Chapter 9
ANNIC: ANNotations-In-Context [#]
ANNIC (ANNotations-In-Context) is a full-featured annotation indexing and retrieval system. It is provided as part of an extension of the Serial Data-stores, called Searchable Serial Data-store (SSD).
ANNIC can index documents in any format supported by the GATE system (i.e., XML, HTML, RTF, e-mail, text, etc). Compared with other such query systems, it has additional features addressing issues such as extensive indexing of linguistic information associated with document content, independent of document format. It also allows indexing and extraction of information from overlapping annotations and features. Its advanced graphical user interface provides a graphical view of annotation markups over the text, along with an ability to build new queries interactively. In addition, ANNIC can be used as a first step in rule development for NLP systems as it enables the discovery and testing of patterns in corpora.
ANNIC is built on top of the Apache Lucene1 – a high performance full-featured search engine implemented in Java, which supports indexing and search of large document collections. Our choice of IR engine is due to the customisability of Lucene. For more details on how Lucene was modified to meet the requirements of indexing and querying annotations, please refer to [Aswani et al. 05].
As explained earlier, SSD is an extension of the serial data-store. In addition to the persist location, SSD asks user to provide some more information (explained later) that it uses to index the documents. Once the SSD has been initiated, user can add/remove documents/corpora to the SSD in a similar way it is done with other data-stores. When documents are added to the SSD, it automatically tries to index them. It updates the index whenever there is a change in any of the documents stored in the SSD and removes the document from the index if it is deleted from the SSD. Be warned that only the annotation sets, types and features initially provided during the SSD creation time, will be updated when adding/removing documents to the datastore.
SSD has an advanced graphical interface that allows users to issue queries over the SSD. Below we explain the parameters required by SSD and how to instantiate it, how to use its graphical interface and how to use SSD programmatically.
9.1 Instantiating SSD [#]
Steps:
-
In GATE Developer, right click on ‘Datastores’ and select ‘Create Datastore’.
-
From a drop-down list select ‘Lucene Based Searchable DataStore’.
-
Here, you will see a file dialog. Please select an empty folder for your datastore. This is similar to the procedure of creating a serial datastore.
-
After this, you will see an input window. Please provide these parameters:
-
DataStore URL: This is the URL of the datastore folder selected in the previous step.
-
Index Location: By default, the location of index is calculated from the datastore location. It is done by appending ‘-index’ to the datastore location. If user wants to change this location, it is possible to do so by clicking on the folder icon and selecting another empty folder. If the selected folder exists already, the system will check if it is an empty folder. If the selected folder does not exist, the system tries to create it.
-
Annotation Sets: Here, you can provide one or more annotation sets that you wish to index or exclude from being indexed. By default, the default annotation set and the ‘Key’ annotation set are included. User can change this selection by clicking on the edit list icon and removing or adding appropriate annotation set names. In order to be able to readd the default annotation set, you must click on the edit list icon and add an empty field to the list. If there are no annotation sets provided, all the annotation sets in all documents are indexed.
-
Base-Token Type: (e.g. Token or Key.Token) These are the basic tokens of any document. Your documents must have the annotations of Base-Token-Type in order to get indexed. These basic tokens are used for displaying contextual information while searching patterns in the corpus. In case of indexing more than one annotation set, user can specify the annotation set from which the tokens should be taken (e.g. Key.Token- annotations of type Token from the annotation set called Key). In case user does not provide any annotation set name (e.g. Token), the system searches in all the annotation sets to be indexed and the base-tokens from the first annotation set with the base token annotations are taken. Please note that the documents with no base-tokens are not indexed. However, if the ‘create tokens automatically’ option is selected, the SSD creates base-tokens automatically. Here, each string delimited with white space is considered as a token.
