Chapter 3
How To… [#]
“The law of evolution is that the strongest survives!”
“Yes; and the strongest, in the existence of any social species, are those who are most social. In human terms, most ethical. …There is no strength to be gained from hurting one another. Only weakness.”
The Dispossessed [p.183], Ursula K. le Guin, 1974.
This chapter describes how to complete common tasks using GATE.
Read first the sections with an asterisk (*).
Sections that relate to the Development Environment are flagged [D]; those that relate to the framework are flagged [F]; sections relating to both are flagged [D,F].
There are two other primary sources for this type of information:
- for the development environment, see the visual tutorials available on our movies page;
- for the framework, see the example code at http://gate.ac.uk/gate-examples/doc/.
3.1 Download GATE* [#]
To download GATE point your web browser at http://gate.ac.uk/download/.
You should next read the section 3.2 to install and run GATE.
3.2 Install and Run GATE* [#]
GATE 3.1 will run anywhere that supports Java version 1.4.2 or later, including Solaris, Linux and Windoze platforms. GATE 4 and 5 require Java 5.0. We don’t run tests on other platforms, but have had reports of successful installs elsewhere. We are also testing released installers on MacOS X.
You should next read the section 3.6 to know about the GUI.
3.2.1 The Easy Way
The easy way to install is to use one of the platform-specific installers (created using the excellent IzPack). Download a ‘platform-specific installer’ and follow the instructions it gives you. Once the installation is complete, you can start GATE using gate.exe (Windows) or GATE.app (Mac) in the top-level installation directory, or gate.sh in the bin directory (other platforms).
3.2.2 The Hard Way (1)
Download the Java-only release package or the binary build snapshot, and follow the instructions below.
Prerequisites:
- A conforming Java 2 environment,
- version 1.4.2 or above for GATE 3.1
- version 5.0 for GATE 4.0 beta 1 or later.
available free from Sun Microsystems or from your UNIX supplier. (We test on various Sun JDKs on Solaris, Linux and Windows XP.)
- Binaries from the GATE distribution you downloaded: gate.jar, lib/ext/guk.jar
(Unicode editing support) and a suitable script to start Ant, e.g. ant.sh or ant.bat. These
are held in a directory called bin like this:
.../bin/
gate.jar
ant.sh
ant.batYou will also need the lib directory, containing various libraries that GATE depends on.
- An open mind and a sense of humour.
Using the binary distribution:
- Unpack the distribution, creating a directory containing jar files and scripts.
- To run the development environment: on Windows, start a Command Prompt window, change to the directory where you unpacked the GATE distribution and run ‘‘bin/ant.bat run’’; on UNIX run ‘‘bin/ant run’’.
- To embed GATE as a library, put gate.jar and all the libraries in the lib directory in your CLASSPATH and tell Java that guk.jar is an extension (-Djava.ext.dirs=path-to-guk.jar).
The Ant scripts that start GATE (ant.bat or ant) requires you to set the JAVA_HOME environment variable to point to the top level directory of your JAVA installation. The value of GATE_CONFIG is passed to the system by the scripts using either a -i command-line option, or the Java property gate.config.
3.2.3 The Hard Way (2): Subversion [#]
The GATE code is maintained in a Subversion repository. You can use a Subversion client to check
out the source code – the most up-to-date version of GATE is the trunk:
svn checkout https://gate.svn.sourceforge.net/svnroot/gate/gate/trunk gate
Once you have checked out the code you can build GATE using Ant (see section 3.8)
You can browse the complete Subversion repository online at http://gate.svn.sourceforge.net/gate.
3.3 [D,F] Use System Properties with GATE [#]
During initialisation, GATE reads several Java system properties in order to decide where to find its configuration files.
Here is a list of the properties used, their default values and their meanings:
- gate.home
- sets the location of the GATE install directory. This should point to the top level directory of your GATE installation. This is the only property that is required. If this is not set, the system will display an error message and them it will attempt to guess the correct value.
- gate.plugins.home
- points to the location of the directory containing installed GATE plug-ins (a.k.a. CREOLE directories). If this is not set then the default value of {gate.home}/plugins is used.
- gate.site.config
- points to the location of the configuration file containing the site-wide options. If not set this will default to {gate.home}/gate.xml. The site configuration file must exist!
- gate.user.config
- points to the file containing the user’s options. If not specified, or if the specified file does not exist at startup time, the default value of gate.xml (.gate.xml on Unix platforms) in the user’s home directory is used.
- gate.user.session
- points to the file containing the user’s saved session. If not specified, the default value of gate.session (.gate.session on Unix) in the user’s home directory is used. When starting up the GUI the session is reloaded from this file if it exists, and when exiting the GUI the session is saved to this file (unless the user has disabled “save session on exit” in the configuration dialog). The session is not used when using GATE as a library.
- load.plugin.path
- is a path-like structure, i.e. a list of URLs separated by ‘;’. All directories listed here will be loaded as CREOLE plugins during initialisation. This has similar functionality with the the -d command line option.
- gate.builtin.creole.dir
- is a URL pointing to the location of GATE’s built-in CREOLE directory. This is the location of the creole.xml file that defines the fundamental GATE resource types, such as documents, document format handlers, controllers and the basic visual resources that make up the GATE GUI. The default points to a location inside gate.jar and should not generally need to be overridden.
When using GATE as a library, you can set the values for these properties before you call Gate.init(). Alternatively, you can set the values programmatically using the static methods setGateHome(), setPluginsHome(), setSiteConfigFile(), etc. before calling Gate.init(). See the Javadoc documentation for details. If you want to set these values from the command line you can use the following syntax for setting gate.home for example:
java -Dgate.home=/my/new/gate/home/directory -cp... gate.Main
When running the GUI, you can set the properties by creating a file build.properties in the top level GATE directory. In this file, any system properties which are prefixed with “run.” will be passed to GATE. For example, to set an alternative user config file, put the following line in build.properties1:
run.gate.user.config=${user.home}/alternative-gate.xml
This facility is not limited to the GATE-specific properties listed above, for example the following line changes the default temporary directory for GATE (note the use of forward slashes, even on Windows platforms):
run.java.io.tmpdir=d:/bigtmp
3.4 [D,F] Use (CREOLE) Plug-ins [#]
The definitions of CREOLE resources (see Chapter 4) are stored in CREOLE directories (directories containing an XML file describing the resources, the Java archive with the compiled executable code and whatever libraries are required by the resources).
Starting with version 3, CREOLE directories are called “CREOLE Plugins” or simply “Plugins”. In previous versions, the CREOLE resources distributed with GATE used be included in the monolithic gate.jar archive. Version 3 includes them as separate directories under the plugins directory of the distribution. This allows easy access to the linguistic resources used without the requirement to unpack the gate.jar file.
Plugins can have one or more of the following states in relation with GATE:
- known
- plugins are those plugins that the system knows about. These include all the plugins in the plugins directory of the GATE installation (the so–called installed plugins) as well all the plugins that were manually loaded from the user interface.
- loaded
- plugins are the plugins currently loaded in the system. All CREOLE resource types from the loaded plugins are available for use. All known plugins can easily be loaded and unloaded using the user interface.
- auto-loadable
- plugins are the list of plugins that the system loads automatically during initialisation.
The default location for installed plugins can be modified using the gate.plugins.home system property while the list of auto-loadable plugins can be set using the load.plugin.path property, see Section 3.3 above.
The CREOLE plugins can be managed through the graphical user interface which can be activated by selecting “Manage CREOLE plugins” from the “File” menu. This will bring up a window listing all the known plugins. For each plugin there are two check-boxes – one labelled “Load now”, which will load the plugin, and the other labelled “Load always” which will add the plugin to the list of auto-loadable plugins. A “Delete” button is also provided – which will remove the plugin from the list of known plugins. Note the the installed plugins will return to the list of known plugins next time when GATE is started. They can only be removed by physically removing (or moving) the actual directory on disk outside the GATE plugins directory.
When using GATE as a library the following API calls are relevant to working with plugins:
Class gate.Gate
- public static void addKnownPlugin(URL pluginURL)
- adds the plugin to the list of known plugins.
- public static void removeKnownPlugin(URL pluginURL)
- tells the system to “forget” about one previously known directory. If the specified directory was loaded, it will be unloaded as well - i.e. all the metadata relating to resources defined by this directory will be removed from memory.
- public static void addAutoloadPlugin(URL pluginUrl)
- adds a new directory to the list of plugins that are loaded automatically at start-up.
- public static void removeAutoloadPlugin(URL pluginURL)
- tells the system to remove a plugin URL from the list of plugins that are loaded automatically at system start-up. This will be reflected in the user’s configuration data file.
Class gate.CreoleRegister
- public void registerDirectories(URL directoryUrl)
- loads a new CREOLE directory. The new plugin is added to the list of known plugins if not already there.
- public void removeDirectory(URL directory)
- unloads a loaded CREOLE plugin.
3.5 Troubleshooting
On Windoze 95 and 98, you may need to increase the amount of environment space available for the gate.bat script. Right click on the script, hit the memory tab and increase the ‘initial environment’ value to maximum.
