Chapter 15
Machine Learning [#]
This chapter presents machine learning PRs available in GATE. Currently, two PRs are available:
- The Batch Learning PR (in the Learning plugin) is GATE’s most comprehensive and developed machine learning offering. It is specifically targetted at NLP tasks including text classification, chunk learning (e.g. for named entity recognition) and relation learning. It integrates LibSVM for improved speed, along with the PAUM algorithm, offering very competitive performance and speed. It also offers a Weka interface. It is documented in Section 15.2.
- The Machine Learning PR (in the Machine_Learning plugin) is GATE’s older machine learning offering. It offers wrappers for Maxent, Weka and SVM Light. It is documented in Section 15.3.
The rest of the chapter is organised as follows. Section 15.1 introduces machine learning in general, focusing on the terminology used and the meaning of the terms within GATE. We then move on to describe the two Machine Learning processing resources, beginning with the Batch Learning PR in Section 15.2. Section 15.2.1 describes all the configuration settings of the Batch Learning PR one by one; i.e. all the elements in the configuration file for setting the Batch Learning PR (the learning algorithm to be used and the options for learning) and defining the NLP features for the problem. Section 15.2.2 presents three case studies with example configuration files for the three types of NLP learning problems. Section 15.2.3 lists the steps involved in using the Batch Learning PR. Finally, Section 15.2.4 explains the outputs of the Batch Learning PR for the four usage modes; namely training, application, evaluation and producing feature files only, and in particular, the format of the feature files and label list file produced by the Batch Learning PR. Section 15.3 outlines the original Machine Learning PR in GATE.
15.1 ML Generalities [#]
There are two main types of ML; supervised learning and unsupervised learning. Supervised learning is more effective and much more widely used in NLP. Classification is a particular example of supervised learning, in which the set of training examples is split into multiple subsets (classes) and the algorithm attempts to distribute new examples into the existing classes. This is the type of ML that is used in GATE, and all further references to ML actually refer to classification.
An ML algorithm ‘learns’ about a phenomenon by looking at a set of occurrences of that phenomenon that are used as examples. Based on these, a model is built that can be used to predict characteristics of future (unseen) examples of the phenomenon.
An ML implementation has two modes of functioning: training and application. The training phase consists of building a model (e.g. a statistical model, a decision tree, a rule set, etc.) from a dataset of already classified instances. During application, the model built during training is used to classify new instances.
Machine Learning in NLP falls broadly into three categories of task type; text classification, chunk recognition, and relation extraction
- Text classification classifies text into pre-defined categories. The process can be equally well applied at the document, sentence or token level. Typical examples of text classification might be document classification, opinionated sentence recognition, POS tagging of tokens and word sense disambiguation.
- Chunk recognition often consists of two steps. First, it identifies the chunks of interest in the text. It then assigns a label or labels to these chunks. However some problems comprise simply the first step; identifying the relevant chunks. Examples of chunk recognition include named entity recognition (and more generally, information extraction), NP chunking and Chinese word segmentation.
- Relation extraction determines whether or not a pair of terms in the text has some type(s) of pre-defined relations. Two examples are named entity relation extraction and co-reference resolution.
Typically, the three types of NLP learning use different linguistic features and feature representations. For example, it has been recognised that for text classification the so-called tf - idf representation of n-grams is very effective (e.g. with SVM). For chunk recognition, identifying the start token and the end token of the chunk by using the linguistic features of the token itself and the surrounding tokens is effective and efficient. Relation extraction benefits from both the linguistic features from each of the two terms involved in the relation and the features of the two terms combined.
The rest of this section explains some basic definitions in ML and their specification in the ML plugin.
15.1.1 Some Definitions
- instance: an example of the studied phenomenon. An ML algorithm learns a model from a set of known instances, called a (training) dataset. It can then apply the learned model to another (application) dataset.
- attribute: a characteristic of the instances. Each instance is defined by the values of its attributes. The set of possible attributes is well defined and is the same for all instances in the training and application datasets. ‘Feature’ is also often used. However, in this context, this can cause confusion with GATE annotation features.
- class: an attribute for which the values are available in the training dataset for learning, but which are not present in the application dataset. ML is used to find the value of this attribute in the application dataset.
15.1.2 GATE-Specific Interpretation of the Above Definitions
- instance: an annotation. In order to use ML in GATE, users will need to choose the type of annotations used as instances. Token annotations are a good candidate for many NLP learning tasks such as information extraction and POS tagging, but any type of annotation could be used (e.g. things that were found by a previously run JAPE grammar, such as sentence annotations and document annotations for sentence and document classification respectively).
- attribute: an attribute is the value of a named feature of a particular annotation type, which can either (partially) cover the instance annotation considered or another instance annotation which is related to the instance annotation considered. The value of the attribute can refer to the current instance or to an instance either situated at a specified location relative to the current instance or having special relation with the current instance.
- class: any attribute referring to the current instance can be marked as class attribute.
15.2 Batch Learning PR [#]
This section describes the newest machine learning PR in GATE. The implementation focuses on the three main types of learning in NLP, namely chunk recognition (e.g. named entity recognition), text classification and relation extraction. The implementation for chunk recognition is based on our work using support vector machines (SVM) for information extraction [Li et al. 05a]. The text classification is based on our work on opinionated sentence classification and patent document classification (see [Li et al. 07c] and [Li et al. 07d], respectively). The relation extraction is based on our work on named entity relation extraction [Wang et al. 06].
The Batch Learning PR, given a set of documents, can also produce feature files, containing linguistic features and feature vectors, and labels if there are any in the documents. It can also produce document-term matrices and n-gram based language models. Feature files are in text format and can be used outside of GATE. Hence, users can use GATE-produced feature files off-line, for their own purpose, e.g. evaluating new learning algorithms.
The PR also provides facilities for active learning, based on support vector machines (SVM), mainly ranking the unlabelled documents according to the confidence scores of the current SVM models for those documents.
The primary learning algorithm implemented is SVM, which has achieved state of the art performances for many NLP learning tasks. The training of SVM uses a Java version of the SVM package LibSVM [CC001]. Application of SVM is implemented by ourselves. The PAUM (Perceptron Algorithm with Uneven Margins) is also included [Li et al. 02], and on our test datasets has consistently produced a performance to rival the SVM with much reduced training times. Moreover, the ML implementation provides an interface to the open-source machine learning package Weka [Witten & Frank 99], and can use machine learning algorithms implemented in Weka. Three widely-used learning algorithms are available in the current implementation: Naive Bayes, KNN and the C4.5 decision tree algorithm.
Access to ML implementations is provided in GATE by the ‘Batch Learning PR’ (in the ‘learning’ plugin). The PR handles training and application of an ML model, evaluation of learning on GATE documents, producing feature files and ranking documents for Active Learning. It also makes it possible to view the primal forms of a linear SVM. This PR is a Language Analyser so it can be used in all default types of GATE controllers.
In order to use the Batch Learning processing resource, the user has to do three things. First, the user has to annotate some training documents with the labels that s/he wants the learning system to annotate in new documents. Those label annotations should be GATE annotations. Secondly, the user may need to pre-process the documents to obtain linguistic features for the learning. Again, these features should be in the form of GATE annotations. GATE’s plugin ANNIE might be helpful for producing the linguistic features. Other resources such as the NP Chunker and parser may also be helpful. By providing the machine learning algorithm with more and better information on which to base learning, chances of a good result are increased, so this preprocessing stage is important. Finally the user has to create a configuration file for setting the ML PR, e.g. selecting the learning algorithm and defining the linguistic features used in learning. Three example configuration files are presented in this section; it might be helpful to take one of them as a starting point and modify it.
15.2.1 Batch Learning PR Configuration File Settings [#]
In order to allow for more flexibility, all configuration parameters for the PR are set through one external XML file, except for the learning mode, which is selected through normal PR parameterisation. The XML file contains both the configuration parameters of the Batch Learning PR itself and of the linguistic data (namely the definitions of the instance and attributes) used by the Batch Learning PR. The XML file is specified when creating a new Batch Learning PR.
The parent directory of the XML configuration file becomes the working directory. A subdirectory in the working directory, named ‘savedFiles’, will be created (if it does not already exist). All the files produced by the Batch Learning PR, including the NLP features files, label list file, feature vector file and learned model file, will be stored in that subdirectory. A log file recording the learning session is also created in this directory.
Below, we first describe the parameters of the Batch Learning PR. Then we explain those settings specified in the configuration file.
PR Parameters: Settings not Specified in the Configuration File [#]
For the sake of convenience, a few settings are not specified in the configuration file. Instead the user should specify them as initialization or run-time parameters of the PR, as in other PRs.
- URL (or path and name) of the configuration file. The user is required to give the URL of the configuration file when creating the PR. The configuration file should be in XML format with the extension name .xml. It contains most of learning settings and will be explained in detail in the next subsection.
- Corpus. This is a run-time parameter, meaning that the user should specify it after creating the PR, and may change it between runs. The corpus contains the documents that the PR will use as learning data (training or application). For application, the documents should include all the annotations specified in the configuration file, except the class attribute. The annotations for class attribute should be available in the documents used for training or evaluation.
- inputASName is the annotation set containing the annotations for the linguistic features to be used and the class labels.
- outputASName is the annotation set in which the results of applying the models will be put. Note that it should be set the same as the inputASName when doing the evaluation (i.e. setting the learningMode as ‘EVALUATION’).
- learningMode is a run-time parameter. It can be set as one of the following
values, ‘TRAINING’, ‘APPLICATION’, ‘EVALUATION’, ‘ProduceFeatureFilesOnly’,
‘MITRAINING’, ‘VIEWPRIMALFORMMODELS’ and ‘RankingDocsForAL’. The
default learning mode is ‘TRAINING’.
- In TRAINING mode, the PR learns from the data provided and saves the models into a file called ‘learnedModels.save’ under the sub-directory ‘savedFiles’ of the working directory.
- If the user wants to apply the learned model to the data, s/he should select APPLICATION mode. In application mode, the PR reads the learned model from the file ‘learnedModels.save’ in the subdirectory ‘savedFiles’ and then applies the model to the data.
- In EVALUATION mode, the PR will do k-fold or hold-out test set evaluation on the corpus provided (the method of the evaluation is specified in the configuration file, see below), and output the evaluation results to the messages window of GATE Developer, or standard out when using GATE Embedded, and into the log file. When using evaluation mode, please make sure that the outputASName is set to the same annotation set as the inputASName.
- If the user only wants to produce feature data and feature vectors but does not want to train or apply a model, s/he may select the ProduceFeatureFilesOnly mode. The feature files that the PR produces will be explained in detail in Section 15.2.4.
- In MITRAINING (mixed initiative training) mode, the training data are appended to the end of any existing feature file. In contrast, in training mode, the training data created in the current session overwrite any existing feature file. Consequently, mixed initiative training mode uses both the training data obtained in this session and the data that existed in the feature file before starting the session. Hence, training mode is for batch learning, while mixed initiative training mode can be used for on-line (or adaptive, or mixed-initiative) learning. There is one parameter for mixed initiative training mode specifying the minimal number of newly added documents before starting the learning procedure to update the learned model. The parameter can be defined in the configuration file.
