing of the parse tree for a sentence (see Section 17.11.4).
17.11.1 Requirements
The SUPPLE parser is written in Prolog, so you will need a Prolog interpreter to run the parser. A copy of PrologCafe (http://kaminari.scitec.kobe-u.ac.jp/PrologCafe/), a pure Java Prolog implementation, is provided in the distribution. This should work on any platform but it is not particularly fast. SUPPLE also supports the open-source SWI Prolog (http://www.swi-prolog.org) and the commercially licenced SICStus prolog (http://www.sics.se/sicstus, SUPPLE supports versions 3 and 4), which are available for Windows, Mac OS X, Linux and other Unix variants. For anything more than the simplest cases we recommend installing one of these instead of using PrologCafe.
17.11.2 Building SUPPLE
The SUPPLE plugin must be compiled before it can be used, so you will require a suitable Java SDK (GATE itself requires only the JRE to run). To build SUPPLE, first edit the file build.xml in the Parser_SUPPLE directory under plugins, and adjust the user-configurable options at the top of the file to match your environment. In particular, if you are using SWI or SICStus Prolog, you will need to change the swi.executable or sicstus.executable property to the correct name for your system. Once this is done, you can build the plugin by opening a command prompt or shell, going to the Parser_SUPPLE directory and running:
(on Windows, use ..\..\bin\ant). For PrologCafe or SICStus, replace swi with plcafe or sicstus as appropriate.
17.11.3 Running the Parser in GATE
In order to parse a document you will need to construct an application that has:
- tokeniser
- splitter
- POS-tagger
- Morphology
- SUPPLE Parser with parameters
mapping file (config/mapping.config)
feature table file (config/feature_table.config)
parser file (supple.plcafe or supple.sicstus or supple.swi)
prolog implementation (shef.nlp.supple.prolog.PrologCafe,
shef.nlp.supple.prolog.SICStusProlog3, shef.nlp.supple.prolog.SICStusProlog4,
shef.nlp.supple.prolog.SWIProlog or shef.nlp.supple.prolog.SWIJavaProlog1).You can take a look at build.xml to see examples of invocation for the different implementations.
Note that prior to GATE 3.1, the parser file parameter was of type java.io.File. From 3.1 it is of type java.net.URL. If you have a saved application (.gapp file) from before GATE 3.1 which includes SUPPLE it will need to be updated to work with the new version. Instructions on how to do this can be found in the README file in the SUPPLE plugin directory.
17.11.4 Viewing the Parse Tree [#]
GATE Developer provides a syntax tree viewer in the Tools plugin which can display the parse tree generated by SUPPLE for a sentence. To use the tree viewer, be sure that the Tools plugin is loaded, then open a document in GATE Developer that has been processed with SUPPLE and view its Sentence annotations. Right-click on the relevant Sentence annotation in the annotations table and select ‘Edit with syntax tree viewer’. This viewer can also be used with the constituency output of the Stanford Parser PR (Section 17.12).
17.11.5 System Properties [#]
The SICStusProlog (3 and 4) and SWIProlog implementations work by calling the native prolog executable, passing data back and forth in temporary files. The location of the prolog executable is specified by a system property:
- for SICStus: supple.sicstus.executable - default is to look for sicstus.exe (Windows) or sicstus (other platforms) on the PATH.
- for SWI: supple.swi.executable - default is to look for plcon.exe (Windows) or swipl (other platforms) on the PATH.
If your prolog is installed under a different name, you should specify the correct name in the relevant system property. For example, when installed from the source distribution, the Unix version of SWI prolog is typically installed as pl, most binary packages install it as swipl, though some use the name swi-prolog. You can also use the properties to specify the full path to prolog (e.g. /opt/swi-prolog/bin/pl) if it is not on your default PATH.
For details of how to pass system properties to GATE, see the end of Section 2.3.
17.11.6 Configuration Files [#]
Two files are used to pass information from GATE to the SUPPLE parser: the mapping file and
the feature table file.