Note that the gate.bat script uses javaw.exe to run GATE which means that you will see no console for the java process. If you have problems starting GATE and you would like to be able to see the console to check for messages then you should edit the gate.bat script and replace javaw.exe with java.exe in the definition of the JAVA environment variable.
When our FTP server is overloaded you may get a blank download link in the email sent to you after you register. Please try again later.
3.6 [D] Get Started with the GUI* [#]
Probably the best way to learn how to use the GATE graphical development environment is to look at the demonstrations and tutorials movies. There is specific links to them in this chapter.
This section gives a short description of what is where in the main window of the system.
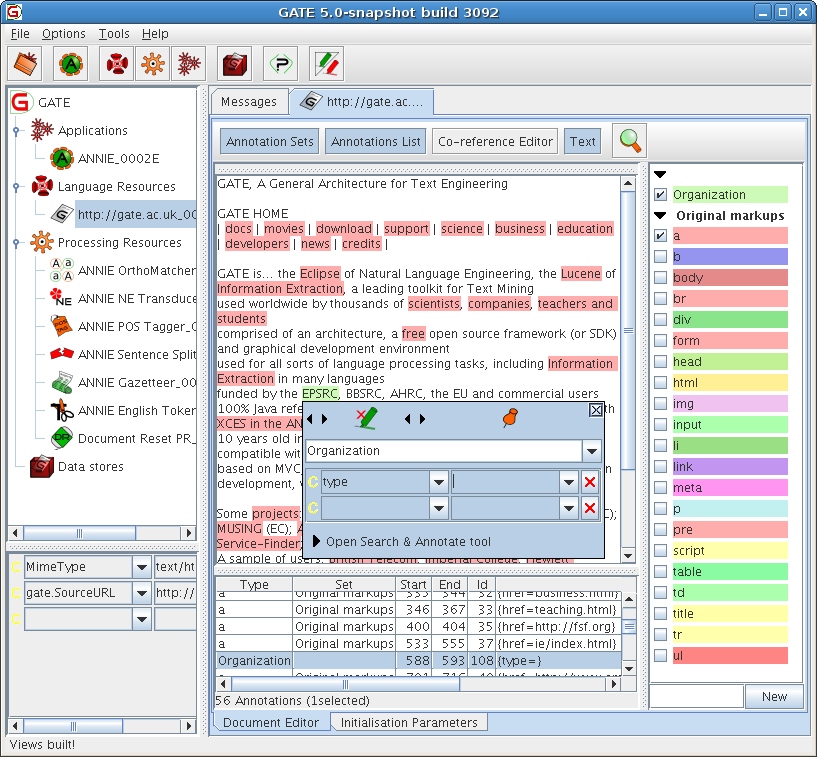
Figure 3.1 shows the main window of the application, with a single document loaded. There are five main areas of the window:
- the menus bar along the top, with ‘File’ etc.;
- in the top left of the main area, a tree starting from ‘GATE’ and containing ‘Applications’, ‘Language Resources’ etc. – this is the resources tree;
- in the bottom left of the main area, a rectangle, which is the small resource viewer;
- on the right of the main area, containing tabs with ‘Messages’ or the name of a resource from the resource tree, the main resource viewer;
- the messages bar along the bottom (where it says ‘Views built!’).
The menu and the messages bar do the usual things. Longer messages are displayed in the messages tab in the main resource viewer area.
The resource tree and resource viewer areas work together to allow the system to display diverse resources in various ways. Visual Resources integrated with GATE can have a small view or a large view. For example, data stores have a small view; documents have a large view.
All the resources, applications and datastores currently loaded in the system appear in the resources tree; double clicking on a resource will load a viewer for the resource in one of the resource view areas.
You should next read the section 3.12 to load creole resources.
3.7 [D,F] Configure GATE [#]
When the GATE development environment is started, or when Gate.init() is called from the API, GATE loads various sorts of configuration data stored as XML in files generally called something like gate.xml or .gate.xml. This data holds information such as:
- whether to save settings on exit;
- what fonts the GUI should use;
- where the local Oracle database lives.
All of this type of data is stored at two levels (in order from general to specific):
- the site-wide level, which by default is located the gate.xml file in top level directory of the GATE installation (i.e. the GATE home. This location can be overridden by the Java system property gate.site.config;
- the user level, which lives in the user’s HOME directory on UNIX or their profile directory on Windoze (note that parts of this file are overwritten by GATE when saving user settings). The default location for this file can be overridden by the Java system property gate.user.config.
Where configuration data appears on several different levels, the more specific ones overwrite the more general. This means that you can set defaults for all GATE users on your system, for example, and allow individual users to override those defaults without interfering with others.
Configuration data can be set from the GUI via the ‘Options’ menu, ‘Configuration’ choice. The user can change the appearance of the GUI (via the Appearance submenu), which includes the options of font and the “look and feel”. The “Advanced” submenu enables the user to include annotation features when saving the document and preserving its format, to save the selected Options automatically on exit, and to save the session automatically on exit. The Input Methods menu (available via the Options menu) enables the user to change the default language for input. These options are all stored in the user’s .gate.xml file.
When using GATE from the framework, you can also set the site config location using Gate.setSiteConfigFile(File) prior to calling Gate.init().
3.7.1 [F] Save Config Data to gate.xml
Arbitrary feature/value data items can be saved to the user’s gate.xml file via the following API calls:
To get the config data: Map configData = Gate.getUserConfig().
To add config data simply put pairs into the map: configData.put("my new config key", "value");.
To write the config data back to the XML file: Gate.writeUserConfig();.
Note that new config data will simply override old values, where the keys are the same. In this way defaults can be set up by putting their values in the main gate.xml file, or the site gate.xml file; they can then be overridden by the user’s gate.xml file.
3.8 Build GATE [#]
Note that you don’t need to build GATE unless you’re doing development on the system itself.
Prerequisites:
- A conforming Java environment as above.
- A copy of the GATE sources and the build scripts – either the SRC distribution package from the nightly snapshots or a copy of the code obtained through Subversion (see Section 3.2.3).
- An appreciation of natural beauty.
GATE now includes a copy of the ANT build tool which can be accessed through the scripts included in the bin directory (use ant.bat for Windows 98 or ME, ant.cmd for Windows NT, 2000 or XP, and ant.sh for Unix platforms).
To build gate, cd to gate and:
- Type:
bin/ant - [optional] To test the system:
bin/ant test
(Note that DB tests may fail unless you can connect to Sheffield’s Oracle server.) - [optional] To make the Javadoc documentation:
bin/ant doc
- You can also run GATE using Ant, by typing:
bin/ant run - To see a full list of options type: bin/ant help
(The details of the build process are all specified by the build.xml file in the gate directory.)
You can also use a development environment like Borland JBuilder (click on the gate.jpx file), but note that it’s still advisable to use ant to generate documentation, the jar file and so on. Also note that the run configurations have the location of a gate.xml site configuration file hard-coded into them, so you may need to change these for your site.
3.9 [D] Use GATE with Maven or JPF [#]
This section is based on contributions by Georg ttl and William Oberman.
To use GATE with Maven you need a definition of the dependencies in POM format. There’s an example POM here.
To use GATE with JPF (a Java plugin framework) you need a plugin definition like this one.
3.10 [D,F] Create a New (CREOLE) Resource [#]
CREOLE resources are Java Beans (see chapter 4). They come in three types: Language Resource, Processing Resource and Visual Resource (see chapter 1 section 1.3.1). To create a new resource you need to:
- write a Java class that implements GATE’s beans model;
- compile the class, and any others that it uses, into a Java Archive (JAR) file;
- write some XML configuration data for the new resource;
- tell GATE the URL of the new JAR and XML files.
The GATE development environment helps you with this process by creating a set of directories and files that implement a basic resource, including a Java code file and a Makefile. This process is called ‘bootstrapping’.
For example, let’s create a new component called GoldFish, which will be a Processing Resource that looks for all instances of the word ‘fish’ in a document and adds an annotation of type ‘GoldFish’.
First start the GATE development environment (see section 3.2). From the ‘Tools’
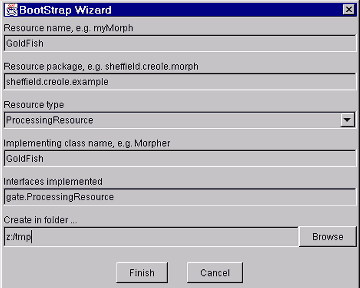
menu select ‘BootStrap Wizard’, which will pop up the dialogue in figure 3.2. The meaning of the data entry fields:
- The ‘resource name’ will be displayed when GATE loads the resource, and will be the name of the directory the resource lives in. For our example: GoldFish.
- ‘Resource package’ is the Java package that the class representing the resource will be created in. For our example: sheffield.creole.example.
- ‘Resource type’ must be one of Language, Processing or Visual Resource. In this case we’re going to process documents (and add annotations to them), so we select ProcessingResource.
- ‘Implementing class name’ is the name of the Java class that represents the resource. For our example: GoldFish.
- The ‘interfaces implemented’ field allows you to add other interfaces (e.g. gate.creole.ControllerAwarePR2) that you would like your new resource to implement. In this case we just leave the default (which is to implement the gate.ProcessingResource interface).