- VIEWPRIMALFORMMODELS mode is used for displaying the most salient NLP features in the learned models. In the current implementation, the mode is only valid with the linear SVM model, in which the most salient NLP features correspond to the biggest (absolute values of) weights in the weight vector. In the configuration file one can specify two parameters to determine the number of displayed NLP features for positive and negative weights. Note that if e.g. the number for negative weight is set as 0, then no NLP feature is displayed for negative weights.
- RankingDocsForAL applies the current learned SVM models (in the sub-directory ‘savedFiles’) to the feature vectors stored in the file ‘fvsDataSelecting.save’ in the sub-directory ‘savedFiles’ and ranks the documents according to the margins of the examples in one document to the SVM models. The ranked list of documents will be put into the file ‘ALRankedDocs.save’.
In most cases it is not safe to run more than one instance of the batch learning PR with the same working directory at the same time, because the PR needs to update the model (in TRAINING, MITRAINING or EVALUATION mode) or other data files. It is safe to run multiple instances at once provided they are all in APPLICATION mode1.
Order of document processing In the usual case, in a GATE corpus pipeline application, documents are processed one at a time, and each PR is applied in turn to the document, processing it fully, before moving on to the next document. The Batch Learning PR breaks from this rule. ML training algorithms, including SVM, typically run as a batch process over a training set, and require all the data to be fully prepared and passed to the algorithm in one go. This means that in training (or evaluation) mode, the Batch Learning PR will wait for all the documents to be processed and will then run as a single operation at the end. Therefore, the Batch Learning PR needs to be positioned last in the pipeline. Post-processing cannot be done within the pipeline after the Batch Learning PR. Where further processing needs to be done, this should take the form of a separate application, and be applied to the data afterwards.
There is an exception to the above, however. In application mode, the situation is slightly different, since the ML model has already been created, and the PR only applies it to the data. This can be done on a document by document basis, in the manner of a normal PR. However, although it can be done document by document, there may be advantages in terms of efficiency to grouping documents into batches before applying the algorithm. A parameter in the configuration file, BATCH-APP-INTERVAL, described later, allows the user to specify the size of such batches, and by default this is set to 1; in other words, by default, the Batch Learning PR in application mode behaves like a normal PR and processes each document separately. There may be substantial efficiency gains to be had through increasing this parameter (although higher values require more memory consumption), but if the Batch Learning PR is applied in application mode and the parameter BATCH-APP-INTERVAL is set to 1, the PR can be treated like any other, and other PRs may be positioned after it in a pipeline.
Settings in the Batch Learning PR XML Configuration File [#]
The root element of the XML configuration file needs to be called ‘ML-CONFIG’, and it must contain two basic elements; DATASET and ENGINE, and optionally other settings. In the following, we first describe the optional settings, then the ENGINE element, and finally the DATASET element. In the next section, some examples of the XML configuration file are given for illustration. Please also refer to the configuration files in the test directory (i.e. plugs/learning/test/ under the main gate directory) for more examples.
Optional Settings in the Configuration File The Batch Learning PR provides a variety of optional settings, which facilitate different tasks. Every optional setting has a default value; if an optional setting is not specified in the configuration file, the Batch Learning PR will adopt its default value. Each of the following optional settings can be set as an element in the XML configuration file.
- SURROUND should be set to ‘true’ if the user wants the Batch Learning PR to learn
chunks by identifying the start token and the end token of the chunk. This approach to
chunk learning, for example, named entity recognition, where a span of several tokens
is to be identified, often produces better results than trying to learn every token in the
chunk. For classification problems and relation extraction, set its value as ‘false’. This
element appears in the configuration file as:
<SURROUND VALUE=’X’/>
where the variable X has two possible values: ‘true’ or ‘false’. The default value is ‘false’. - FILTERING relates to SVM training. Where the ratio of positive examples
to negative examples is low, i.e. the instances belonging in the class are much
outweighed by instances outside of the class (e.g. ‘one against others’ is used,
see multiClassification2Binary below) SVMs can run into difficulties. The positive
examples may be swamped by outlying negative examples. The ML plugin provides
functionality developed through research (e.g. [Li & Bontcheva 08]) to assist in such
cases. One example is the FILTERING parameter. The filtering functionality performs
initial SVM training, then removes negative examples on the basis of their position
relative to the separator. It then retrains on the smaller dataset. Typically, negative
instances close to the boundary are removed. Note that this two-step process takes
longer than simple training. However, the second training step will be quicker than the
first, as it is performed on a somewhat reduced dataset. If the item dis is set as ‘near’,
the PR selects and removes those negative examples which are closest to the SVM
hyper-plane. If it is set as ‘far’, those negative examples that are furthest from the
SVM hyper-plane are removed. The value of the item ratio determines what proportion
of negative examples will be filtered out. This element appears in the configuration file
as:
< FILTERING ratio=’X’ dis=’Y’/>
where X represents a number between 0 and 1 and Y can be set as ‘near’ or ‘far’. If the filtering element is not present in the configuration file, or the value of ratio is set as 0.0, the PR does not perform filtering. The default value of ratio is 0.0. The default value of dis is ‘far’. - EVALUATION As outlined above, if the learning mode parameter learningMode
is set to ‘EVALUATION’, the PR will perform evaluation of the ML model; it will
split the documents in the corpus into two parts, the training dataset and the test
dataset, learn a model from the training dataset, apply the model to the testing dataset,
and finally compare the annotations assigned by the model on the test set with the
true annotations and output measures of success (e.g. F-measure). The evaluation
element specifies the method of splitting the corpus. The item method determines which
method to use for evaluation. Currently two commonly used methods are implemented,
namely k-fold cross-validation and hold-out test. In k-fold cross-validation the PR
segments the corpus into k partitions of equal size, and uses each of the partitions in
turn as a test set, with all the remaining documents as a training set. For hold-out
test, the system randomly selects some documents as testing data and uses all other
documents as training data. The value of the item runs specifies the number ‘k’ for
k-fold cross-validation. The value of the item ratio specifies the ratio of the data used
for training in the hold-out test method. The element in the configuration file appears
as so:
<EVALUATION method=”X” runs=”Y” ratio=”Z”/>
where the variable X has two possible values ‘kfold’ and ‘holdout’, Y is a positive integer, and Z is a float number between 0 and 1. The default value of method is ‘holdout’. The default value of runs is ‘1’. The default value of ratio is ‘0.66’. - multiClassification2Binary. Certain machine learning algorithms, including SVM,
are designed to operate on two class problems; they find a separator between two groups
of instances. In order to use such algorithms to classify items into a larger number of
classes, the problem has to be converted into a series of ‘binary’ (two class) problems.
The ML plugin implements two common methods for converting a multi-class problem
into several binary problems, namely one against others and one against another. The
two methods may have slightly different names in other publications, but the principle
is the same. Suppose we have a multi-class classification problem with n classes. For
the one against others method, one binary classification problem is derived for each of
the n classes. Examples belonging to the class in question are considered to be positive
examples and all other examples in the training set are negative examples. In contrast,
for the one against another method, one binary classification problem is derived for
each pair (c1,c2) of the n classes. Training examples belonging to the class c1 are the
positive examples and those belonging to the other class, c2, are the negative examples.
The user can select one of the two methods by specifying the value of the item method
of the element. The element appears as so:
<multiClassification2Binary method=”X” thread-pool-size=”N”/>
where the variable X has two values, ‘one-vs-others’ and ‘one-vs-another’. Note that depending on the sample size, the two methods may differ greatly in their speed of execution. The default method is the one-vs-others method. If the configuration file does not have the element or the item method is missed, then the PR will use the one-vs-others method. Since the derived binary classifiers are independent it is possible to learn several of them in parallel. The ‘thread-pool-size’ attribute gives the number of threads that will be used to learn and apply the binary classifiers. If omitted, a single thread will be used to process all the classifiers in sequence. - thresholdProbabilityBoundary sets a confidence threshold on start and end tokens
for chunk learning. It is used in post-processing the learning results. Only those
boundary tokens in which the confidence level is above the threshold are selected as
candidates for the entities. The element in configuration file appears as so:
<PARAMETER name=”thresholdProbabilityBoundary” value=”X”/>
The value X is between 0 and 1. The default value is 0.4. - thresholdProbabilityEntity sets a confidence threshold on chunks (which is the
multiplication of the probabilities of the start token and end token of the chunk) for
chunk learning. Only those entities in which the confidence level is above the threshold
are selected as candidates of the entities. The element in configuration file appears as
so:
<PARAMETER name=”thresholdProbabilityEntity” value=”X”/>
The value X is between 0 and 1. The default value is 0.2. - The threshold parameter thresholdProbabilityClassification is the confidence
threshold for classification (e.g. text classification and relation extraction tasks. In
contrast, the above two probabilities are for the chunking recognition task.) The
corresponding element in configuration file appears as so:
<PARAMETER name=”thresholdProbabilityClassification” value=”X”/>
The value X is between 0 and 1. The default value is 0.5. - IS-LABEL-UPDATABLE is a Boolean parameter. If its value is set to ‘true’, the
label list is updated from the labels in the training data. Otherwise, a pre-defined label
list will be used and cannot be updated from the training data. The configuration
element appears as so:
<IS-LABEL-UPDATABLE value=”X”/>
The value X is ‘true’ or ‘false’. The default value is ‘true’. - IS-NLPFEATURELIST-UPDATABLE is a Boolean parameter. If its value is set
to ‘true’, the NLP feature list is updated from the features in the training or application
data. Otherwise, a pre-defined NLP feature list will be used and cannot be updated.
The configuration element appears as so:
<IS-NLPFEATURELIST-UPDATABLE value=”X”/>
The value X is ‘true’ or ‘false’. The default value is ‘true’. - The parameter VERBOSITY specifies the verbosity level of the output of the system,
both to the message window of GATE Developer (or standard out when using GATE
Embedded) and into the log file. Currently there are three verbosity levels. Level 0
only allows the output of warning messages. Level 1 outputs some important setting
information and the results for evaluation mode. Level 2 is used for debugging purposes.
The element in the configuration file appears as so:
<VERBOSITY level=”X”/>
The value X can be set as 0, 1 or 2. The default value is 1. - MI-TRAINING-INTERVAL specifies the minimal number of newly added
documents needed to trigger retraining the model. This parameter is used in
MITRAINING. The number is specified by the value of the feature ‘num’ as so:
<MI-TRAINING-INTERVAL num=”X”/>
The default value of X is 1. - BATCH-APP-INTERVAL is used in application mode, and specifies the number
of documents to be collected and passed as a batch for classification. Please refer to
Section 15.2.1 for a detailed explanation of this option. The corresponding element in
the configuration file is:
<BATCH-APP-INTERVAL num=”X”/>
The default value of X is 1. - DISPLAY-NLPFEATURES-LINEARSVM relates
to ‘VIEWPRIMALFORMMODELS’ mode. In this mode, the most significant features
are displayed for each class. For more information about this mode see Section 15.2.1.