-
Index Unit Type: (e.g. Sentence, Key.Sentence) This specifies the unit of Index. In other words, annotations lying within the boundaries of these annotations are indexed (e.g. in the case of ‘Sentences’, no annotations that are spanned across the boundaries of two sentences are considered for indexing). User can specify from which annotation set the index unit annotations should be considered. If user does not provide any annotation set, the SSD searches among all annotation sets for index units. If this field is left empty or SSD fails to locate index units, the entire document is considered as a single unit.
-
Features: Finally, users can specify the annotation types and features that should be indexed or excluded from being indexed. (e.g. SpaceToken and Split). If user wants to exclude only a specific feature of a specific annotation type, he/she can specify it using a ’.’ separator between the annotation type and its feature (e.g. Person.matches).
-
-
Click OK. If all parameters are OK, a new empty DS will be created.
-
Create an empty corpus and save it to the SSD.
-
Populate it with some documents. Each document added to the corpus and eventually to the SSD is indexed automatically. If the document does not have the required annotations, that document is skipped and not indexed.
SSDs are portable and can be moved across different systems. However, the relative positions of both the datastore folder and the respective index folder must be maintained. If it is not possible to maintain the relative positions, the new location of the index must be specified inside the ‘__GATE_SerialDataStore__’ file inside the datastore folder.
9.2 Search GUI [#]
9.2.1 Overview
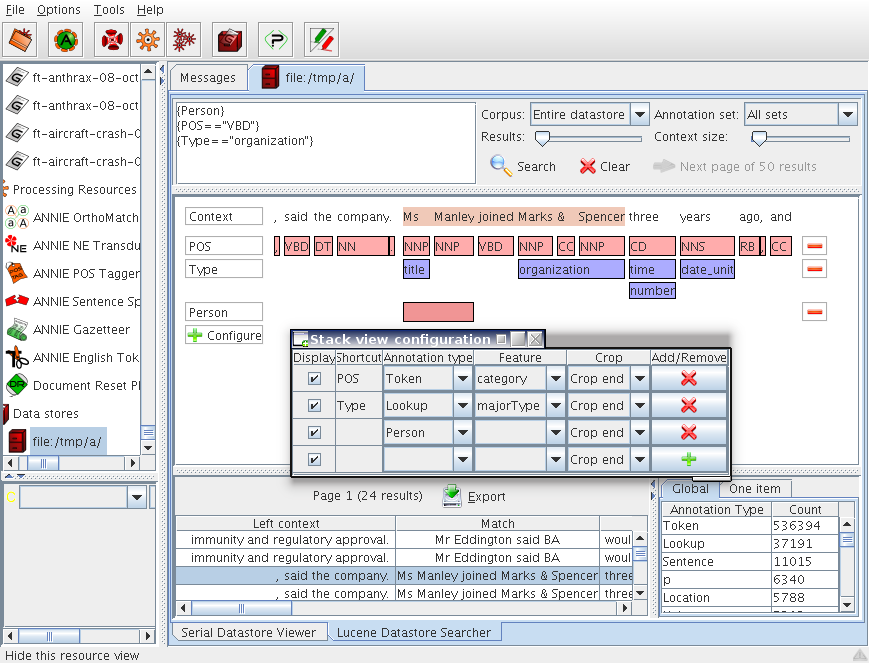
Figure 9.1 shows the search GUI for a datastore. The top section contains a text area to write a query, lists to select the corpus and annotation set to search in, sliders to set the size of the results and context and icons to execute and clear the query.
The central section shows a graphical visualisation of stacked annotations and feature values for the result row selected in the bottom results table. There is a configuration window where you define which annotation type and feature to display in the central section.
The bottom section contains the results table of the query, i.e. the text that matches the query with their left and right contexts. The bottom section contains also a tabbed pane of statistics.
9.2.2 Syntax of Queries [#]
SSD enables you to formulate versatile queries using a subset of JAPE patterns. Below, we give the JAPE pattern clauses which can be used as SSD queries. Queries can also be a combination of one or more of the following pattern clauses.