- The last field selects the directory that you want the new resource created in. For our example: z:/tmp.
Now we need to compile the class and package it into a JAR file. The bootstrap wizard creates an Ant build file that makes this very easy – so long as you have Ant set up properly, you can simply run
ant jar
|
This will compile the Java source code and package the resulting classes into GoldFish.jar. If you don’t have your own copy of Ant, you can use the one bundled with GATE - suppose your GATE is installed at /opt/gate-5.0-snapshot, then you can use /opt/gate-5.0-snapshot/bin/ant jar to build.
You can now load this resource into GATE; see
- section 3.11 for how to instantiate the resource from the framework;
- section 3.12 for how to load the resource in the development environment;
- section 3.13 for how to configure and further develop your resource (which will, by default, do nothing!).
The default Java code that was created for our GoldFish resource looks like this:
/*
* GoldFish.java * * You should probably put a copyright notice here. Why not use the * GNU licence? (See http://www.gnu.org/.) * * hamish, 26/9/2001 * * $Id: howto.tex,v 1.130 2006/10/23 12:56:37 ian Exp $ */ package sheffield.creole.example; import java.util.*; import gate.*; import gate.creole.*; import gate.util.*; /** * This class is the implementation of the resource GOLDFISH. */ @CreoleResource(name = "GoldFish", comment = "Add a descriptive comment about this resource") public class GoldFish extends AbstractProcessingResource implements ProcessingResource { } // class GoldFish |
The default XML configuration for GoldFish looks like this:
<!-- creole.xml GoldFish -->
<!-- hamish, 26/9/2001 --> <!-- $Id: howto.tex,v 1.130 2006/10/23 12:56:37 ian Exp $ --> <CREOLE-DIRECTORY> <JAR SCAN="true">GoldFish.jar</JAR> </CREOLE-DIRECTORY> |
The directory structure containing these files
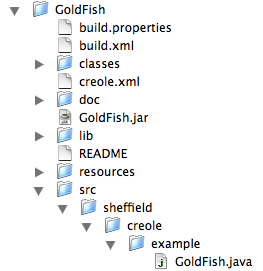
is shown in figure 3.3. GoldFish.java lives in the src/sheffield/creole/example directory. creole.xml and build.xml are in the top GoldFish directory. The lib directory is for libraries; the classes directory is where Java class files are placed; the doc directory is for documentation. These last two, plus GoldFish.jar are created by Ant.
This process has the advantage that it creates a complete source tree and build structure for the component, and the disadvantage that it creates a complete source tree and build structure for the component. If you already have a source tree, you will need to chop out the bits you need from the new tree (in this case GoldFish.java and creole.xml) and copy it into your existing one.
See the example code at http://gate.ac.uk/gate-examples/doc/.
3.11 [F] Instantiate (CREOLE) Resources [#]
This section describes how to create CREOLE resources as objects in a running Java virtual machine. This process involves using GATE’s Factory class, and, in the case of LRs, may also involve using a DataStore.
CREOLE resources are Java Beans; creation of a resource object involves using a default constructor, then setting parameters on the bean, then calling an init() method3. The Factory takes care of all this, makes sure that the GUI is told about what is happening (when GUI components exist at runtime), and also takes care of restoring LRs from DataStores. So a programmer using GATE should never call the constructor of a resource: always use the Factory.
The valid parameters for a resource are described in the resource’s section of its creole.xml file or in Java annotations on the resource class – see section 4.9.
Creating a resource via the Factory involves passing values for any create-time parameters that require setting to the Factory’s createResource method. If no parameters are passed, the defaults are used. So, for example, the following code creates a default ANNIE part-of-speech tagger:
Gate.getCreoleRegister().registerDirectories(new File(
Gate.getPluginsHome(), ANNIEConstants.PLUGIN_DIR).toURI().toURL()); FeatureMap params = Factory.newFeatureMap(); // empty map: default parameters ProcessingResource tagger = (ProcessingResource) Factory.createResource("gate.creole.POSTagger", params); |
Note that if the resource created here had any parameters that were both mandatory and had no default value, the createResource call would throw an exception. In this case, all the information needed to create a tagger is available in default values given in the tagger’s XML definition (in plugins/ANNIE/creole.xml):
<RESOURCE>
<NAME>ANNIE POS Tagger</NAME> <COMMENT>Mark Hepple’s Brill-style POS tagger</COMMENT> <CLASS>gate.creole.POSTagger</CLASS> <PARAMETER NAME="document" COMMENT="The document to be processed" RUNTIME="true">gate.Document</PARAMETER> .... <PARAMETER NAME="rulesURL" DEFAULT="resources/heptag/ruleset" COMMENT="The URL for the ruleset file" OPTIONAL="true">java.net.URL</PARAMETER> </RESOURCE> |
Here the two parameters shown are either ‘runtime’ parameters, which are set before a PR is executed, or have a default value (in this case the default rules file is distributed with GATE itself).
When creating a Document, however, the URL of the source for the document must be provided4. For example:
URL u = new URL("http://gate.ac.uk/hamish/");
FeatureMap params = Factory.newFeatureMap(); params.put("sourceUrl", u); Document doc = (Document) Factory.createResource("gate.corpora.DocumentImpl", params); |
The document created here is transient: when you quit the JVM the document will no longer exist. If you want the document to be persistent, you need to store it in a DataStore. Assuming that you have a DataStore already open called myDataStore, this code will ask the data store to take over persistence of your document, and to synchronise the memory representation of the document with the disk storage:
Document persistentDoc = myDataStore.adopt(doc, mySecurity);
myDataStore.sync(persistentDoc); |
Security:
User access to the LRs is provided by a security mechanism of users and groups, similar to those
on an operating system. When users create/save LRs into Oracle, they specify reading and writing
access rights for users from their group and other users. For example, LRs created by one
user/group can be made read-only to others, so they can use the data, but not modify it. The
access modes are:
- others: read/none;
- group: modify/read/none;
- owner: modify/read.
If needed, ownership can be transferred from one user to another. Users, groups and LR permissions are administered in a special administration tool, by a privileged user. For more details see chapter 14.
When you want to restore a document (or other LR) from a data store, you make the same createResource call to the Factory as for the creation of a transient resource, but this time you tell it the data store the resource came from, and the ID of the resource in that datastore:
URL u = ....; // URL of a serial data store directory
SerialDataStore sds = new SerialDataStore(u.toString()); sds.open(); // getLrIds returns a list of LR Ids, so we get the first one Object lrId = sds.getLrIds("gate.corpora.DocumentImpl").get(0); // we need to tell the factory about the LR’s ID in the data // store, and about which data store it is in - we do this // via a feature map: FeatureMap features = Factory.newFeatureMap(); features.put(DataStore.LR_ID_FEATURE_NAME, lrId); features.put(DataStore.DATASTORE_FEATURE_NAME, sds); // read the document back Document doc = (Document) Factory.createResource("gate.corpora.DocumentImpl", features); |
See the example code at http://gate.ac.uk/gate-examples/doc/.
3.12 [D] Load Resources: document, tokenizer...* [#]
3.12.1 Loading Language Resources: document, corpora... [#]
Load a language resource by right clicking on “Language Resources” in the resource tree and selecting a language resource type (document, corpus or annotation schema) or by going to the ’File’ menu and choosing ’New Language Resource’. Choose optionally a name for the resource, and choose any parameters as necessary.
For a document, a file or URL should be entered as the value of “sourceUrl” (double clicking in the “values” box brings up a tree structure to enable selection of documents). The easiest for a start is to enter an URL like ’http://gate.ac.uk’. Other parameters can be selected or changed as necessary, such as the encoding of the document, and whether it should be markup aware.
See also the movie for creating documents.
There are three ways of adding documents to a corpus:
- When creating the corpus, clicking on the icon under Value brings up a popup window with a list of the documents already loaded into GATE. This enables the user to add any documents to the corpus.
- Alternatively, the corpus can be loaded first, and documents added later by double clicking on the corpus and using the + and - icons to add or remove documents to the corpus. Note that the documents must have been loaded into GATE before they can be added to the corpus.
- Once loaded, the corpus can be populated by right clicking on the corpus and selecting “Populate”. With this method, documents do not have to have been previously loaded into GATE, as they will be loaded during the population process. Select the directory containing the relevant files, choose the encoding, and check or uncheck the “recurse directories” box as appropriate. The initial value for the encoding is the platform default.
Additionally, right-clicking on a loaded document in the tree and selecting the “New corpus with this document” option creates a new transient corpus named Corpus for document name containing just this document. To add a new annotation schema, simply choose the name and the path or Url. For more information about schema, see 6.4.1.
See also the movie for creating and populating corpora.
You should next read the section 3.16 to view annotations.
3.12.2 Loading Processing Resources: tokenizer, gazetteer... [#]
This section describes how to load and run CREOLE resources not present in ANNIE. To load ANNIE, see Section 3.17. For technical descriptions of these resources, see Chapter 9. First ensure that the necessary plugins have been loaded (see Section 3.4). If the resource you require does not appear in the list of Processing Resources, then you probably do not have the necessary plugin loaded. Processing resources are loaded by selecting them from the set of Processing Resources (right click on Processing Resources or select “New Processing Resource” from the File menu), adding them to the application and selecting the necessary parameters (e.g. input and output Annotation Sets).