Two numbers are specified; the number of positively weighted features to display and
the number of negatively weighted features to display. It has the following form in the
configuration file;
<DISPLAY-NLPFEATURES-LINEARSVM numP=”X” numN=”Y”/>
where X and Y represent the numbers of positively and negatively weighted features to display, respectively. The default values of X and Y are 10 and 0. - ACTIVELEARNING specifies the settings for active learning. Active learning ranks
documents based on the average of a sample of ML annotation confidence scores. A
larger sample gives a more accurate ranking but takes longer to calculate. The option
has the following form:
<ACTIVELEARNING numExamplesPerDoc=’X’/>
where X represents the number of examples per document used to obtain the confidence score with respect to the learned model. The default value of numExamplesPerDoc is 3.
The ENGINE Element The ENGINE element specifies which ML algorithm will be used, and also allows the options to be set for that algorithm.
For SVM learning, the user can choose one of two learning engines. We will discuss the two SVM learning engines below. Note that only linear and polynomial kernels are supported. This is despite the fact that the original SVM packages implemented other types of kernel. Linear and polynomial kernels are popular in natural language learning, and other types of kernel are rarely used. However, if you want to experiment with other types of kernel, you can do so by first running the Batch Learning PR in GATE to produce the training and testing data, then using the data with the SVM implementation outside of GATE.
The configuration files in the test directory (i.e. plugins/learning/test/ under the main gate directory) contain examples for setting the learning engine.
The ENGINE element in the configuration file is specified as follows:
<ENGINE nickname=’X’ implementationName=’Y’ options=’Z’/>
It has three items:
- nickname can be the name of the learning algorithm or whatever the user wants it to be.
- implementationName refers to the implementation of the particular learning
algorithm that the user wants to use. Its value should be one of the following:
- SVMLibSvmJava, the binary classification SVM algorithm implemented in the Java version of the SVM package LibSVM.
- SVMExec, a binary SVM implementation of your choice, potentially in a language other than Java, run as a separate process outside of GATE. Currently it can use the SV Mlight SVM package2; see the XML file in the GATE distribution (at gate/plugins/learning/test/chunklearning/engines-svm-svmlight.xml) for an example of how to specify the learning engine to be used. The learning engines SVMExec and SVMLibSvmJava should produce the same results in theory but may get slightly different results in practice due to implementational differences. SVMLibSvmJava tends to be faster than SVMExec for smaller training sets. There may be cases where it is an advantage to run SVM as a separate process however, in which case, SVMExec would be preferable.
- PAUM, the Perceptron with uneven margins, a simple and fast classification learning algorithm. (For details about the learning algorithm PAUM, see [Li et al. 02]).
- PAUMExec, a binary PAUM implementation of your choice, potentially in a language other than Java, run as a separate process outside of GATE. The relationship between the PAUM and PAUMExec is similar to that of SVMLibSvmJava and SVMExec. You may download and use an implementation in C from http://www.dcs.shef.ac.uk/~yaoyong/paum/paum-learning.zip. See the XML file in the GATE distribution (at gate/plugins/learning/test/chunklearning/engines-paum-exec.xml) for an example of how to specify the learning engine to be used.
- NaiveBayesWeka, the Naive Bayes learning algorithm implemented in Weka.
- KNNWeka, the K nearest neighbour (KNN) algorithm implemented in Weka.
- C4.5Weka, the decision tree algorithm C4.5 implemented in Weka.
- Options: the value of this item, which is dependent on the particular learning algorithm, will
be passed verbatim to the ML engine used. Where an option is absent, defaults for that
engine will be used.
- The options for SVMLibSvmJava are similar to those for LibSVM but with
the exception that since SVMLibSvmJava implements the uneven margins SVM
algorithms described in [Li & Shawe-Taylor 03], it takes the uneven margins
parameter as an option. SVMLibSvmJava options are as follows:
- -s svm_type; whether the SVM should be binary or multiclass. Default value is 0. Since only binary is supported, the option should be set to 0 or excluded.
- -t kernel_type; 0 for a linear kernel or 1 for a polynomial kernel. Default value is 0. Note that the current implementation does not support other kernel types such as radial and sigmoid function.
- -d degree; the degree in polynomial kernel, e.g. 2 for quadratic kernel. Default value is 3.
- -c cost; the cost parameter C in the SVM. Default value is 1. This parameter determines the cost associated with allowing training errors (‘soft margins’). Allowing some points to be misclassified by the SVM may produce a more generalizable result.
- -m cachesize; the cache memory size in MB (default 100).
- -tau value; setting the value of uneven margins parameter of the SVM. τ = 1 corresponds to the standard SVM. If the training data has just a small number of positive examples and a large number of negative examples, setting the parameter τ to a value less than 1 (e.g. τ = 0.4) often results in better F-measure than the standard SVM (see [Li & Shawe-Taylor 03]).
- The options for SVMExec, using SV Mlight, are similar to those for using SV Mlight directly for training. Options set the type of kernel, the parameters in the kernel function, the cost parameter, the memory used, etc. The parameter tau is also included, to set the uneven margins parameter, as explained above. The last two terms in the parameter options are the training data file and the model file. An example of the options for SVMExec might be ‘-c 0.7 -t 0 -m 100 -v 0 -tau 0.6 /yaoyong/software/svm-light/data_svm.dat /yaoyong/software/svm-light/model_svm.dat’, meaning that the learner uses a linear kernel, the uneven margins parameter is set as 0.6, and two data files /yaoyong/software/svm-light/data_svm.dat and /yaoyong/software/svm-light/model_svm.dat for writing and reading data. Note that both the data files specified here are temporary files, which are used only by the svm-light training program, can be in anywhere in your computer, and are independent of the data files produced by the GATE learning plugin. SVMExec also takes a further argument, executableTraining, which specifies the SVM learning program svm_learn.exe in the SV Mlight. For example, executableTraining=‘/yaoyong/software/svm-light/svm_learn.exe’ specifies one particular svm_learn.exe obtained from the package SV Mlight.
- The PAUM engine has three options; ‘-p’ for the positive margin, ‘-n’ fo the negative margin, and ‘-optB’ for the modification of the bias term. For example, options=‘-p 50 -n 5 -optB 0.3’ means τ+ = 50, τ- = 5 and b = b + 0.3 in the PAUM algorithm.
- The KNN algorithm has one option; the number of neighbours used. It is set via ‘-k X’. The default value is 1.
- There are no options for Naive Bayes and C4.5 algorithms.
- The options for SVMLibSvmJava are similar to those for LibSVM but with
the exception that since SVMLibSvmJava implements the uneven margins SVM
algorithms described in [Li & Shawe-Taylor 03], it takes the uneven margins
parameter as an option. SVMLibSvmJava options are as follows:
The DATASET Element The DATASET element defines the type of annotation to be used as training instance and the set of attributes that characterise the instances. The INSTANCE-TYPE sub-element is used to select the annotation type to be used for instances. There will be one training instance for every one of the instance annotations in the corpus. For example, if INSTANCE-TYPE has ‘Token’ as its value, there will be one training instance in the document per token. This also means that the positions (see below) are defined in relation to tokens. INSTANCE-TYPE can be seen as the basic unit to be taken into account for machine learning. The attributes of the instance are defined by a sequence of ATTRIBUTE, ATTRIBUTE_REL or ATTRIBUTELIST elements.
Different NLP learning tasks may have different instance types and use different kinds of attribute elements. Chunking recognition often uses the token as instance type and the linguistic features of ‘Token’ and other annotations as features. Text classification’s instance type is the text unit for classification, e.g. the whole document, or sentence, or token. If classifying for example a sentence, n-grams (see below) are often a good feature representation for many statistical learning algorithms. For relation extraction, the instance type is a pair of terms that may be related, and the features come from not only the linguistic features of each of the two terms but also those related to both terms taken together.
The DATASET element should define an INSTANCE-TYPE sub-element, it should define an ATTRIBUTE sub-element or an ATTRIBUTE_REL sub-element as class, and it should define some linguistic feature related sub-elements (‘linguistic feature’ or ‘NLP feature’ is used here to distinguish features or attributes used for machine learning from features in the sense of a feature of a GATE annotation). All the annotation types involved in the dataset definition should be in the same annotation set. Each of the sub-elements defining the linguistic features (attributes) should contain an element defining the annotation TYPE to be used and an element defining the FEATURE of the annotation type to use. For instance, TYPE might be ‘Person’ and FEATURE might be ‘gender’. For an ATTRIBUTE sub-element, if you do not specify FEATURE, the entire sub-element will be ignored. Therefore, if an annotation type you want to use does not have any annotation features, you should add an annotation feature to it and assign the same value to the feature for all annotations of that type. Note that if blank spaces are contained in the values of the annotation features, they will be replaced by the character ‘_’ in each occurrence. So it is advisable that the values of the annotation features used, in particular for the class label, do not contain any blank space.
Below, we explain all the sub-elements one by one. Please also refer to the example configuration files presented in next section. Note that each sub-element should have a unique name, if it requires a name, unless we explicitly state otherwise.
- The INSTANCE-TYPE sub-element is
defined as <INSTANCE-TYPE>X</INSTANCE-TYPE> where X is the annotation
type used as instance unit for learning, for example ‘Token’. For relation extraction,
the user should also specify the two arguments of the relation, as so:
<INSTANCE-ARG1>A</INSTANCE-ARG1>
<INSTANCE-ARG2>B</INSTANCE-ARG2>
The values of A and B should be identifiers for the first and second terms of the relation, respectively. These names will be used later in the configuration file. An example can be found at /gate/plugins/learning/test/relation-learning/engines-svm.xml. - An ATTRIBUTE element has the following sub-elements:
- NAME; the name of the attribute. Its value should not end with ‘gram’, since this is reserved for n-gram features as mentioned below. This attribute name will appear in output files, so it is useful to give a descriptive name.
- SEMTYPE; type of the attribute value. It can be ‘NOMINAL’ or ‘NUMERIC’. Currently only nominal is supported.
- TYPE; the annotation type used to extract the attribute.
- FEATURE; the value of the attribute will be the value of the named feature on the annotation of the specified type.
- POSITION; the position of the instance annotation to be used for extracting the feature relative to the current instance annotation. 0 refers to the current instance annotation, -1 refers to the preceding instance annotation, 1 refers to the following one and so forth. Recall that we defined INSTANCE-TYPE at the start of the DATASET element. This type might for example be ‘Token’. In the current ATTRIBUTE element we are defining an annotation type to use to get the feature from, separate and possibly different from the INSTANCE-TYPE. For example, we might be interested in the ‘majorType’ of a ‘Lookup’. By specifying -1, we would be saying, move to the preceding ‘Token’ and then try to extract the ‘majorType’ of the ‘Lookup’ on that token. The default value of the parameter is 0. Note that if our INSTANCE-TYPE were to be for example a named entity annotation comprising multiple tokens, and we wanted to extract a feature on the ‘Token’ annotation, then all the tokens within it would be considered to be in the zero position relative to the current instance annotation, and the current implementation would simply pick the first. (Useful in this case might be the NGRAM attribute type, described later, which can be used to extract features for each member of a multi-token annotation.) In the current implementation, features are weighted according to their distance from the current instance annotation. In other words, features which are further removed from the current instance annotation are given reduced importance. The component value in the feature vector for one attribute feature is 1 if the attribute’s position p is 0. Otherwise its value is 1.0∕|p|.