-
String
-
{AnnotationType}
-
{AnnotationType == String}
-
{AnnotationType.feature == feature value}
-
{AnnotationType1, AnnotationType2.feature == featureValue}
-
{AnnotationType1.feature == featureValue, AnnotationType2.feature == featureValue}
JAPE patterns also support the | (OR) operator. For instance, {A} ({B} | {C}) is a pattern of two annotations where the first is an annotation of type A followed by the annotation of type either B or C.
ANNIC supports two operators, + and *, to specify the number of times a particular annotation or a sub pattern should appear in the main query pattern. Here, ({A})+n means one and up to n occurrences of annotation {A} and ({A})*n means zero or up to n occurrences of annotation {A}.
Below we explain the steps to search in SSD.
-
Double click on SSD. You will see an extra tab “Lucene DataStore Searcher”. Click on it to activate the searcher GUI.
-
Here you can specify a query to search in your SSD. The query here is a L.H.S. part of the JAPE grammar. Here are some examples:
-
{Person} – This will return annotations of type Person from the SSD
-
{Token.string == “Microsoft”} – This will return all occurrences of “Microsoft” from the SSD.
-
{Person}({Token})*2{Organization} – Person followed by zero or up to two tokens followed by Organization.
-
{Token.orth==“upperInitial”, Organization} – Token with feature orth with value set to “upperInitial” and which is also annotated as Organization.
-
9.2.3 Top Section [#]
A text-area located in the top left part of the GUI is used to input a query. You can copy/cut/paste with Control+C/X/V, undo/redo your changes with Control+Z/Y as usual. To add a new line, use Control+Enter key combination.
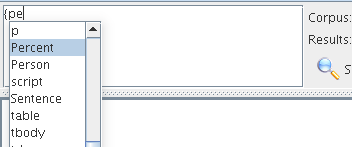
Auto-completion as shown in figure 9.2 for annotation type is triggered when typing ’{’ or ’,’ and for feature when typing ’.’ after a valid annotation type. It shows only the annotation types and features related to the selected corpus and annotation set.
If you right-click on an expression it will automatically select the shortest valid enclosing brace and if you click on a selection it will propose you to add quantifiers for allowing the expression to appear zero, one or more times.
To execute the query, click on the magnifying glass icon, use Enter key or Alt+Enter key combination. To clear the query, click on the red X icon or use Alt+Backspace key combination.
It is possible to have more than one corpus, each containing a different set of documents, stored in a single data-store. ANNIC, by providing a drop down box with a list of stored corpora, also allows searching within a specific corpus. Similarly a document can have more than one annotation set indexed and therefore ANNIC also provides a drop down box with a list of indexed annotation sets for the selected corpus.
A large corpus can have many hits for a given query. This may take a long time to refresh the GUI and may create inconvenience while browsing through results. Therefore you can specify the number of results to retrieve. Use the Next Page of Results button to iterate through results. Due to technical complexities, it is not possible to visit a previous page. To retrieve all the results at the same time, push the results slider to the right end.
9.2.4 Central Section [#]
Annotation types and features to show can be configured from the stack view configuration window by clicking on the Configure button at the bottom of the annotation stack. You can also change the feature value displayed by double clicking on the annotation type name in the first column.
The central section shows coloured rectangles exactly below the spans of text where these annotations occur. If only an annotation type is displayed, the rectangle remains empty. When you hover the mouse over the rectangle, it shows all their features and values in a tooltip. If an annotation type and a feature are displayed, the value of that feature is shown in the rectangle.
Shortcuts are expressions that stand for an "AnnotationType.Feature" expression. For example, on the figure 9.1, the shortcut "POS" stands for the expression "Token.category".
When you double click on an annotation rectangle, the respective query expression is placed at the caret position in the query text area. If you have selected anything in the query text area, it gets replaced. You can also double click on a word on the first line to add it to the query.