See also the movie for loading processing resources.
You should next read the section 3.14 to create and run an application.
3.12.3 Loading and Processing Large Corpora [#]
When trying to process a larger corpus (i.e. one that would not fit in memory at one time) the use of a datastore and persistent corpora is required.
Open or create a datastore (see section 3.22) and then create a corpus. Save the so far empty corpus to the datastore – this will convert it to a persistent corpus.
When populating or processing the persistent corpus, the documents contained will only be loaded one by one thus reducing the amount of memory required to only that necessary for loading the largest document in the collection.
3.13 [D,F] Configure (CREOLE) Resources [#]
For full details on how to supply configuration data for resources can be found in section 4.9.
- To collect PRs into an application and run them, see section 3.14.
- GATE’s internal creole.xml file (note that there are no JAR entries there, as the file is bundled with GATE itself).
3.14 [D] Create and Run an Application* [#]
Once all the resources have been loaded, an application can be created and run. Right click on “Applications” and select “New” and then either “Corpus Pipeline” or “Pipeline”. A pipeline application can only be run over a single document, while a corpus pipeline can be run over a whole corpus.
To build the pipeline, double click on it, and select the resources needed to run the application (you may not necessarily wish to use all those which have been loaded). Transfer the necessary components from the set of “loaded components” displayed on the left hand side of the main window to the set of “selected components” on the right, by selecting each component and clicking on the left and right arrows, or by double-clicking on each component. Ensure that the components selected are listed in the correct order for processing (starting from the top). If not, select a component and move it up or down the list using the up/down arrows at the left side of the pane. Ensure that any parameters necessary are set for each processing resource (by clicking on the resource from the list of selected resources and checking the relevant parameters from the pane below). For example, if you wish to use annotation sets other than the Default one, these must be defined for each processing resource. Note that if a corpus pipeline is used, the corpus needs only to be set once, using the drop-down menu beside the “corpus” box. If a pipeline is used, the document must be selected for each processing resource used. Finally, right-click on “Run” to run the application on the document or corpus.
See also the movie for loading and running processing resources.
For how to use the conditional versions of the pipelines see section 3.15 and for saving/restoring the configuration of an application see section 3.23.
You should next read the section 3.17 to do information extraction.
3.15 [D] Run PRs Conditionally on Document Features [#]
The “Conditional Pipeline” and “Conditional Corpus Pipeline” application types are conditional versions of the pipelines mentioned in section 3.14 and allow processing resources to be run or not according to the value of a feature on the document. In terms of graphical interface, the only addition brought by the conditional versions of the applications is a box situated underneath the lists of available and selected resources which allows the user to choose whether the currently selected processing resource will run always, never or only on the documents that have a particular value for a named feature.
If the Yes option is selected then the corresponding resource will be run on all the documents processed by the application as in the case of non- conditional applications. If the No option is selected then the corresponding resource will never be run; the application will simply ignore its presence. This option can be used to temporarily and quickly disable an application component, for debugging purposes for example.
The If value of feature option permits running specific application components conditionally on document features. When selected, this option enables two text input fields that are used to enter the name of a feature and the value of that feature for which the corresponding processing resource will be run. When a conditional application is run over a document, for each component that has an associated condition, the value of the named feature is checked on the document and the component will only be used if the value entered by the user matches the one contained in the document features.
3.16 [D] View Annotations* [#]
If you have no document already loaded in the resource tree, see first section 3.12.
To view a document, double click on the filename in the resource tree (left hand pane). Note that it may take a few seconds for the text to be displayed if it is a big document and/or with a lot of annotations.
To view the annotation sets, click on the ’Annotation Sets’ button at the top of the document view or use F3 key. If you keep Shift key pressed when doing so the annotations will be selected as the last document viewed otherwise no annotation will be selected. This will bring up the annotation sets viewer, which displays the annotation sets available and their corresponding annotation types. Note that the default annotation set has no name. If no application has been run, the only annotations to be displayed will be those corresponding to the document format analysis performed automatically by GATE on loading the document (e.g. HTML or XML tags). If an application has been run, other annotation types and/or annotation sets may also be present. The fonts and colours of the annotations can be edited by double clicking on the annotation name or pressing Enter key.
Select the annotation types to be viewed by clicking on the appropriate checkbox(es) or pressing Space key. The text segments corresponding to these annotations will be highlighted in the main text window.
To view the annotations and their features, click on the ’Annotations list’ button at the top or bottom of the main window or use F4 key. The annotation list viewer will appear above or below the main text, respectively. It will only contain the annotations selected from the annotation sets. These lists can be sorted in ascending and descending order by any column, by clicking on the corresponding column heading. Moreover you can hide a column by using the context menu with right-click. Clicking on an entry in the table will also highlight the respective matching text portion.
Hovering over some part of the text in the main window will bring up a popup box containing a list of the annotations associated with it (assuming that the relevant annotation types have been selected from the annotation set viewer).
Annotations relating to coreference (if relevant) are displayed separately in the coreference viewer. This operates in the same way as the annotation sets viewer.
At any time, the main viewer can also be used to display other information, such as Messages, by clicking on the header at the top of the main window. If an error occurs in processing, the messages tab will flash red, and an additional popup error message may also occur.
Text in a loaded document can be edited in the document viewer. The usual platform specific cut, copy and paste keyboard shortcuts should also work, depending on your operating system (e.g. CTRL-C, CTRL-V for Windows). The last icon, a magnifying glass, at the top of the document editor is for searching in the document. To prevent the new annotation windows popping up when a piece of text is selected, hide the AnnotationSets view (the tree on the right) first to make it inactive. The highlighted portions of the text will still remain visible.
See also the movie for inspecting the processing results.
You should next read the section 3.19 to create and edit annotations.
3.17 [D] Do Information Extraction with ANNIE* [#]
This section describes how to load and run ANNIE (see Chapter 8) from the development environment. To embed ANNIE in other software, see section 3.28.
From the File menu, select “Load ANNIE system”. To run it in its default state, choose “With Defaults”. This will automatically load all the ANNIE resources, and create a corpus pipeline called ANNIE with the correct resources selected in the right order, and the default input and output annotation sets.
If “Without Defaults” is selected, the same processing resources will be loaded, but a popup window will appear for each resource, which enables the user to specify a name and location for the resource. This is exactly the same procedure as for loading a processing resource individually, the difference being that the system automatically selects those resources contained within ANNIE. When the resources have been loaded, a corpus pipeline called ANNIE will be created as before.
The next step is to add a corpus (see Section 3.12.1), and select this corpus from the drop-down Corpus menu in the Serial Application editor. Finally click on Run (from the Serial Application editor, or by right clicking on the application name and selecting “Run”). To view the results, double click on the filename in the left hand pane. No Annotation Sets nor Annotations will be shown until annotations are selected in the Annotation Sets; the Default set is indicated only with an unlabelled right-arrowhead which must be selected in order to make visible the available annotations.
See also the movie for loading and running ANNIE.
3.18 [D] Modify ANNIE [#]
You will find the ANNIE resources in gate/plugins/ANNIE/resources. Simply locate the existing resources you want to modify, make a copy with a new name, edit them, and load the new resources into GATE as new Processing Resources (see Section 3.12.2).
3.19 [D] Create and Edit Annotations* [#]
Since many NLP algorithms require annotated corpora for training, GATE’s development environment provides easy-to-use and extendable facilities for text annotation. The annotation can be done manually by the user or semi-automatically by running some processing resources over the corpus and then correcting/adding new annotations manually. Depending on the information that needs to be annotated, some ANNIE modules can be used or adapted to bootstrap the corpus annotation task.
To create annotations manually:
- Select the text you want to annotate and hover the mouse on the selection.
Then, to edit annotations:
- Hover the mouse on an annotation.
- The most recent annotation type to have been used will be displayed at the top in a drop down box that you can edit to create a new annotation type. If it is correct, you need to do nothing further. You can add or change features and their values in the table below.
- To delete an annotation, click on the red X icon at the top of the popup window.
- To change the span of the annotation, use the small arrow icon at the top of the popup window.
- You can move the popup window by dragging it and it will be set in pinned mode which means it won’t move when selecting another annotation. The pin icon at the top set the pinned mode too.
The popup menu only contains annotation types present in the Annotation Schema and those already listed in the relevant Annotation Set. To create a new Annotation Schema, see Section 3.21. The popup menu can be edited to add a new annotation type, however.
The new annotation created will automatically be placed in the annotation set that has been selected (highlighted) by the user. To create a new annotation set, type the name of the new set to be created in the box below the list of annotation sets, and click on ”New”.
Figure 3.4 demonstrates adding a ’Organization’ annotation for the string “EPSRC” (highlighted in green) to the default annotation set (blank name in the annotation set view on the right) and a feature name ’type’ with a value about to be added.