- <CLASS/>: an empty element used to mark the class attribute. There can only be one attribute marked as class in a dataset definition. The attribute, as described above, has specified TYPE and FEATURE; the features of the type are the class labels. Since only one attribute can be marked as class, it may be necessary to preprocess your data to put all class labels into a feature of one type of annotation, e.g. you might create a ‘Mention’ annotation, with the feature ‘Class’, which is set to the class name.
- The ATTRIBUTELIST element is similar to ATTRIBUTE except that it has no POSITION sub-element but instead a RANGE element. This will be converted into several attributes with position ranging from the value of ‘from’ to the value of ‘to’. It defines a ‘context window’ containing several consecutive examples. The ATTRIBUTELIST should be preferred when defining a context window for features, because not only it can avoid the duplication of ATTRIBUTE elements, but also because processing is speeded up (see the discussion for the element WINDOWSIZE below).
- The WINDOWSIZE element specifies the size of the context window. This will override
the context window size defined in every ATTRIBUTELIST. If the WINDOWSIZE element
is not present in the configuration file, the window size defined in each element
ATTRIBUTELIST will be used; otherwise, the window size specified by this element will be
used for each ATTRIBUTELIST if it contains one ATTRIBUTE at position 0 (otherwise the
ATTRIBUTELIST will be ignored). This element can be used for speeding up the process of
extracting the feature vectors from the documents. The element has two features
specifying the length of left and right sides of context window. It has the following
form:
<WINDOWSIZE windowSizeLeft=”X” windowSizeRight=”Y”/>
where X and Y represent the the length of left and right sides of context window, respectively. For example, if X = 2 and Y = 1, then the context window will be from the position -2 to 1 ( e.g. from the second token in the left through the current token to the first token in the right). - An NGRAM feature is used for characterising an instance annotation in terms of
constituent sequences of subsumed feature annotations. It is essentially a reversal
of the ATTRIBUTELIST principle; where ATTRIBUTELIST uses a sequence
surrounding an instance in order to classify the instance, NGRAM uses sequences within
the instance as features. It simply creates a series of attributes that constitute a
sliding window across the entire of the current instance annotation. For example,
INSTANCE-TYPE might be sentences, in sentence classification, and the NGRAM
attribute specification could be used for example to create a series of unigram features
for the sentence, effectively a ‘bag of words’ representation. Conventionally, one
would use the string of the token, or perhaps its lemma, as the feature for the
NGRAM; however, it is possible to specify multiple features of choice, as shown
below.
- NAME; name of the n-gram. Its value should end with ‘gram’.
- NUMBER; the ‘n’ of the n-gram, with value 1 for unigram, and 2 for bigram, etc.
- CONSNUM; several features can be used to generate n-grams. For example, n-grams of token strings could be used as well as n-grams of lemmas. Where CONSNUM is ‘k’, the NGRAM element should have ‘k’ CONS-X sub-elements, where X= 1, ..., k. Each CONS-X element has one TYPE sub-element and one FEATURE sub-element, which define feature to be used for that term to create n-grams.
- The WEIGHT sub-element specifies a weight for the n-gram feature. The n-gram part of the feature vector for one instance is normalised, thus having a default value of 1.0. If the user wants to adjust the contributions of the n-gram to the whole feature vector, s/he can do so by setting the WEIGHT parameter. For example, if the user is doing sentence classification and s/he uses two features; the unigram of tokens in a sentence and the length of the sentence, by default the entire of the NGRAM attribute specification is given only the same importance as the sentence length feature. In order to experiment with increasing the importance of the n-gram element, the user can set the weight sub-element of the n-gram element with a number bigger than 1.0 (like 10.0). Then every component of the n-gram part of the feature vector would be multiplied by the parameter.
- The ValueTypeNgram element specifies the type of value used in the n-gram. Currently it
can take one of the three types; ‘binary, tf, and tf-idf, which are explained in Section 15.2.4.
The value is specified by the X in
<ValueTypeNgram>X</ValueTypeNgram>
X = 1 for binary, = 2 for tf, and = 3 for tf-idf. The default value is 3. - The FEATURES-ARG1 element defines the features related to the first argument of the relation for relation learning. It should include one ARG sub-element referring to the GATE annotation of the argument (see below for a detailed explanation). It may include other sub-elements, such as ATTRIBUTE, ATTRIBUTELIST and/or NGRAM, to define the linguistic features related to the argument. Features pertaining particularly to one or the other argument of a relation should be defined in FEATURES-ARG1 or FEATURES-ARG2 as appropriate. Features relating to both arguments should be defined using an ATTRIBUTE_REL.
- The FEATURES-ARG2 element defines the features related to the second argument of relation. Like the element FEATURES-ARG1, it should include one ARG sub-element. It may also include other sub-elements. The ARG sub-element in the FEATURES-ARG2 should have a unique name which is different from the name for the ARG sub-element in the FEATURES-ARG1. However, other sub-elements may have the same name as corresponding ones in the FEATURES-ARG1, if they refer to the same annotation type and feature in the text.
- The ARG element is used in both FEATURES-ARG1 and FEATURES-ARG2. It specifies
the annotation corresponding to one argument of a relation. It has four sub-elements, as
follows;
- NAME; a unique name for the argument (e.g. ‘ARG1’).
- SEMTYPE; the type of the arg value. This can be ‘NOMINAL’ or ‘NUMERIC’. Currently only nominal is implemented.
- TYPE; the annotation type for the argument.
- FEATURE; the value of the named feature on the annotation of specified type is the identifier of the argument. Only if the value of the feature is same as the value of the feature specified in the sub-element <INSTANCE-ARG1>A</INSTANCE-ARG1> (or <INSTANCE-ARG2>B</INSTANCE-ARG2>), the argument is regarded as one argument of the relation instance considered.
- ATTRIBUTE_REL element is similar to the ATTRIBUTE element. However, it does not have the POSITION sub-element, and it has two other sub-elements, ARG1 and ARG2, relating to the two argument features of the (relation) instance type. In other words, if and only if the value X in the sub-element <ARG1>X</ARG1> is same as the value A in the first argument instance <INSTANCE-ARG1>A</INSTANCE-ARG1> and the value Y in the sub-element <ARG2>Y</ARG2> is same as the value B in the second argument instance <INSTANCE-ARG2>B</INSTANCE-ARG2> is the feature defined in this ATTRIBUTE_REL sub-element assigned to the instance considered. For relation learning, an ATTRIBUTE_REL is denoted as the class attribute by including <CLASS/>.
15.2.2 Case Studies for the Three Learning Types [#]
The following are three illustrated examples of configuration files for information extraction, sentence classification and relation extraction. Note that the configuration file is in the XML format, and should be stored in a file with the ‘.xml’ extension.
Information Extraction [#]
The first example is for information extraction. The corpus is prepared with annotations providing class information as well as the features to be used. Class information is provided in the form of a single annotation type, ‘Mention’, which contains a feature ‘class’. Within the class feature is the name of the class of the textual chunk. Other annotations in the dataset include ‘Token’ and ‘Lookup’ annotations as provided by ANNIE. All of these annotations are in the same annotation set, the name of which will be passed as a runtime parameter.
The configuration file is given below. The optional settings are in the first part. It first specifies surround mode as ‘true’; we will find the chunks that correspond to our entities by using machine learning to locate the start and end of the chunks. Then it specifies the filtering settings. Since we are going to use SVM in this problem, we can filter our data to remove some of the negative instances that can cause problems if they are too dominant. The ratio’s value is ‘0.1’ and the dis’s value is ‘near’, meaning that an initial SVM learning step will be executed and the 10% of negative examples which are closest to the learned SVM hyper-plane will be removed in the filtering stage, before the final learning is executed. The threshold probabilities for the boundary tokens and information entity are set as ‘0.4’ and ‘0.2’, respectively; boundary tokens found with a lower confidence than the threshold will be rejected. The threshold probability for classification is also set as ‘0.5’; this, however, will not be used in this case since we are doing chunk learning with surround mode set as ‘true’. The parameter will be ignored. multiClassification2Binary is set as ‘one-vs-others’, meaning that the ML API will convert the multi-class classification problem into a series of binary classification problems using the one against others approach. In evaluation mode, ‘2-fold’ cross-validation will be used, dividing the corpus into two equal parts and running two training/test cycles with each part as the training data.
The second part is the sub-element ENGINE, specifying the learning algorithm. The PR will use the LibSVM SVM implementation. The options determine that it will use the linear kernel with the cost C as 0.7 and the cache memory as 100M. Additionally it will use uneven margins, with τ as 0.4.
The last part is the DATASET sub-element, defining the linguistic features used. It first specifies the ‘Token’ annotation as instance type. The first ATTRIBUTELIST allows the token’s string as a feature of an instance. The range from ‘-5’ to ‘5’ means that the strings of the current token instance as well as its five preceding tokens and its five ensuing tokens will be used as features for the current token instance. The next two attribute lists define features based on the tokens’ capitalisation information and types. The ATTRIBUTELIST named ‘Gaz’ uses as attributes the values of the feature ‘majorType’ of the annotation type ‘Lookup’. The final ATTRIBUTE feature defines the class attribute; it has the sub-element <CLASS/>. The values of the feature ‘class’ of the annotation type ‘Mention’ are the class labels.