Mapping File
The mapping file specifies how annotations produced using GATE are to be passed to the parser. The file is composed of a number of pairs of lines, the first line in a pair specifies a GATE annotation we want to pass to the parser. It includes the AnnotationSet (or default), the AnnotationType, and a number of features and values that depend on the AnnotationType. The second line of the pair specifies how to encode the GATE annotation in a SUPPLE syntactic category, this line also includes a number of features and values. As an example consider the mapping:
SUPPLE;category=dt;m_root=&S;s_form=&S
It specifies how a determinant (’DT’) will be translated into a category ‘dt’ for the parser. The construct ‘&S’ is used to represent a variable that will be instantiated to the appropriate value during the mapping process. More specifically a token like ‘The’ recognised as a DT by the POS-tagging will be mapped into the following category:
As another example consider the mapping:
SUPPLE;category=list_np;s_form=&S;ne_tag=person;ne_type=person_first;gender=female
It specified that an annotation of type ‘Lookup’ in GATE is mapped into a category ‘list_np’ with specific features and values. More specifically a token like ‘Mary’ identified in GATE as a Lookup will be mapped into the following SUPPLE category:
text:’_’,ne_tag:’person’,ne_type:’person_first’,gender:’female’).
Feature Table [#]
The feature table file specifies SUPPLE ‘lexical’ categories and its features. As an example an entry in this file is:
which specifies which features and in which order a noun category should be written. In this case:
17.11.7 Parser and Grammar [#]
The parser builds a semantic representation compositionally, and a ‘best parse’ algorithm is applied to each final chart, providing a partial parse if no complete sentence span can be constructed. The parser uses a feature valued grammar. Each Category entry has the form:
where the number and type of features is dependent on the category type (see Section 5.1). All categories will have the features s_form (surface form) and m_root (morphological root); nominal and verbal categories will also have person and number features; verbal categories will also have tense and vform features; and adjectival categories will have a degree feature. The list_np category has the same features as other nominal categories plus ne_tag and ne_type.
Syntactic rules are specified in Prolog with the predicate rule(LHS,RHS) where LHS is a syntactic category and RHS is a list of syntactic categories. A rule such as BNP_HEAD ⇒ N (‘a basic noun phrase head is composed of a noun’) is written as follows:
[n(m_root:R,number:N)]).
where the feature ‘sem’ is used to construct the semantics while the parser processes input, and E, R, and N are variables to be instantiated during parsing.
The full grammar of this distribution can be found in the prolog/grammar directory, the file load.pl specifies which grammars are used by the parser. The grammars are compiled when the system is built and the compiled version is used for parsing.
17.11.8 Mapping Named Entities
SUPPLE has a prolog grammar which deals with named entities, the only information required is the Lookup annotations produced by Gate, which are specified in the mapping file. However, you may want to pass named entities identified with your own Jape grammars in GATE. This can be done using a special syntactic category provided with this distribution. The category sem_cat is used as a bridge between Gate named entities and the SUPPLE grammar. An example of how to use it (provided in the mapping file) is:
SUPPLE;category=sem_cat;type=Date;text=&S;kind=date;name=&S
which maps a named entity ‘Date’ into a syntactic category ’sem_cat’. A grammar file called semantic_rules.pl is provided to map sem_cat into the appropriate syntactic category expected by the phrasal rules. The following rule for example:
sem_cat(s_form:F,text:TEXT,type:’Date’,kind:KIND,name:NAME)]).
is used to parse a ‘Date’ into a named entity in SUPPLE which in turn will be parsed into a noun phrase.
17.11.9 Upgrading from BuChart to SUPPLE
In theory upgrading from BuChart to SUPPLE should be relatively straightforward. Basically any instance of BuChart needs to be replaced by SUPPLE. Specific changes which must be made are:
- The compiled parser files are now supple.swi, supple.sicstus, or supple.plcafe
- The GATE wrapper parameter buchartFile is now SUPPLEFile, and it is now of type java.net.URL rather than java.io.File. Details of how to compensate for this in existing saved applications are given in the SUPPLE README file.
- The Prolog wrappers now start shef.nlp.supple.prolog instead of shef.nlp.buchart.prolog
- The mapping.conf file now has lines starting SUPPLE; instead of Buchart;
- Most importantly the main wrapper class is now called nlp.shef.supple.SUPPLE
Making these changes to existing code should be trivial and allow application to benefit from future improvements to SUPPLE.
17.12 Stanford Parser [#]
The Stanford Parser is a probabilistic parsing system implemented in Java by Stanford University’s Natural Language Processing Group. Data files are available from Stanford for parsing Arabic, Chinese, English, and German.