To add a second annotation to a selected piece of text, or to add an overlapping annotation to an existing one, press the CTRL key to avoid the existing annotation popup appearing, and then select the text and create the new annotation. Again by default the last annotation type to have been used will be displayed; change this to the new annotation type. When a piece of text has more than one annotation associated with it, on mouseover all the annotations will be displayed. Selecting one of them will bring up the relevant annotation popup.
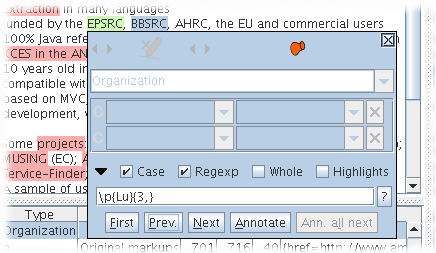
To search and annotate automatically the document use the search and annotate function like shown on figure 3.5:
- Create and/or select an annotation to be used as a model to annotate.
- Open the panel at the bottom of the annotation editor window.
- Change the expression to search if necessary.
- Use the [First] button or Enter key to select the first expression to annotate.
- Use the [Annotate] button if the selection is correct otherwise the [Next] button. After a few cycles of [Annotate] and [Next], Use the [Ann. all next] button and if you made an error use the [Undo] button.
Note that after using the [First] button you can move the caret in the document and use the [Next] button to avoid continuing the search from the beginning of the document. The [?] button at the end of the search text field will help you to build powerful regular expressions to search.
You should next read the section 3.20 to save annotations.
3.19.1 Schema-driven editing [#]
An alternative annotation editor component is available which constrains the available annotation types and features much more tightly, based on the annotation schemas that are currently loaded. This is particularly useful when annotating large quantities of data or for use by less skilled users.
Annotation schemas provide a means to define types of annotations in GATE - basically this means that GATE ”knows about” annotations defined in a schema.
The default annotation schema contains common named entities such as Person, Organisation, Location, etc. You can modify the existing schema or create a new one, in order to tell GATE about other kinds of annotations you frequently use. You can still create annotations in GATE without having specified them in an annotation schema, but you may then need to tell GATE about the properties of that annotation type each time you create an annotation for it.
To use this, you must load the Schema_Annotation_Editor plugin. With this plugin loaded, the annotation editor will only offer the annotation types permitted by the currently loaded set of schemas, and when you select an annotation type only the features permitted by the schema are available to edit5. Where a feature is declared as having an enumerated type the available enumeration values are presented as an array of buttons, making it easy to select the required value quickly.
To load an annotation schema use the resource tree and right-click on Language Resources or use the File menu then New language resource item.
See Section 3.21 for creating new annotation schemas.
3.20 [D] Saving annotations* [#]
The data can either be dumped out as a file (see Section 3.33) or saved in a data store (see Section 3.22).
3.21 [D,F] Create a New Annotation Schema [#]
GUI
An annotation schema file can be loaded or unloaded in GATE just like any other language resource. Once loaded into the system, the Schema Annotation Editor will use this definition when creating or editing annotations.
API
Another way to bring an annotation schema inside GATE is through creole.xml file. By using the AUTOINSTANCE element, one can create instances of resources defined in creole.xml. The gate.creole.AnnotationSchema (which is the Java representation of an annotation schema file) initializes with some predefined annotation definitions (annotation schemas) as specified by the GATE team.
Example from GATE’s internal creole.xml (in src/gate/resources/creole):
<!-- Annotation schema -->
<RESOURCE> <NAME>Annotation schema</NAME> <CLASS>gate.creole.AnnotationSchema</CLASS> <COMMENT>An annotation type and its features</COMMENT> <PARAMETER NAME="xmlFileUrl" COMMENT="The url to the definition file" SUFFIXES="xml;xsd">java.net.URL</PARAMETER> <AUTOINSTANCE> <PARAM NAME ="xmlFileUrl" VALUE="schema/AddressSchema.xml" /> </AUTOINSTANCE> <AUTOINSTANCE> <PARAM NAME ="xmlFileUrl" VALUE="schema/DateSchema.xml" /> </AUTOINSTANCE> <AUTOINSTANCE> <PARAM NAME ="xmlFileUrl" VALUE="schema/FacilitySchema.xml" /> </AUTOINSTANCE> <!-- etc. --> </RESOURCE> |
In order to create a gate.creole.AnnotationSchema object from a schema annotation file, one must use the gate.Factory class.
Eg:
FeatureMap params = new FeatureMap();
param.put("xmlFileUrl",annotSchemaFile.toURL());
AnnotationSchema annotSchema =
Factory.createResurce("gate.creole.AnnotationSchema", params);
Note: All the elements and their values must be written in lower case, as XML is defined as case sensitive and the parser used for XML Schema inside GATE searches is case sensitive.
In order to be able to write XML Schema definitions, the ones defined in GATE (resources/creole/schema) can be used as a model, or the user can have a look at http://www.w3.org/2000/10/XMLSchema for a proper description of the semantics of the elements used.
Some examples of annotation schemas are given in Section 6.4.1.
3.22 [D] Save and Restore LRs in Data Stores [#]
To save a text in a data store, a new data store must first be created if one does not already exist. Create a data store by right clicking on Data Store in the left hand pane, and select the option ”Create Data Store”. Select the data store type you wish to use. Create a directory to be used as the data store (note that the data store is a directory and not a file).
You can either save a whole corpus to the datastore (in which case the structure of the corpus will be preserved) or you can save individual documents. The recommended method is to save the whole corpus. To save a corpus, right click on the corpus name and select the ”Save to...” option (giving the name of the datastore created earlier). To save individual documents to the data store, right clicking on each document name and follow the same procedure.
To load a document from a data store, do not try to load it as a language resource. Instead, open the data store by right clicking on Data Store in the left hand pane, select “Open Data Store” and choose the data store to open. The data store tree will appear in the main window. Double click on a corpus or document in this tree to open it. To save a corpus and document back to the same datastore, simply select the ”Save” option.
See also the movie for creating a data store and the movie for loading corpus and documents from a data store.
3.23 [D] Save Resource Parameter State to File [#]
Resources, and applications that are made up of them, are created based on the settings of their parameters (see section 3.12). It is possible to save the data used to create an application to a file and re-load it later. To save the application to a file, right click on it in the resources tree and select “Save application state”, which will give you a file creation dialogue.
To restore the application later, select “Restore application from file” from the “File” menu.
Note that the data that is saved represents how to recreate an application – not the resources that make up the application itself. So, for example, if your application has a resource that initialises itself from some file (e.g. a grammar, a document) then that file must still exist when you restore the application.
In case you don’t want to save the corpus configuration associated with the application then you must select ’<none>’ in the corpus list of the application before to save the application.
The file resulted from saving the application state contains the values of the initialisation parameters for all the processing resources contained by the stored application. For the parameters of type URL (which are typically used to select external resources such as grammars or rules files) a transformation is applied so that all the paths are relative to the location of the file used to store the state. This means that the resource files used by an application do not need to be in the same location as when the application was initially created but rather in the same location relative to the location of the application file. This allows the creation and deployment of portable applications by keeping the application file and the resource files used by the application together.
If you want to save your application along with all the resources it requires you can use the “Export for Teamware” option (see section 3.24).
See also the movie for saving and restoring applications.
3.24 [D] Save an application with its resources (e.g. GATE Teamware) [#]
When you save an application using the “Save application state” option (see section 3.23), the saved file contains references to the plugins that were loaded when the application was saved, and to any resource files required by the application. To be able to reload the file, these plugins and other dependencies must exist at the same locations (relative to the saved state file). While this is fine for saving and loading applications on a single machine it means that if you want to package your application to run it elsewhere (e.g. deploy it to a GATE Teamware installation) then you need to be careful to include all the resource files and plugins at the right locations in your package. The “Export for Teamware” option on the right-click menu for an application helps to automate this process.
When you export an application in this way, GATE produces a ZIP file containing the saved application state (in the same format as “Save application state”). Any plugins and resource files that the application refers to are also included in the zip file, and the relative paths in the saved state are rewritten to point to the correct locations within the package. The resulting package is therefore self-contained and can be copied to another machine and unpacked there, or passed to your Teamware Administrator for deployment.
As well as selecting the location where you want to save the package, the “Export for Teamware” option will also prompt you to select the annotation sets that your application uses for input and output. For example, if your application makes use of the unpacked XML markup in source documents and creates annotations in the default set then you would select “Original markups” as an input set and the “<Default annotation set>” as an output set. GATE will try to make an educated guess at the correct sets but you should check and amend the lists as necessary.
There are a few important points to note about the export process:
- The complete contents of all the plugin directories that are loaded when you perform the export will be included in the resulting package. Use the plugin manager to unload any plugins your application is not using before you export it.
- If your application refers to a resource file in a directory that is not under one of the loaded plugins, the entire contents of this directory will be recursively included in the package. If you have a number of unrelated resources in a single directory (e.g. many sets of large gazetteer lists) you may want to separate them into separate directories so that only the relevant ones are included in the package.
- The packager only knows about resources that your application refers to directly in its parameters. For example, if your application includes a multi-phase JAPE grammar the packager will only consider the main grammar file, not any of its sub-phases. If the sub-phases are not contained in the same directory as the main grammar you may find they are not included. If indirect references of this kind are all to files under the same directory as the “master” file it will work OK.