<ML-CONFIG>
<SURROUND value="true"/>
<FILTERING ratio="0.1" dis="near"/>
<PARAMETER name="thresholdProbabilityEntity" value="0.2"/>
<PARAMETER name="thresholdProbabilityBoundary" value="0.4"/>
<PARAMETER name="thresholdProbabilityClassification" value="0.5"/>
<multiClassification2Binary method="one-vs-others"/>
<EVALUATION method="kfold" runs="2"/>
<ENGINE nickname="SVM" implementationName="SVMLibSvmJava"
options=" -c 0.7 -t 0 -m 100 -tau 0.4 "/>
<DATASET>
<INSTANCE-TYPE>Token</INSTANCE-TYPE>
<ATTRIBUTELIST>
<NAME>Form</NAME>
<SEMTYPE>NOMINAL</SEMTYPE>
<TYPE>Token</TYPE>
<FEATURE>string</FEATURE>
<RANGE from="-5" to="5"/>
</ATTRIBUTELIST>
<ATTRIBUTELIST>
<NAME>Orthography</NAME>
<SEMTYPE>NOMINAL</SEMTYPE>
<TYPE>Token</TYPE>
<FEATURE>orth</FEATURE>
<RANGE from="-5" to="5"/>
</ATTRIBUTELIST>
<ATTRIBUTELIST>
<NAME>Tokenkind</NAME>
<SEMTYPE>NOMINAL</SEMTYPE>
<TYPE>Token</TYPE>
<FEATURE>kind</FEATURE>
<RANGE from="-5" to="5"/>
</ATTRIBUTELIST>
<ATTRIBUTELIST>
<NAME>Gaz</NAME>
<SEMTYPE>NOMINAL</SEMTYPE>
<TYPE>Lookup</TYPE>
<FEATURE>majorType</FEATURE>
<RANGE from="-5" to="5"/>
</ATTRIBUTELIST>
<ATTRIBUTE>
<NAME>Class</NAME>
<SEMTYPE>NOMINAL</SEMTYPE>
<TYPE>Mention</TYPE>
<FEATURE>class</FEATURE>
<POSITION>0</POSITION>
<CLASS/>
</ATTRIBUTE>
</DATASET>
</ML-CONFIG>
Sentence Classification [#]
We will now consider the case of sentence classification. The corpus in this example is annotated with ‘Sentence’ annotations, which contain the feature ‘sent_size’, as well as the class of the sentence. Furthermore, ‘Token’ annotations are applied, having features ‘category’ and ‘root’. As before, all annotations are in the same set, and the annotation set name will be passed to the PR at run time.
Below is an example configuration file. It first specifies surround mode as ‘false’, because it is a text classification problem; we are interested in classifying single instances rather than chunks of instances. Our targets of interest, sentences, have already been found (unlike in the information extraction example, where identifying the limits of the entity was part of the problem). The next two options allow the label list and the NLP feature list to be updated from the training data when retraining. It also specifies probability thresholds for entity and entity boundary. Note that these two specifications will not be used in this case. However, their presence is not problematic; they will simply be ignored. The probability threshold for classification is set as ‘0.5’. This will be used to decide which classifications to accept and which to reject as being too unlikely. (Altering this parameter can trade off precision against recall and vice versa.) The evaluation will use the hold-out test method. It will randomly select 66% of the documents from the corpus for training, and the other 34% documents will be used for testing. It will run the evaluation twice, and average the results over the two runs. Note that it does not specify the method of converting a multi-class classification problem into several binary class problem, meaning that it will adopt the default (namely one against all others).
The configuration file specifies KNN (K-Nearest Neighbour) as the learning algorithm. It also specifies the number of neighbours used as 5. Of course other learning algorithms can be used as well. For example, the ENGINE element in the previous example, which specifies SVM as learning algorithm, can be put into this configuration file to replace the current one.
In the DATASET element, the annotation ‘Sentence’ is used as instance type. Two kinds of linguistic features are defined; one is NGRAM and the other is ATTRIBUTE. The n-gram is based on the annotation ‘Token’. It is a unigram, as its NUMBER element has the value 1. This means that a ‘bag of words’ feature will be formed from the tokens comprising the sentence. It is based on the two features, ‘root’ and ‘category’, of the annotation ‘Token’. This introduces a new aspect to the n-gram. The n-gram feature comprises counts of the unigrams appearing in the sentence. For example, if the sentence were ‘the man walked the dog”, the unigram feature would contain the information that ‘the’ appeared twice, and ‘man’, ‘walked’ and ‘dog’ appeared once. However, since our n-gram has two features, ‘root’ and ‘category’, two tokens will be considered the same term if and only if they have the same ‘root’ feature and the same ‘category’ feature. The weight of the ngram is set as 10.0, meaning its contribution is ten times that of the contribution of the other feature, the sentence length. The feature ‘sent_size’ of the annotation ‘Sentence’ is given as an ATTRIBUTE feature. Finally the values of the feature ‘class’ of the annotation ‘Sentence’ are nominated as the class labels.
<ML-CONFIG>
<SURROUND value="false"/>
<IS-LABEL-UPDATABLE value="true"/>
<IS-NLPFEATURELIST-UPDATABLE value="true"/>
<PARAMETER name="thresholdProbabilityEntity" value="0.2"/>
<PARAMETER name="thresholdProbabilityBoundary" value="0.42"/>
<PARAMETER name="thresholdProbabilityClassification" value="0.5"/>
<EVALUATION method="holdout" runs="2" ratio="0.66"/>
<ENGINE nickname="KNN" implementationName="KNNWeka" options = " -k 5 "/>
<DATASET>
<INSTANCE-TYPE>Sentence</INSTANCE-TYPE>
<NGRAM>
<NAME>Sent1gram</NAME>
<NUMBER>1</NUMBER>
<CONSNUM>2</CONSNUM>
<CONS-1>
<TYPE>Token</TYPE>
<FEATURE>root</FEATURE>
</CONS-1>
<CONS-2>
<TYPE>Token</TYPE>
<FEATURE>category</FEATURE>
</CONS-2>
<WEIGHT>10.0</WEIGHT>
</NGRAM>
<ATTRIBUTE>
<NAME>Class</NAME>
<SEMTYPE>NOMINAL</SEMTYPE>
<TYPE>Sentence</TYPE>
<FEATURE>sent_size</FEATURE>
<POSITION>0</POSITION>
</ATTRIBUTE>
<ATTRIBUTE>
<NAME>Class</NAME>
<SEMTYPE>NOMINAL</SEMTYPE>
<TYPE>Sentence</TYPE>
<FEATURE>class</FEATURE>
<POSITION>0</POSITION>
<CLASS/>
</ATTRIBUTE>
</DATASET>
</ML-CONFIG>
Relation Extraction [#]
The last example is for relation extraction. The relation extraction support in the PR is based on the work described in [Wang et al. 06].
Two concepts are key in a relation extraction corpus. Entities are the things that may be related, and relations describe the relationship between the entities if any. In our example, entities are pre-identified, and the task is to identify the relationships between them. The corpus for this example is annotated with the following:
- ‘ACEEntity’ annotations indicate the entities of interest in the corpus.
- ‘RE_INS’ annotations form the instances, and there is an instance for every pair of ‘ACEEntities’ within a sentence. ‘RE_INS’ annotations span the entire of the text between and including their ‘ACEEntity’ annotations. For example, ‘the commander of Israeli troops’ might be a potential relationship between a person, ‘the commander’, and an entity, ‘Israeli troops’. Its ‘RE_INS’ annotation covers the entire of this text. It contains ‘arg1’ and ‘arg2’ features containing the numerical identifiers of the two ‘ACEEntities’ to which it pertains. These numerical identifiers match the ‘MENTION_ID’ feature of the ‘ACEEntity’ annotation.
- ‘ACERelation’ annotations indicate the relations we wish to learn, and also span the entire of the text involved in the relationship. They include the features ‘MENTION_ARG1’ and ‘MENTION_ARG2’, which, again, contain the numerical identifier found in the ‘MENTION_ID’ feature of the ‘ACEEntity’ annotations, as well as ‘Relation_type’, indicating the type of the relation.
- Various ANNIE-style annotations are also included.
Our task is to select the ‘RE_INS’ instances that match the ‘ACERelations’. You will see that throughout the configuration file, annotation types are specified in conjunction with argument identifiers. This is because we need to ensure that the annotation in question pertains to the right entities. Therefore, argument identifiers are used to constrain the match.
The configuration file does not specify any optional settings, meaning that it uses all the default values for those settings (see Section 15.2.1 for the default values of all possible settings).
- it sets the surround mode as ‘false’;
- both the label list and NLP feature list are updatable;
- the probability threshold for classification is set as 0.5;
- it uses ‘one against others’ for converting multi-class problem into binary class problems for SVM learning;
- for evaluation it uses hold-out testing with a ratio of 0.66 and only one run.
The configuration file specifies the learning algorithm as the Naive Bayes method implemented in Weka. However, other learning algorithms could equally well be used.
We begin by defining ‘RE_INS’ as the instance type. Next, we provide the numeric identifiers of each argument of the relationship by specifying elements INSTANCE-ARG1 and INSTANCE-ARG2 as the feature names ‘arg1’ and ‘arg2’ respectively. This indicates that the argument identifiers of the instances can be found in the ‘arg1’ and ‘arg2’ features of the ‘RE_INS’ annotations.
Attributes might pertain to the entire relation or they might pertain to one or other argument within the relation. We are going to begin by defining the features specific to each argument of the relation. Recall that our ‘RE_INS’ annotations have as arguments two ‘ACEEntity’ annotations, and that these are identified by their ‘MENTION_ID’ being the same as the ‘arg1’ or ‘arg2’ features of the ‘RE_INS’. It is from these ‘ACEEntity’ annotations that we wish to obtain argument-specific features. FEATURES-ARG1 and FEATURES-ARG1 elements begin by specifying which annotation we are referring to. We use the ARG element to explain this. We are interested in annotations of type ‘ACEEntity’, and their ‘MENTION_ID’ must match ‘arg1’ or ‘arg2’ of ‘RE_INS’ as appropriate. Having identified precisely which ‘ACEEntity’ we are interested in we can go on to give argument-specific features; in this case, unigrams of the ‘Token’ feature ‘string’.
We now wish to define features pertaining to the entire relation. We indicate that the ‘t12’ feature of ‘RE_INS’ annotations is to be used (this feature contains type information derived from ‘ACEEntity’). Again, rather than just specifying the ‘RE_INS’ annotation, we also indicate that the ‘arg1’ and ‘arg2’ feature values must match the argument identifiers of the instance, as defined in the INSTANCE-ARG1 and INSTANCE-ARG2 elements at the beginning. This ensures that we are taking our features from the correct annotation.
Finally, we define the class attribute. We indicate that the class attribute is contained in the ‘Relation_type’ feature of the ‘ACERelation’ annotation. The ‘ACERelation’ annotation type has features ‘MENTION_ARG1’ and ‘MENTION_ARG1’, indicating its arguments. Again, we use the elements ARG1 and ARG2 to indicate that it is these features that must be matched to the arguments of the instance if that instance is to be considered a positive example of the class.