9.2.5 Bottom Section [#]
The table of results contains the text matched by the query, the contexts, the features displayed in the central view but only for the matching part, the effective query, the document and annotation set names. You can sort a table column by clicking on its header.
You can remove a result from the results table or open the document containing it by right-clicking on a result in the results table.
ANNIC provides an Export button to export results into an HTML file. You can also select then copy/paste the table in your word processor or spreadsheet.
A statistics tabbed pane is displayed at the bottom right. There is always a global statistics pane that lists the count of the occurrences of all annotation types for the selected corpus and annotation set. Double clicking on a row adds the annotation type to the query.
Statistics can be obtained for matched spans of the query in the results, with or without contexts, just by annotation type, an annotation type + feature or an annotation type + feature + value. A second pane contains the one item statistics that you can add by right-clicking on a non empty annotation rectangle or on the first column of a row in the central section. You can sort a table column by clicking on its header.
9.3 Using SSD from GATE Embedded [#]
9.3.1 How to instantiate a searchabledatastore
2// create an instance of datastore
3LuceneDataStoreImpl ds = (LuceneDataStoreImpl)
4 Factory.createDataStore(‘‘gate.persist.LuceneDataStoreImpl’’,
5 dsLocation);
6
7// we need to set Indexer
8Indexer indexer = new LuceneIndexer(new URL(indexLocation));
9
10// set the parameters
11Map parameters = new HashMap();
12
13// specify the index url
14parameters.put(Constants.INDEX_LOCATION_URL, new URL(indexLocation));
15
16// specify the base token type
17// and specify that the tokens should be created automatically
18// if not found in the document
19parameters.put(Constants.BASE_TOKEN_ANNOTATION_TYPE, ‘‘Token’’);
20parameters.put(Constants.CREATE_TOKENS_AUTOMATICALLY,
21 new Boolean(true));
22
23// specify the index unit type
24parameters.put(Constants.INDEX_UNIT_ANNOTATION_TYPE, ‘‘Sentence’’);
25
26// specifying the annotation sets "Key" and "Default Annotation Set"
27// to be indexed
28List<String> setsToInclude = new ArrayList<String>();
29setsToInclude.add("Key");
30setsToInclude.add("<null>");
31parameters.put(Constants.ANNOTATION_SETS_NAMES_TO_INCLUDE,
32 setsToInclude);
33parameters.put(Constants.ANNOTATION_SETS_NAMES_TO_EXCLUDE,
34 new ArrayList<String>());
35
36// all features should be indexed
37parameters.put(Constants.FEATURES_TO_INCLUDE, new ArrayList<String>());
38parameters.put(Constants.FEATURES_TO_EXCLUDE, new ArrayList<String>());
39
40// set the indexer
41ds.setIndexer(indexer, parameters);
42
43// set the searcher
44ds.setSearcher(new LuceneSearcher());
9.3.2 How to search in this datastore
2// obtain the searcher instance
3Searcher searcher = ds.getSearcher();
4Map parameters = new HashMap();
5
6// obtain the url of index
7String indexLocation =
8 new File(((URL) ds.getIndexer().getParameters()
9 .get(Constants.INDEX_LOCATION_URL)).getFile()).getAbsolutePath();
10ArrayList indexLocations = new ArrayList();
11indexLocations.add(indexLocation);
12
13
14// corpus2SearchIn = mention corpus name that was indexed here.
15
16// the annotation set to search in
17String annotationSet2SearchIn = "Key";
18
19// set the parameter
20parameters.put(Constants.INDEX_LOCATIONS,indexLocations);
21parameters.put(Constants.CORPUS_ID, corpus2SearchIn);
22parameters.put(Constants.ANNOTATION_SET_ID, annotationSet);
23parameters.put(Constants.CONTEXT_WINDOW, contextWindow);
24parameters.put(Constants.NO_OF_PATTERNS, noOfPatterns);
25
26// search
27String query = "{Person}";
28Hit[] hits = searcher.search(query, parameters);
1http://lucene.apache.org