If you require more flexibility than this option provides you should read section C.2, which describes the underlying Ant task that the exporter uses.
3.25 [D,F] Perform Evaluation with the AnnotationDiff tool [#]
Section 13 describes the theory behind this tool.
The annotation tool is activated by selecting it from the Tools menu at the top of the window. It will appear in a new window. Select the key and response documents to be used (note that both must have been previously loaded into the system), the annotation sets to be used for each, and the annotation type to be evaluated.
Note that the tool automatically intersects all the annotation types from the selected key annotation set with all types from the response set.
On a separate note, you can perform a diff on the same document, between two different annotation sets. One annotation set could contain the key type and another could contain the response one.
After the type has been selected, the user is required to decide how the features will be compared. It is important to know that the tool compares them by analyzing if features from the key set are contained in the response set. It checks for both the feature name and feature value to be the same.
There are three basic options to select:
- To take all the features from the key set into consideration
- To take only the user selected ones
- To ignore all the features from the key set.
If false positives are to be measured, select the annotation type (and relevant annotation set) to be used as the denominator (normally, Token or Sentence). The weight for the F-Measure can also be changed - by default it is set to 0.5 (i.e. to give precision and recall equal weight). Finally, click on “Evaluate” to display the results. Note that the window may need to be resized manually, by dragging the window edges or internal bars as appropriate).
In the main window, the key and response annotations will be displayed. They can be sorted by any category by clicking on the relevant column header. The key and response annotations will be aligned if their indices are identical, and are color coded according to the legend displayed.
Precision, recall, F-measure and false positives are also displayed below the annotation tables, each according to 3 criteria - strict, lenient and average. See sections 13.1 and 13.4 for more details about the evaluation metrics.
The results can be saves to an HTML file by pressing the ”Export to HTML” button. This creates an HTML snapshot of what the AnnotationDiff interface shows at that moment.The columns and rows in the table will be shown in the same order, and the hidden columns will not appear in the HTML file. The colours will also be the same.
3.26 [D] Use the Corpus Benchmark Evaluation tool [#]
The Corpus Benchmark tool can be run in two ways: standalone and GUI mode. Section 13.3 describes the theory behind this tool.
3.26.1 GUI mode
To use the tool in GUI mode, first make sure the properties of the tool have been set correctly (see section 3.26.2 for how to do this). Then select “Corpus Benchmark Tool” from the Options menu. There are 3 ways in which it can be run:
- Default mode compares the stored processed set with the current processed set and the human-annotated set. This will give information about how well the system is doing compared with a previous version.
- Human marked against stored processing results compares the stored processed set with the human-annotated set.
- Human marked against current processing results compares the current processed set with the human-annotated set.
Once the mode has been selected, choose the directory where the corpus is to be found. The corpus must have a directory structure consisting of “clean” and “marked” subdirectories (note that these names are case sensitive). The clean directory should contain the raw texts; the marked directory should contain the human-annotated texts. Finally, select the application to be run on the corpus (for “default” and “human v current” modes).
If the tool is to be used in Default or Current mode, the corpus must first be processed with the current set of resources. This is done by selecting “Store corpus for future evaluation” from the Corpus Benchmark Tool. Select the corpus to be processed (from the top of the subdirectory structure, i.e. the directory containing the marked and stored subdirectories). If a “processed” subdirectory exists, the results will be placed there; if not, one will be created.
Once the corpus has been processed, the tool can be run in Default or Current mode. The resulting HTML file will be output in the main GATE messages window. This can then be pasted into a text editor and viewed in an Internet browser for easier viewing.
The tool can be used either in verbose or non-verbose mode, by selecting the verbose option from the menu. In verbose mode, any score below the user’s pre-defined threshold (stored in corpus_tool.properties file) will show the relevant annotations for that entity type, thereby enabling the user to see where problems are occurring.
3.26.2 How to define the properties of the benchmark tool [#]
The properties of the benchmark tool are defined in the file corpus_tool.properties, which should be located in the directory from which GATE is run (usually gate/build or gate/bin).
The following properties should be set:
- the threshold for the verbose mode (by default this is set to 0.5);
- the name of the annotation set containing the human-marked annotations (annotSetName);
- the name of the annotation set containing the system-generated annotations (outputSetName);
- the annotation types to be considered (annotTypes);
- the feature values to be considered, if any (annotFeatures).
The default Annotation Set has to be represented by an empty String. Note also that outputSetName and annotSetName must be different. If they are the same, then use the Annotation Set Transfer PR to change one of them.
An example file is shown below:
threshold=0.7
annotSetName=Key outputSetName=ANNIE annotTypes=Person;Organization;Location;Date;Address;Money annotFeatures=type;gender |
3.27 [D] Write JAPE Grammars [#]
JAPE is a language for writing regular expressions over annotations, and for using patterns matched in this way as the basis for creating more annotations. JAPE rules compile into finite state machines. GATE’s built-in Information Extraction tools use JAPE (amongst other things). For information on JAPE see:
- chapter 7 describes how to write JAPE rules;
- chapter 8 describes the built-in IE components;
- appendix B describes how JAPE is implemented and formally defines the language’s grammar;
- appendix D describes the default Named Entity rules distributed with GATE.
3.28 [F] Embed NLE in other Applications [#]
Embedding GATE-based language processing in other applications is straightforward:
- add gate.jar and the JAR files in gate/lib to the CLASSPATH,
- tell Java that the GATE Unicode Kit is an extension (-Djava.ext.dirs=/home/hamish/gate/bin/ext, for example);
- initialise GATE with gate.Gate.init();
- program to the framework API.
For example, this code will create the ANNIE extraction system:
// initialise the GATE library
Gate.init(); // load ANNIE as an application from a gapp file SerialAnalyserController controller = (SerialAnalyserController) PersistenceManager.loadObjectFromFile(new File(new File( Gate.getPluginsHome(), ANNIEConstants.PLUGIN_DIR), ANNIEConstants.DEFAULT_FILE)); |
If you want to use resources from any plugins, you need to load the plugins before calling createResource:
Gate.init();
// need Tools plugin for the Morphological analyser Gate.getCreoleRegister().registerDirectories( new File(Gate.getPluginsHome(), "Tools").toURL() ); ... ProcessingResource morpher = (ProcessingResource) Factory.createResource("gate.creole.morph.Morph"); |
Instead of creating your processing resources individually using the Factory, you can create your application in the GUI, save it using the “save application state” option (see section 3.23), and then load the saved state from your code. This will automatically reload any plugins that were loaded when the state was saved, you do not need to load them manually.
Gate.init();
CorpusController controller = (CorpusController) PersistenceManager.loadObjectFromFile(new File("savedState.xgapp")); // loadObjectFromUrl is also available |
There are longer examples available at http://gate.ac.uk/gate-examples/doc/.
3.29 [F] Use GATE within a Spring application [#]
GATE provides helper classes to allow GATE resources to be created and managed by the Spring framework. For Spring 2.0 or later, GATE provides a custom namespace handler that makes them extremely easy to use. To use this namespace, put the following declarations in your bean definition file:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:gate="http://gate.ac.uk/ns/spring" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://gate.ac.uk/ns/spring http://gate.ac.uk/ns/spring.xsd"> |
You can have Spring initialise GATE:
<gate:init gate-home="WEB-INF" user-config-file="WEB-INF/user.xml">
<gate:preload-plugins> <value>WEB-INF/ANNIE</value> <value>http://example.org/gate-plugin</value> </gate:preload-plugins> </gate:init> |
To create a GATE resource, use the <gate:resource> element.
<gate:resource id="sharedOntology" scope="singleton"
resource-class="gate.creole.ontology.owlim.OWLIMOntologyLR"> <gate:parameters> <entry key="rdfXmlURL"> <value type="org.springframework.core.io.Resource" >WEB-INF/ontology.rdf</value> </entry> </gate:parameters> </gate:resource> |
If you are familiar with Spring you will see that <gate:parameters> uses the same format as the standard <map> element, but values whose type is a Spring Resource will be converted to URLs before being passed to the GATE resource.
You can load a GATE saved application with
<gate:saved-application location="WEB-INF/application.gapp" scope="prototype">
<gate:customisers> <gate:set-parameter pr-name="custom transducer" name="ontology" ref="sharedOntology" /> </gate:customisers> </gate:saved-application> |
”Customisers” are used to customise the application after it is loaded. In the example above, we load a singleton copy of an ontology which is then shared between all the separate instances of the (prototype) application. The <gate:set-parameter> customiser accepts all the same ways to provide a value as the standard Spring <property> element (a ”value” or ”ref” attribute, or a sub-element - <value>, <list>, <bean>, <gate:resource> …).
The <gate:add-pr> customiser provides support for the case where most of the application is in a saved state, but we want to create one or two extra PRs with Spring (maybe to inject other Spring beans as init parameters) and add them to the pipeline.