<ML-CONFIG>
<ENGINE nickname="NB" implementationName="NaiveBayesWeka"/>
<DATASET>
<INSTANCE-TYPE>RE_INS</INSTANCE-TYPE>
<INSTANCE-ARG1>arg1</INSTANCE-ARG1>
<INSTANCE-ARG2>arg2</INSTANCE-ARG2>
<FEATURES-ARG1>
<ARG>
<NAME>ARG1</NAME>
<SEMTYPE>NOMINAL</SEMTYPE>
<TYPE>ACEEntity</TYPE>
<FEATURE>MENTION_ID</FEATURE>
</ARG>
<ATTRIBUTE>
<NAME>Form</NAME>
<SEMTYPE>NOMINAL</SEMTYPE>
<TYPE>Token</TYPE>
<FEATURE>string</FEATURE>
<POSITION>0</POSITION>
</ATTRIBUTE>
</FEATURES-ARG1>
<FEATURES-ARG2>
<ARG>
<NAME>ARG2</NAME>
<SEMTYPE>NOMINAL</SEMTYPE>
<TYPE>ACEEntity</TYPE>
<FEATURE>MENTION_ID</FEATURE>
</ARG>
<ATTRIBUTE>
<NAME>Form</NAME>
<SEMTYPE>NOMINAL</SEMTYPE>
<TYPE>Token</TYPE>
<FEATURE>string</FEATURE>
<POSITION>0</POSITION>
</ATTRIBUTE>
</FEATURES-ARG2>
<ATTRIBUTE_REL>
<NAME>EntityCom1</NAME>
<SEMTYPE>NOMINAL</SEMTYPE>
<TYPE>RE_INS</TYPE>
<ARG1>arg1</ARG1>
<ARG2>arg2</ARG2>
<FEATURE>t12</FEATURE>
</ATTRIBUTE_REL>
<ATTRIBUTE_REL>
<NAME>Class</NAME>
<SEMTYPE>NOMINAL</SEMTYPE>
<TYPE>ACERelation</TYPE>
<ARG1>MENTION_ARG1</ARG1>
<ARG2>MENTION_ARG2</ARG2>
<FEATURE>Relation_type</FEATURE>
<CLASS/>
</ATTRIBUTE_REL>
</DATASET>
</ML-CONFIG>
15.2.3 How to Use the Batch Learning PR in GATE Developer [#]
The Batch Learning PR implements the procedure of using supervised machine learning for NLP, which generally has two steps; training and application. The training step learns models from labelled data. The application step applies the learned models to the unlabelled data in order to add labels. Therefore, in order to use supervised ML for NLP, one should have some labelled data, which can be obtained either by manually annotating documents or from other resources. One also needs to determine which linguistic features are to be used in training. (The same features should be used in the application as well.) In this implementation, all machine learning attributes are GATE annotation features. Finally, one should determine which learning algorithm will be used.
Based on the general procedure outlined above, we explain how to use the Batch Learning PR step by step below:
- Annotate some documents with labels that you want to learn. The labels should be represented by the values of a feature of a GATE annotation type (not the annotation type itself).
- Determine the linguistic features that you want the PR to use for learning.
- Annotate the documents (training and application) with the desired features. ANNIE can be useful in this regard. Other PRs such as GATE morphological analyser and the parsers may produce useful features as well. You may need to write some JAPE scripts to produce the features you want.
- Create an XML configuration file for your learning problem. The file should contain one DATASET element specifying the NLP features used, one ENGINE element specifying the learning algorithm, and some optional settings as necessary. (Tip: it may be easier to copy one of the configuration files presented above and modify it for your problem than to write a configuration file from scratch.)
- Load the training documents containing the required annotations representing the linguistic features and the class label, and put them into a corpus. All linguistic features and the class feature should be in the same annotation set. (The Annotation Set Transfer PR in the ‘Tools’ plugin can be useful here.)
- Load the Batch Learning PR into GATE Developer. First you need load the plugin named ‘learning’ using the tool Manage CREOLE Plugins. Then you can create a new ‘Batch Learning PR’. You will need to provide the configuration file as an initialization parameter. After that you can put the PR into a Corpus Pipeline application to use it. Add the corpus containing the training documents to the application too. Set the inputASName to the annotation set containing the annotations for linguistic features and class labels.
- Set the run-time parameter learningMode to ‘TRAINING’ to learn a model from the training data, or set learningMode to ‘EVALUATION’ to do evaluation on the training data and get figures indicating the success of the learning. When using evaluation mode, make sure that the outputASName is the same as the inputASName. (Tip: it may save time if you first try evaluation mode on a small number of documents to make sure that the ML PR works well on your problem and outputs reasonable results before training on the large data.)
- If you want to apply the learned model to new documents, load those new documents into GATE and pre-process them in the same way as the training documents, to ensure that the same features are present. (Class labels need not be present, of course.) Then set learningMode to ‘APPLICATION’ and run the PR on this corpus. The application results, namely the new annotations containing the class labels, will be added into the annotation set specified by the outputASName.
- If you just want the feature files produced by the system and do not want to do any learning or application, select the learning mode ‘ProduceFeatureFilesOnly’.
15.2.4 Output of the Batch Learning PR [#]
The Batch Learning PR outputs several different kinds of information. Firstly, it outputs information about the learning settings. This information will be printed in the Messages Window of the GATE Developer (or standard out if using GATE Embedded) and also into the log file ‘logFileForNLPLearning.save’. The amount of information displayed can be determined via the VERBOSITY parameter in the configuration file. The main output of the learning system is different for different usage modes. In training mode the system produces the learned models. In application mode it annotates the documents using the learned models. In evaluation mode it displays the evaluation results. Finally, in ‘ProduceFeatureFilesOnly’ mode, it produces feature files for the current corpus. Below, we explain the outputs for different learning modes.
Note that all the files produced by the Batch Learning PR, including the log file, are placed in the sub-directory ‘savedFiles’ of the ML working directory. The ML working directory is the directory containing the configuration file.
Training results
When the Batch Learning PR is used in training mode, its main output is the learned model, stored in a file named ‘learnedModels.save’. For the SVM algorithm, the learned model file is a text file. For the learning algorithms implemented in Weka, the model file is a binary file. The output also includes the feature files described in Section 15.2.4.
Application Results
The main application result is the annotations added to the documents. Those annotations are the results of applying the ML model to the documents. In the configuration file, the annotation type and feature of the class labels are specified; class labels must be the value of a feature of an annotation type. In application mode, those annotation types are created in the new documents, and the feature specified will hold the class label. An additional feature will also be included on the specified annotation type; ‘prob’ will hold the confidence level for the annotation.
Evaluation Results
The Batch Learning PR outputs the evaluation results for each run and also the averaged results over all runs. For each run, it first prints a message about the names of the documents in training and testing corpora respectively. Then it displays the evaluation results of this run; first the results for each class label and then the micro-averaged results over all labels. For each label, it presents the name of the label, the number of instances belonging to the label in the training data and results on the test data; the numbers of correct, partially correct, spurious and missing instances in the testing data, and the precision, recall and F1, calculated using correct only (strict) and correct plus partial (lenient). The F-measure results are obtained using the AnnotationDiff Tool which is described in Chapter 10. Finally, the system presents the means of the results of all runs for each label and the micro-averaged results.
Feature Files [#]
The Batch Learning PR is able to produce several feature files. These feature files could be used for evaluating learning algorithms not implemented in this plugin. We describe the formats of those feature files below. Note that all the data files described below can be obtained by setting the run time parameter learningMode to ‘ProduceFeatureFilesOnly’, but some may be produced as part of other learning modes.
The NLP feature file, named NLPFeatureData.save, contains the NLP features of the instances defined in the configuration file. Below is an example of the first few lines of an NLP feature file for information extraction:
0 ft-airlines-27-jul-2001.xml 512
1 Number_BB _NA[-1] _Form_Seven _Form_UK[1] _NA[-1] _Ortho_upperInitial
_Ortho_allCaps[1]
1 Country_BB _Form_Seven[-1] _Form_UK _Form_airlines[1] _Ortho_upperInitial[-1]
_Ortho_allCaps _Ortho_lowercase[1]
0 _Form_UK[-1] _Form_airlines _Form_including[1] _Ortho_allCaps[-1]
_Ortho_lowercase _Ortho_lowercase[1]
0 _Form_airlines[-1] _Form_including _Form_British[1] _Ortho_lowercase[-1]
_Ortho_lowercase _Ortho_upperInitial[1]
1 Airline_BB _Form_including[-1] _Form_British _Form_Airways[1]
_Ortho_lowercase[-1] _Ortho_upperInitial _Ortho_upperInitial[1]
1 Airline _Form_British[-1] _Form_Airways _Form_[1], _Ortho_upperInitial[-1]
_Ortho_upperInitial _NA[1]
0 _Form_Airways[-1] _Form_, _Form_Virgin[1] _Ortho_upperInitial[-1] _NA
_Ortho_upperInitial[1]
The first line of the NLP feature file lists the names of all features used. These names are the names the user gave to their features in the configuration file. The number in the parenthesis following a feature name indicates the position of the feature. For example, ‘Form(-1)’ means the Form feature of the token which is immediately before the current token, and ‘Form(0)’ means the Form feature of the current token. The NLP features for all instances are listed for one document before moving on to the next. For each document, the first line shows the index of the document, the document’s name and the number of instances in the document, as shown in the second line above. After that, each line corresponds to an instance in the document, in their order of appearance. The first item on the line is a number n, representing the number of class labels of the instance. Then, the following n items are the labels. If the current instance is the first instance of an entity, its corresponding label has a suffix ‘_BB’. The other items following the label item(s) are the NLP features of the instance, in the order listed in the first line of the file. Each NLP feature contains the feature’s name and value, separated by ‘_’. At the end of one NLP feature, there may be an integer in square brackets, which represents the position of the feature relative to the current instance. If there is no square-bracketed integer at the end of one NLP feature, then the feature is at the position 0.
The Feature vector file has the file name ‘featureVectorsData.save’, and stores the feature vector in sparse format for each instance. The first few lines of the feature vector file corresponding to the NLP feature file shown above are as follows:
1 2 1 2 439:1.0 761:1.0 100300:1.0 100763:1.0
2 2 3 4 300:1.0 763:1.0 50439:1.0 50761:1.0 100440:1.0 100762:1.0
3 0 440:1.0 762:1.0 50300:1.0 50763:1.0 100441:1.0 100762:1.0
4 0 441:1.0 762:1.0 50440:1.0 50762:1.0 100020:1.0 100761:1.0
5 1 5 20:1.0 761:1.0 50441:1.0 50762:1.0 100442:1.0 100761:1.0
6 1 6 442:1.0 761:1.0 50020:1.0 50761:1.0 100066:1.0
7 0 66:1.0 50442:1.0 50761:1.0 100443:1.0 100761:1.0
The feature vectors are also listed for each document in sequence. For each document, the first line shows the index of the document, the number of instances in the document and the document’s name. Each of the following lines is for each of the instances in the document. The first item in the line is the index of the instance in the document. The second item is a number n, representing the number of labels the instance has. The following n items are indices representing the class labels.
For text classification and relation learning, the label’s index comes directly from the label list file, described below. For chunk learning, the label’s index presented in the feature vector file is a bit more complicated. If an instance (e.g. token) is the first one of a chunk with label k, then the instance has as the label’s index 2 *k - 1, as shown in the fifth instance. If it is the last instance of the chunk, it has the label’s index as 2 * k, as shown in the sixth instance. If the instance is both the first one and the last one of the chunk (namely the chunk consists of one instance), it has two label indices, 2 * k - 1 and 2 * k, as shown in the first and second instances.
The items following the label(s) are the non-zero components of the feature vector. Each component is represented by two numbers separated by ‘:’. The first number is the dimension (position) of the component in the feature vector, and the second one is the value of the component.