This plugin, ‘Parser_Stanford’, developed by the GATE team, provides a PR (gate.stanford.Parser) that acts as a wrapper around the Stanford Parser (version 1.6.1) and translates GATE annotations to and from the data structures of the parser itself. The plugin is supplied with the unmodified jar file and one English data file obtained from Stanford. Stanford’s software itself is subject to the full GPL.
The parser itself can be trained on other corpora and languages, as documented on the website, but this plugin does not provide a means of doing so. Trained data files are not compatible between different versions of the parser; in particular, note that you need version 1.6.1 data files for GATE builds numbered above 3120 (when we upgraded the plugin to Stanford version 1.6.1 on 22 January 2009) but version 1.6 files for earlier versions, including Release 5.0 beta 1.
Creating multiple instances of this PR in the same JVM with different trained data files does not work—the PRs can be instantiated, but runtime errors will almost certainly occur.
17.12.1 Input Requirements
Documents to be processed by the Parser PR must already have Sentence and Token annotations, such as those produced by either ANNIE Sentence Splitter (Sections 6.4 and 6.5) and the ANNIE English Tokeniser (Section 6.2).
If the reusePosTags parameter is true, then the Token annotations must have category features with compatible POS tags. The tags produced by the ANNIE POS Tagger are compatible with Stanford’s parser data files for English (which also use the Penn treebank tagset).
17.12.2 Initialization Parameters
- parserFile
- the path to the trained data file; the default value points to the English data file2 included with the GATE distribution. You can also use other files downloaded from the Stanford Parser website or produced by training the parser.
- mappingFile
- the optional path to a mapping file: a flat, two-column file which the wrapper can use to ‘translate’ tags. A sample file is included.3 By default this value is null and mapping is ignored.
- tlppClass
- an implementation of TreebankLangParserParams, used by the parser itself to extract the dependency relations from the constituency structures. The default value is compatible with the English data file supplied. Please refer to the Stanford NLP Group’s documentation and the parser’s javadoc for a further explanation.
17.12.3 Runtime Parameters
- annotationSetName
- the name of the annotationSet used for input (Token and Sentence annotations) and output (SyntaxTreeNode and Dependency annotations, and category and dependencies features added to Tokens).
- debug
- a boolean value which controls the verbosity of the wrapper’s output.
- reusePosTags
- if true, the wrapper will read category features (produced by an earlier POS-tagging PR) from the Token annotations and force the parser to use them.
- useMapping
- if this is true and a mapping file was loaded when the PR was initialized, the POS and syntactic tags produced by the parser will be translated using that file. If no mapping file was loaded, this parameter is ignored.
The following boolean parameters switch on and off the various types of output that the parser can produce. Any or all of them can be true, but if all are false the PR will simply print a warning to save time (instead of running the parser).
- addPosTags
- if this is true, the wrapper will add category features to the Token annotations.
- addConstituentAnnotations
- if true, the wrapper will mark the syntactic constituents with SyntaxTreeNode annotations that are compatible with the Syntax Tree Viewer (see Section 17.11.4).
- addDependencyAnnotations
- if true, the wrapper will add Dependency annotations to indicate the dependency relations in the sentence.
- addDependencyFeatures
- if true, the wrapper will add dependencies features to the Token annotations to indicate the dependency relations in the sentence.
The parser will derive the dependency structures only if either or both of the dependency output options is enabled, so if you do not need the dependency analysis, you can disable both of them and the PR will run faster.
Two sample GATE applications for English are included in the plugins/Parser_Stanford directory: sample_parser_en.gapp runs the Regex Sentence Splitter and ANNIE Tokenizer and then this PR to annotate constituency and dependency structures, whereas sample_pos+parser_en.gapp also runs the ANNIE POS Tagger and makes the parser re-use its POS tags.
17.13 OpenCalais, LingPipe and OpenNLP [#]
Further parsing and tagging functionality can be found in plugins described in Chapter 19: OpenCalais (Section 19.15), LingPipe (Section 19.16) and OpenNLP (Section 19.17).
1shef.nlp.supple.prolog.SICStusProlog exists for backwards compatibility and behaves the same as SICStusProlog3.
2resources/englishPCFG.ser.gz
3resources/english-tag-map.txt