<gate:saved-application ...>
<gate:customisers> <gate:add-pr add-before="OrthoMatcher" ref="myPr" /> </gate:customisers> </gate:saved-application> |
By default, the <gate:add-pr> customiser adds the target PR at the end of the pipeline, but an add-before or add-after attribute can be used to specify the name of a PR before (or after) which this PR should be placed. Alternatively, an index attribute places the PR at a specific (0-based) index into the pipeline. The PR to add can be specified either as a ”ref” attribute, or with a nested <bean> or <gate:resource> element.
These custom elements all define various factory beans. For full details, see the JavaDocs for gate.util.spring (the factory beans) and gate.util.spring.xml (the gate: namespace handler).
Note: the former approach using factory methods of the gate.util.spring.SpringFactory class will still work, but should be considered deprecated in favour of the new factory beans.
3.30 [F] Use GATE within a Tomcat Web Application [#]
Embedding GATE in a Tomcat web application involves several steps.
- Put the necessary JAR files (gate.jar and all or most of the jars in gate/lib) in your webapp/WEB-INF/lib.
- Put the plugins that your application depends on in a suitable location (e.g. webapp/WEB-INF/plugins).
- Create suitable gate.xml configuration files for your environment.
- Set the appropriate paths in your application before calling Gate.init().
This process is detailed in the following sections.
3.30.1 Recommended Directory Structure
You will need to create a number of other files in your web application to allow GATE to work:
- Site and user gate.xml config files - we highly recommend defining these specifically for the web application, rather than relying on the default files on your application server.
- The plugins your application requires.
In this guide, we assume the following layout:
webapp/
WEB-INF/ gate.xml user-gate.xml plugins/ ANNIE/ etc. |
3.30.2 Configuration files
Your gate.xml (the “site-wide configuration file”) should be as simple as possible:
<?xml version="1.0" encoding="UTF-8" ?>
<GATE> <GATECONFIG Save_options_on_exit="false" Save_session_on_exit="false" /> </GATE> |
Similarly, keep the user-gate.xml (the “user config file”) simple:
<?xml version="1.0" encoding="UTF-8" ?>
<GATE> <GATECONFIG Known_plugin_path=";" Load_plugin_path=";" /> </GATE> |
This way, you can control exactly which plugins are loaded in your webapp code.
3.30.3 Initialization code
Given the directory structure shown above, you can initialize GATE in your web application like this:
// imports
... public class MyServlet extends HttpServlet { private static boolean gateInited = false; public void init() throws ServletException { if(!gateInited) { try { ServletContext ctx = getServletContext(); // use /path/to/your/webapp/WEB-INF as gate.home File gateHome = new File(ctx.getRealPath("/WEB-INF")); Gate.setGateHome(gateHome); // thus webapp/WEB-INF/plugins is the plugins directory, and // webapp/WEB-INF/gate.xml is the site config file. // Use webapp/WEB-INF/user-gate.xml as the user config file, to avoid // confusion with your own user config. Gate.setUserConfigFile(new File(gateHome, "user-gate.xml")); Gate.init(); // load plugins, for example... Gate.getCreoleRegister().registerDirectories( ctx.getResource("/WEB-INF/plugins/ANNIE")); gateInited = true; } catch(Exception ex) { throw new ServletException("Exception initialising GATE", ex); } } } } |
Once initialized, you can create GATE resources using the Factory in the usual way (for example, see section 3.28 for an example of how to create an ANNIE application). You should also read section 3.31 for important notes on using GATE in a multithreaded application.
Instead of an initialization servlet you could also consider doing your initialization in a ServletContextListener, or using Spring (see section 3.29).
3.31 [F] Use GATE in a Multithreaded Environment [#]
GATE can be used in multithreaded applications, so long as you observe a few restrictions. First, you must initialise GATE by calling Gate.init() exactly once in your application, typically in the application startup phase before any concurrent processing threads are started.
Secondly, you must not make calls that affect the global state of GATE (e.g. loading or unloading plugins) in more than one thread at a time. Again, you would typically load all the plugins your application requires at initialisation time. It is safe to create instances of resources in multiple threads concurrently.
Thirdly, it is important to note that individual GATE processing resources, language resources and controllers are by design not thread safe – it is not possible to use a single instance of a controller/PR/LR in multiple threads at the same time – but for a well written resource it should be possible to use several different instances of the same resource at once, each in a different thread. When writing your own resource classes you should bear the following in mind, to ensure that your resource will be useable in this way.
- Avoid static data. Where possible, you should avoid using static fields in your class, and you should try and take all configuration data via the CREOLE parameters you declare in your creole.xml file. System properties may be appropriate for truly static configuration, such as the location of an external executable, but even then it is generally better to stick to CREOLE parameters – a user may wish to use two different instances of your PR, each talking to a different executable.
- Read parameters at the correct time. Init-time parameters should be read in the init() (and reInit()) method, and for processing resources runtime parameters should be read at each execute().
- Use temporary files correctly. If your resource makes use of external temporary files you should create them using File.createTempFile() at init or execute time, as appropriate. Do not use hardcoded file names for temporary files.
- If there are objects that can be shared between different instances of your resource, make sure these objects are accessed either read-only, or in a thread-safe way. In particular you must be very careful if your resource can take other resource instances as init or runtime parameters (e.g. the Flexible Gazetteer, section 9.5).
Of course, if you are writing a PR that is simply a wrapper around an external library that imposes these kinds of limitations there is only so much you can do. If your resource cannot be made safe you should document this fact clearly.
All the standard ANNIE PRs are safe when independent instances are used in different threads concurrently, as are the standard transient document, transient corpus and controller classes. A typical pattern of development for a multithreaded GATE-based application is:
- Develop your GATE processing pipeline in the GATE GUI.
- Save your pipeline as a .gapp file.
- In your application’s initialisation phase, load n copies of the pipeline using PersistenceManager.loadObjectFromFile() (see the Javadoc documentation for details) and either give one to each thread or store them in a pool (e.g. a LinkedList).
- When you need to process a text, get one copy of the pipeline from the pool, and return it to the pool when you have finished processing.
3.32 [D,F] Add support for a new document format [#]
In order to add a new document format, one needs to extend the gate.DocumentFormat class and to implement an abstract method called:
public void unpackMarkup(Document doc) throws
DocumentFormatException
This method is supposed to implement the functionality of each format reader and to create annotation on the document. Finally the document’s old content will be replaced with a new one containing only the text between markups (see the GATE API documentation for more details on this method functionality).
If one needs to add a new textual reader will extend the gate.corpora. TextualDocumentFormat and override the unpackMarkup(doc) method.
This class needs to be implemented under the Java bean specifications because it will be instantiated by GATE using Factory.createResource() method.
The init() method that one needs to add and implement is very important because in here the reader defines its means to be selected successfully by GATE. What one need to do is to add some specific information into certain static maps defined in DocumentFormat class, that will be used at reader detection time.
After that, a definition of the reader will be placed into the one’s creole.xml file and the reader will be available to GATE.
We present for the rest of the section a complete three steps example of adding such a reader. The reader we describe in here is an XML reader.
Step 1
Create a new class called XmlDocumentFormat that extends
gate.corpora.TextualDocumentFormat.
Step 2
Implement the unpackMarkup(Document doc) which performs the required functionality for the reader. Add XML detection means in init() method:
public Resource init() throws ResourceInstantiationException{
// Register XML mime type MimeType mime = new MimeType("text","xml"); // Register the class handler for this mime type mimeString2ClassHandlerMap.put(mime.getType()+ "/" + mime.getSubtype(), this); // Register the mime type with mine string mimeString2mimeTypeMap.put(mime.getType() + "/" + mime.getSubtype(), mime); // Register file sufixes for this mime type suffixes2mimeTypeMap.put("xml",mime); suffixes2mimeTypeMap.put("xhtm",mime); suffixes2mimeTypeMap.put("xhtml",mime); // Register magic numbers for this mime type magic2mimeTypeMap.put("<?xml",mime); // Set the mimeType for this language resource setMimeType(mime); return this; }// init() |
More details about the information from those maps can be found in Section 6.5.1
Step 3
Add the following creole definition in the creole.xml document.
<RESOURCE>
<NAME>My XML Document Format</NAME> <CLASS>mypackage.XmlDocumentFormat</CLASS> <AUTOINSTANCE/> <PRIVATE/> </RESOURCE> |
More information on the operation of GATE’s document format analysers may be found in section 6.5.
3.33 [D] Dump Results to File [#]
There are three main ways to dump out the results of, for example, some language analysis or Information Extraction process running over documents:
- preserving the original document format, with optional added annotations;
- in GATE’s own XML serialisation format (including all the annotations on the document);
- by writing your own dump algorithm as a ProcessingResource.
This section describes how to use the first two options.
Both types of data export are available in the popup menu triggered by right-clicking on a document in the resources tree (see section 3.6): type 1 is called ‘save preserving format’ and type 2 is called ‘save as XML’.
Selecting the save as XML option leads to a file open dialogue; give the name of the file you want to create, and the whole document and all its data will be exported to that file. If you later create a document from that file, the state will be restored. (Note: because GATE’s annotation model is richer than that of XML, and because our XML dump implementation sometimes cuts corners6, the state may not be identical after restoration. If your intention is to store the state for later use, use a DataStore instead.)