The Label list file has the name ‘LabelsList.save’, and stores a list of labels and their indices. The following is a part of a label list. Each line shows one label name and its index in the label list.
Bank 13
CalendarMonth 11
CalendarYear 10
Company 6
Continent 8
Country 2
CountryCapital 15
Date 21
DayOfWeek 4
The NLP feature list has the name ‘NLPFeaturesList.save’, and contains a list of NLP features and their indices in the list. The following are the first few lines of an NLP feature list file.
_EntityType_Date 13 1731
_EntityType_Location 170 1081
_EntityType_Money 523 3774
_EntityType_Organization 12 2387
_EntityType_Person 191 421
_EntityType_Unknown 76 218
_Form_’ 112 775
_Form_\$ 527 74
_Form_’ 508 37
_Form_’s 63 731
_Form_( 526 111
The first line of the file shows the number of instances from which the NLP features were collected. The number of instances will be used for computating of the idf (inverse document frequency) in document or sentence classification. The following lines are for the NLP features. Each line is for one unique feature. The first item in the line represents the NLP feature, which is a combination of the feature’s name defined in the configuration file and the value of the feature. The second item is a positive integer representing the index of the feature in the list. The last item is the number of times that the feature occurs, which is needed for computing the idf.
The N-grams (or language model) file has the name ‘NgramList.save’, and can only be produced by setting the learning mode to ‘ProduceFeatureFilesOnly’. In order to produce n-gram data, the user may use a very simple configuration file, i.e. it need only contain the DATASET element, and the data element need contain only an NGRAM element to specify the type of n-gram and the INSTANCE-TYPE element to define the annotation type from which the n-gram data are created (e.g. sentence). The NGRAM element in configuration file specifies what type of n-grams the PR produces (see Section 15.2.1 for the explanation of the n-gram definition). For example, if you specify a bigram based on the string form of ‘Token’, you will obtain a list of bigrams from the corpus you used. The following are the first lines of a bigram list based on the token annotation’s ‘string’ feature, and was calculated over 3 documents.
Aug<>, 3
Female<>; 3
Human<>; 3
2004<>Aug 3
;<>Female 3
.<>The 3
of<>a 3
)<>: 3
,<>and 3
to<>be 3
;<>Human 3
The two terms of the bigram are separated by ‘<>’. The number following one n-gram is the number of occurrences of that n-gram in the corpus. The n-gram list is ordered according to the number of occurrences of the n-gram terms. The most frequent terms in the corpus are therefore at the start of the list.
The n-gram data produced can be based on any features of annotations available in the documents. Hence it can not only produce the conventional n-gram data based on the token’s form or lemma, but also n-grams based on e.g. the token’s POS, or a combination of the token’s POS and form, or any feature of the ‘sentence’ annotation (see Section 15.2.1 for how to define different types of n-gram).
The Document-term matrix file has the name ‘documentByTermMatrix.save’, and can only be produced by setting the learning mode to ‘ProduceFeatureFilesOnly’. The document-term matrix presents the weights of terms appearing in each document (see Section 19.4 for more explanation). Currently three types of weight are implemented; binary, term frequency (tf) and tf-idf. The binary weight is simply 1 if the term appears in document and 0 if it does not. tf (term frequency) refers to the number of occurrences of one term in a document. tf-idf is popular in information retrieval and text mining. It is a multiplication of term frequency and inverse document frequency. Inverse document frequency is calculated as follows:

where |D| is the total number of documents in the corpus, and |{dj : ti ∈ dj}| is the number of documents in which the term ti appears. The type of weight is specified by the sub-element ValueTypeNgram in the DATASET element in configuration file (see Section 15.2.1).
Like the n-gram data, in order to produce the document-term matrix, the user may use a very simple configuration file, i.e. it need only contain the DATASET element, and the data element need only contain two elements; the INSTANCE-TYPE element, to define the annotation type from which the terms are counted, and an NGRAM element to specify the type of n-gram. As mentioned previously, the element ValueTypeNgram specifies the type of value used in the matrix. If it is not present, the default type tf-idf will be used. The conventional document-term matrix can be produced using a unigram based on the token’s form or lemma and the instance type covering the whole document. In other words, INSTANCE-TYPE is set to an annotation type such as for example ‘body’, which covers the entire document, and the n-gram definition then specifies the ‘string’ feature of the ‘Token’ annotation type.
The following was extracted from the beginning of a document-term matrix file, produced using unigrams of the token’s form. It presents a part of the matrix of terms and their term frequency values in the document named ‘27.xml’. Each term and its term frequency are separated by ‘:’. The terms are in alphabetic order.
124:1 2004:1 22:1 29:1 330:1 54:1 8:2 ::5 ;:11 Abstract:1 Adaptation:1
Adult:1 Atopic:2 Attachment:3 Aug:1 Bindungssicherheit:1 Cross-:1
Dermatitis:2 English:1 F-SOZU:1 Female:1 Human:1 In:1 Index:1
Insecure:1 Interpersonal:1 Irrespective:1 It:1 K-:1 Lebensqualitat:1
Life:1 Male:1 NSI:2 Neurodermitis:2 OT:1 Original:1 Patients:1
Psychological:1 Psychologie:1 Psychosomatik:1 Psychotherapie:1
Quality:1 Questionnaire:1 RSQ:1 Relations:1 Relationship:1 SCORAD:1
Scales:1 Sectional:1 Securely:1 Severity:2 Skindex-:1 Social:1
Studies:1 Suffering:1 Support:1 The:1 Title:1 We:3 [:1 ]:1 a:4
absence:1 affection:1 along:2 amount:1 an:1 and:9 as:1 assessed:1
association:2 atopic:5 attached:7
A list of names of documents processed can also be obtained. The file has the name ‘docsName.save’, and only can be produced by setting the learning mode to ‘ProduceFeatureFilesOnly’. It contains the names of all the documents processed. The first line shows the number of documents in the list. Then, each line lists one document’s name. The first lines of an example file are shown below:
ft-bank-of-england-02-aug-2001.xml
ft-airtours-08-aug-2001.xml
ft-airlines-27-jul-2001.xml
A list of names of the selected documents for active learning purposes can also be produced. The file has the name ‘ALSelectedDocs.save’. It is a text file. It is produced in ‘ProduceFeatureFilesOnly’ mode. The file contains the names of documents which have been selected for annotating and training in the active learning process. It is used by the ‘RankingDocsForAL’ learning mode to exclude those selected documents from the ranked documents for active learning purposes. When one or more documents are selected for annotating and training, their names should be put into this file, one line per document.
A list of names of ranked documents for active learning purposes; the file has the name ‘ALRankedDocs.save’, and is produced in ‘RankingDocsForAL’ mode. The file contains the list of names of the documents ranked for active learning, according to their usefulness for learning. Those in the front of the list are the most useful documents for learning. The first line in the file shows the total number of documents in the list. Each of other lines in the file lists one document and the averaged confidence score for classifying the document. An example of the file is shown below:
ft-airlines-27-jul-2001.xml_000201 8.61744
ft-bank-of-england-02-aug-2001.xml_000221 8.672693
ft-airtours-08-aug-2001.xml_000211 9.82562
15.2.5 Using the Batch Learning PR from the API [#]
Using the Batch Learning PR from the API is a simple matter if you have some familiarity with GATE Embedded. Chapter 7 provides a more comprehensive introduction to programming with GATE Embedded, and should be consulted for any general points. There is also a complete example program on the code examples page.
The following snippet shows creating a pipeline application, with a corpus, then creating a batch learning PR and adding it to the application. The location of the configuration file and the mode in which the PR is to be run are added to the PR. The application is then run. ‘corpus’ is a GATE corpus that you have previously set up. (To learn more about creating a corpus from GATE Embedded, see chapter 7 or the example at the code examples page.)
2RunMode mode = RunMode.EVALUATION; //or TRAINING, or APPLICATION ..
3
4//Make a pipeline and add the corpus
5FeatureMap pfm = Factory.newFeatureMap();
6pfm.put("corpus", corpus);
7gate.creole.SerialAnalyserController pipeline =
8 (gate.creole.SerialAnalyserController)
9 gate.Factory.createResource("gate.creole.SerialAnalyserController", pfm);
10
11//Set up the PR and add it to the pipeline.
12//As with using the PR from GATE Developer, it needs a config file
13//and a mode.
14FeatureMap fm = Factory.newFeatureMap();
15fm.put("configFileURL", configFile.toURI().toURL());
16fm.put("learningMode", mode);
17gate.learning.LearningAPIMain learner =
18 (gate.learning.LearningAPIMain)
19 gate.Factory.createResource("gate.learning.LearningAPIMain", fm);
20pipeline.add(learner);
21
22//Run it!
23pipeline.execute();
Having run the PR in EVALUATION mode, you can access the results programmatically:
2System.out.println(
3 ev.macroMeasuresOfResults.precision + "," +
4 ev.macroMeasuresOfResults.recall + "," +
5 ev.macroMeasuresOfResults.f1 + "," +
6 ev.macroMeasuresOfResults.precisionLenient + "," +
7 ev.macroMeasuresOfResults.recallLenient + "," +
8 ev.macroMeasuresOfResults.f1Lenient + "\n");
15.3 Machine Learning PR [#]
The ‘Machine Learning PR’ is GATE’s earlier machine learning PR. It handles both the training and application of ML model on GATE documents. This PR is a Language Analyser so it can be used in all default types of GATE controllers. It can be found in the ‘Machine_Learning’ plugin.
In order to allow for more flexibility, all the configuration parameters for the Machine Learning PR are set through an external XML file and not through the normal PR parameterisation. The root element of the file needs to be called ‘ML-CONFIG’ and it contains two elements: ‘DATASET’ and ‘ENGINE’. An example XML configuration file is given in Section 15.3.6.
15.3.1 The DATASET Element
The DATASET element defines the type of annotation to be used as instance and the set of attributes that characterise all the instances.
An ‘INSTANCE-TYPE’ element is used to select the annotation type to be used for instances, and the attributes are defined by a sequence of ‘ATTRIBUTE’ elements.
For example, if an ‘INSTANCE-TYPE’ has a ‘Token’ for value, there will one instance in the dataset per ‘Token’. This also means that the positions (see below) are defined in relation to Tokens. The ‘INSTANCE-TYPE’ can be seen as the smallest unit to be taken into account for the Machine Learning.
An ATTRIBUTE element has the following sub-elements:
- NAME: the name of the attribute
- TYPE: the annotation type used to extract the attribute.
- FEATURE (optional): if present, the value of the attribute will be the value of the named feature on the annotation of specified type.
- POSITION: the position of the annotation used to extract the feature relative to the current instance annotation.
- VALUES(optional): includes a list of VALUE elements.
- <CLASS/>: an empty element used to mark the class attribute. There can only be one attribute marked as class in a dataset definition.
The VALUES being defined as XML entities, the characters <, > and & must be replaced by <, &rt; and &. It is recommended to write the XML configuration file in UTF-8 in order that uncommon characters are correctly parsed.