The save preserving format option also leads to a file dialogue; give a name and the data you require will be dumped into the file. The difference is that the file will preserve the original format of the source document. You can add annotations to the dump file: if there is a document viewer open in the main resource viewer area (see section 3.6), then any annotations that are selected (i.e. are visible in the table at the bottom of the viewer) will be included in the output dump. This is the best way to use the system to add markup based on some analysis process: select those annotations in the document viewer, save preserving format and you will have a file identical to the original source document with just the annotations you selected added. By default, the added annotations will contain no feature data; if you want the process to also dump features, set the ‘Include annotation features...’ option in the advanced options dialogue (see section 3.7). Note that GATE’s model of annotation allows graph structures, which are difficult to represent in XML (XML is a tree-structured representation format). During the dump process, annotations that cross each other in ways that can’t be represented straightforwardly in XML will be discarded, and a warning message printed.
3.34 [D] Stop GUI ‘Freezing’ on Linux [#]
There is a problem with some versions of Linux that causes the GUI to appear to freeze. The problem occurs when you take some action, like loading a resource or browsing for a file, that pops up a dialogue box. This box sometimes fails to appear in a visible area of the screen, at which point the rest of the GUI waits for you to do something intelligent with the dialogue box, while you wait for the GUI to do something. This is an excellent feature for those without tight deadlines to meet, and the best solution is to stop work and go home for a long while. Alternatively, you can play ‘hunt the dialogue box’.
This feature is available totally free of charge.
3.35 [D] Stop GUI Crashing on Linux [#]
On some configurations of Red Hat 7.0 the GUI crashes on startup. The solution is to limit the initial stack size prior to launch: ulimit -s 2048.
3.36 [D] Stop GATE Restoring GUI Sessions/Options [#]
GATE will remember GUI options and the state of the resource tree when it exits. The options are saved by default; the session state is not saved by default. This default behaviour can be changed from the “Advanced” tab of the “Configuration” choice on the “Options” menu.
If a problem occurs and the saved data prevents GATE from starting, you can fix it by deleting the configuration and session data files. These are stored in your home directory, and are called gate.xml and gate.sesssion or .gate.xml and .gate.sesssion depending on platform. On Windoze your home is:
- 95, 98, NT:
- Windows Directory/profiles/username
- 2000, XP:
- Windows Drive/Documents and Settings/username
3.37 Work with Unicode [#]
GATE provides various facilities for working with Unicode beyond those that come as default with Java7:
- a Unicode editor with input methods for many languages;
- use of the input methods in all places where text is edited in the GUI;
- a development kit for implementing input methods;
- ability to read diverse character encodings.
1 using the editor:
In the GUI, select ‘Unicode editor’ from the ‘Tools’ menu. This will display an editor window, and,
when a language with a custom input method is selected for input (see next section), a virtual
keyboard window with the characters of the language assigned to the keys on the keyboard.
You can enter data either by typing as normal, or with mouse clicks on the virtual
keyboard.
2 configuring input methods:
In the editor and in GATE’s main window, the ‘Options’ menu has an ‘Input methods’
choice. All supported input languages (a superset of the JDK languages) are available
here. Note that you need to use a font capable of displaying the language you select.
By default GATE will choose a Unicode font if it can find one on the platform you’re
running on. Otherwise, select a font manually from the ‘Options’ menu ‘Configuration’
choice.
3 using the development kit:
GUK, the GATE Unicode Kit, is documented at http://gate.ac.uk/gate/doc/javadoc/guk/package-summary.html.
4 reading different character encodings:
When you create a document from a URL pointing to textual data in GATE, you have to tell the
system what character encoding the text is stored in. By default, GATE will set this
parameter to be the empty string. This tells Java to use the default encoding for whatever
platform it is running on at the time – e.g. on Western versions of Windoze this will be
ISO-8859-1, and Eastern ones ISO-8859-9. A popular way to store Unicode documents is
in UTF-8, which is a superset of ASCII (but can still store all Unicode data); if you
get an error message about document I/O during reading, try setting the encoding to
UTF-8, or some other locally popular encoding. (To see a list of available encodings, try
opening a document in GATE’s unicode editor – you will be prompted to select an
encoding.)
3.38 Work with Oracle and PostgreSQL [#]
GATE’s Oracle layer is documented separately in http://gate.ac.uk/gate/doc/persistence.pdf. Note that running an Oracle installation is not for the faint-hearted!
GATE version 2.2 has been adapted to work with Postgres 7.3. The compatibility with PostgreSQL 7.2 has been preserved. Since version 7.3 the Postgres server doesn’t downcast from int4 to int2 automatically. However, the JDBC drivers seem to have a bug and send the SMALLINT (aka INT2) parameters as INT (aka INT4). This causes some stored procedures (i.e. all that have input parameters of type INT2) not be recognised. We have fixed this problem by modifying the stored procedures to expose the parameters as INT4 and to manually downcast them inside the stored procedure body.
Please note also the following:
PostgreSQL 7.3 refuses to index values larger than 8Kb/3 (2730 bits). The previous versions probably did the same but without raising an exception.
The only case when such a situation can occur in GATE is when a feature has a TEXTUAL value larger than 2730b. This will be signalled by an exception being raised about the value being too large for the index.
To ”solve” this, one can remove the index on the ft_character_value field of the t_feature table. This will have the usual effects caused by removing an index (incapacity of performing efficient searches).
See the example code at http://gate.ac.uk/gate-examples/doc/.
3.39 Annotate using ontologies [#]
This section deals especially with ontologies: how to create/edit them, make Annotation Schemas out of them, and annotate texts automatically with respect to these schemas.
You can load the ontology tools via the plugin manager from the File menu and then Manage CREOLE plugins. Select the Ontology Tools plugin and these tools will be available to you as Processing Resources in the usual way.
Ontology Editor If you double-click on a loaded ontology in the left resources tree in GATE, it will be loaded in the main window. For more information, see section 10.4.
OntoGazetteer The OntoGazetteer is a Processing Resource in which lists of instances of ontology concepts can be loaded. For the OntoGazetteer to function properly, it needs one or more .lst files, and two .def files, usually called mappings.def, and lists.def.
The .lst file is simply a file with an instance on every line. For instance persons.lst will have, on every line, the name of a person.
The mappings.def file describes the relations between the .lst files and the ontology concepts. The format is .lst file:ontology file:ontology concept.
The lists.def file states the relations between the .lst files and the annotation feature the OntoGazetteer should generate. The format is: .lst file:feature
The OntoGazetteer, when run, generates annotations for every instance mentioned in the .lst files. All these instances will be annotated with the same annotation type, called ’Lookup’ ( in the ’default’ Annotation Set). Every Lookup annotation will have a feature, which is its majorType, which will differ per .lst file.
This is not very useful, because every different concept from the ontology will have the same annotation type (namely ’Lookup’). However, since the ’majorType’ feature differs, we can process them further. And to do that, we need a Jape Transducer.
Jape Transducer A Jape transducer is a Processing Resource for manipulating annotations. For instance, the annotations generated by the OntoGazetteer can be transcribed to distinct annotations. For this, the Jape Transducer needs a Jape grammar, usually stored in a .jape file. A Jape grammar describes which annotations should be changed, and how. See Chapter 7 for further reference on Jape rules.
Creating a pipeline Once a Processing Resource is loaded, it can be included in a pipeline. To do so, right click on ’Applications’ in the left resources tree, and choose one of the appropriate options. A particularly useful one is the ’Corpus Pipeline’ that lets you run an application on an entire corpus. A pipeline is created by dragging the Processing Resources into it. They will be run one after another.
NOTE that in order to run the OntoGazetteer, only the OntoGazetteer needs to be selected, and not the Hash Gazetteer.
How to generate annotations automatically Now that all the building blocks have been discussed, let us describe how to actually construct something useful out of it.
Our aim is to have an Annotation Set that contains the concepts out of the ontology. First, we make an OntoGazetteer. This we build from our ontology, and lists.def and mappings.def file. Suppose we run the OntoGazetteer on our corpus. This would produce, as described above, ’Lookup’ annotations with a feature majorType set to ’Department’.
Now we want to have a Jape rule that turns this annotation into an annotation of type ’Department’. So it should select every annotation with ’Department’ as its majorType, and convert it. This is the rule that does it:
Rule: departmentsRule
( {Lookup.majorType == Department} ):departmentslabel --> :departmentslabel.Department = {rule = "departmentsRule"} |
This then is all we need. We build a corpus pipeline with first the OntoGazetteer, and then the Jape Transducer, and if it is run, the corpus will get annotated automatically.
1In this specific case, the alternative config file must already exist when GATE starts up, so you should copy your standard gate.xml file to the new location.
3This method is not part of the beans spec.
4Alternatively a string giving the document source may be provided.
5existing features outwith the schema, e.g. those created by previously-run processing resources, are not editable but not modified or removed by the editor.
6Gorey details: features of annotations and documents in GATE may be any virtually any Java object; serialising arbitrary binary data to XML is not simple; instead we serialise them as strings, and therefore they will be re-loaded as strings.
7Implemented by Valentin Tablan, Mark Leisher and Markus Kramer. Initial version developed by Mark Leisher.