Semantically, there are three types of attributes:
- nominal attributes: both type and features are defined and a list of allowed values is provided;
- numeric: both type and features are defined but no list of allowed values is provided; it is assumed that the feature can be converted to a number (a double value).
- boolean: no feature or list of values is provided; the attribute will take one of the ‘true’ or ‘false’ values based on the presence (or absence) of the specified annotation type at the required position.
Figure 15.1 gives some examples of what the values of specified attributes would be in a situation when ‘Token’ annotations are used as instances.
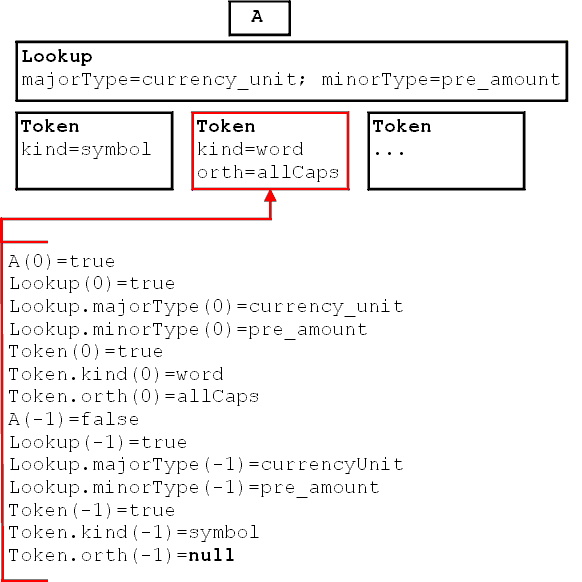
An ATTRIBUTELIST element is similar to ATTRIBUTE except that it has no POSITION sub-element but a RANGE element. This will be converted into several ATTRIBUTELIST with position ranging from the value of the attribute ‘from’ to the value of the attribute ‘to’. This can be used in order to avoid the duplication of ATTRIBUTE elements.
15.3.2 The ENGINE Element
The ENGINE element defines which particular ML implementation will be used, and allows the setting of options for that particular implementation.
The ENGINE element has three sub-elements:
- WRAPPER: defines the class name for the ML implementation (or implementation wrapper). The specified class needs to extend gate.creole.ml.MLEngine.
- BATCH-MODE-CLASSIFICATION: this element is optional. If present (as an empty element <BATCH-MODE-CLASSIFICATION />), the training instances will be passed to the engine in a single batch. If absent, the instances are passed to the engine one at a time. Not every engine supports this option, but for those that do, it can greatly improve performance.
- OPTIONS: the contents of the OPTIONS element will be passed verbatim to the ML engine used.
15.3.3 The WEKA Wrapper
The PR provides a wrapper for the WEKA ML Library (http://www.cs.waikato.ac.nz/ml/weka/) in the form of the gate.creole.ml.weka.Wrapper class.
Options for the WEKA Wrapper
The WEKA wrapper accepts the following options:
- CLASSIFIER: the class name for the classifier to be used.
- CLASSIFIER-OPTIONS: the options string as required for the classifier.
- CONFIDENCE-THRESHOLD: a double value. If the classifier can provide a probability distribution rather than a simple classification then all possible classifications that have a probability value larger or equal to the confidence threshold will be considered.
- DATASET-FILE: location of the weka arff file. This item is not mandatory, it is possible to specify the file using the saving option on the GUI.
Training an ML Model with the WEKA Wrapper
The Machine Learning PR has a Boolean runtime parameter named ”training”. When the value of this parameter is set to true, the PR will collect a dataset of instances from the documents on which it is run. If the classifier used is an updatable classifier then the ML model will be built while collecting the dataset. If the selected classifier is not updatable, then the model will be built the first time a classification is attempted.
Training a model consists of designing a definition file for the ML PR, and creating an application containing a Machine Learning PR. When the application is run over a corpus, the dataset (and the model if possible) is built.
Applying a Learnt Model
Using the same PR, set the ‘training’ parameter to false and run your application.
Depending on the type of the attribute that is marked as class, different actions will be performed when a classification occurs:
- if the attribute is boolean, a new annotation of the specified type will be created with no features;
- if the attribute is nominal or numeric, a new annotation of the specified type will be created with the feature named in the attribute definition having the value predicted by the classifier.
Once a model is learnt, it can be saved and reloaded at a later time. The WEKA wrapper also provides an operation for saving only the dataset in the ARFF format, which can be used for experiments in the WEKA interface. This could be useful for determining the best algorithm to be used and the optimal options for the selected algorithm.
15.3.4 The MAXENT Wrapper [#]
GATE also provides a wrapper for the Open NLP MAXENT library
(http://maxent.sourceforge.net/about.html). The MAXENT library provides an
implementation of the maximum entropy learning algorithm, and can be accessed using the
gate.creole.ml.maxent.MaxentWrapper class.
The MAXENT library requires all attributes except for the class attribute to be boolean, and that the class attribute be boolean or nominal. (It should be noted that, within maximum entropy terminology, the class attribute is called the ‘outcome’.) Because the MAXENT library does not provide a specific format for data sets, there is no facility to save or load data sets separately from the model, but if there should be a need to do this, the WEKA wrapper can be used to collect the data.
Training a MAXENT model follows the same general procedure as for WEKA models, but the following difference should be noted. MAXENT models are not updateable, so the model will always be created and trained the first time a classification is attempted. The training of the model might take a considerable amount of time, depending on the amount of training data and the parameters of the model.
Options for the MAXENT Wrapper
- CUT-OFF: MAXENT features will only be included in the model if they occur at least this many times. (The default value of this parameter is zero.)
- ITERATIONS: The number of times the training procedure should iterate when finding the model’s parameters (default is 10). In general no more than about 100 iterations should be needed to train a model, and it is recommended that less are used during development to allow for shorter training times.
- CONFIDENCE-THRESHOLD: Same as for the WEKA wrapper (see above). However, if this parameter is not set, or is set to zero, the model will not use a confidence threshold, but will simply return the most likely classification.
- SMOOTHING: Use smoothing when training the model. Smoothing can improve the accuracy of the learned models, but it will result in longer training times, and training will use more memory. The size of the learned models will also be larger. Generally smoothing will only improve performance for those models trained from small data sets with a few outcomes. With larger data sets with lots of outcomes, it may make performance worse.
- SMOOTHING-OBSERVATION: When using smoothing, this will specify the number of times that trainer will imagine that it has seen features which it did not see (default value is 0.1).
- VERBOSE: If selected, this will cause the classifier to output more details of its operation during execution.
15.3.5 The SVM Light Wrapper [#]
The PR provides a wrapper for the SVM Light ML system (http://svmlight.joachims.org). SVM Light is a support vector machine implementation, written in C, which is provided as a set of command line programs. The wrapper takes care of the mundane work of converting the data structures between GATE and SVM Light formats, and calls the command line programs in the right sequence, passing the data back and forth in temporary files. The <WRAPPER> value for this engine is gate.creole.ml.svmlight.SVMLightWrapper.
The SVM Light binaries themselves are not distributed with GATE – you should download the version for your platform from http://svmlight.joachims.org and place svm_learn and svm_classify on your path.
Classifying documents using the SVMLightWrapper is a two phase procedure. In its first phase, SVMWrapper collects data from the pre-annotated documents and builds the SVM model using the collected data to classify the unseen documents in its second phase. Below we describe briefly an example of classifying the start time of the seminar in a corpus of email announcing seminars and provide more details later in the section.
Figure 15.2 explains step by step the process of collecting training data for the SVM classifier. GATE documents, which are pre-annotated with the annotations of type Class and feature type=’stime’, are used as the training data. In order to build the SVM model, we require start and end annotations for each stime annotation. We use a pre-processor JAPE transduction script to mark the sTimeStart and sTimeEnd annotations on stime annotations. Following this step, the Machine Learning PR (SVMLightWrapper) with training mode set to true collects the training data from all training documents. A GATE corpus pipeline, given a set of documents and PRs to execute on them, executes all PRs one by one, only on one document at a time. Unless provided in a separate pipeline, it makes it impossible to send all training data (i.e. collected from all documents) altogether to the SVMWrapper using the same pipeline to build the SVM model. This results in the model not being built at the time of collecting training data. The state of the SVMWrapper can be saved to an external file once the training data is collected.

Before classifying any unseen document, SVM requires the SVM model to be available. In the absence of an up-to-date SVM model, SVMWrapper builds a new one using a command line SVM_learn utility and the training data collected from the training corpus. In other words, the first SVM model is built when a user tries to classify the first document. At this point the user has an option to save the model somewhere. This is to enable reloading of the model prior to classifying other documents and to avoid rebuilding of the SVM model everytime the user classifies a new set of documents. Once the model becomes available, SVMWrapper classifies the unseen documents which creates new sTimeStart and sTimeEnd annotations over the text. Finally, a post-processor JAPE transduction script is used to combine them into the sTime annotation. Figure 15.3 explains this process.
The wrapper allows support vector machines to be created which do either boolean classification or regression (estimation of numeric parameters), and so the class attribute can be boolean or numeric. Additionally, when learning a classifier, SVM Light supports transduction, whereby additional examples can be presented during training which do not have the value of the class attribute marked. Presenting such examples can, in some circumstances, greatly improve the performance of the classifier. To make use of this, the class attribute can be a three value nominal, in which case the first value specified for that nominal in the configuration file will be interpreted as true, the second as false and the third as unknown. Transduction will be used with any instances for which this attribute is set to the unknown value. It is also possible to use a two value nominal as the class attribute, in which case it will simply be interpreted as true or false.
The other attributes can be boolean, numeric or nominal, or any combination of these. If an attribute is nominal, each value of that attribute maps to a separate SVM Light feature. Each of these SVM Light features will be given the value 1 when the nominal attribute has the corresponding value, and will be omitted otherwise. If the value of the nominal is not specified in the configuration file or there is no value for an instance, then no feature will be added.
An extension to the basic functionality of SVM Light is that each attribute can receive a weighting. These weighting can be specified in the configuration file by adding <WEIGHTING> tags to the parts of the XML file specifying each attribute. The weighting for the attribute must be specified as a numeric value, and be placed between an opening <WEIGHTING> tag and a closing </WEIGHTING> one. Giving an attribute a greater weighting, will cause it to play a greater role in learning the model and classifying data. This is achieved by multiplying the value of the attribute by the weighting before creating the training or test data that is passed to SVM Light. Any attribute left without an explicitly specified weighting is given a default weighting of one. Support for these weightings is contained in the Machine Learning PR itself, and so is available to other wrappers, though at time of writing only the SVM Light wrapper makes use of weightings.
As with the MAXENT wrapper, SVM Light models are not updateable, so the model will be trained at the first classification attempt. The SVM Light wrapper supports <BATCH-MODE-CLASSIFICATION />, which should be used unless you have a very good reason not to.
The SVM Light wrapper allows both data sets and models to be loaded and saved to files in the same formats as those used by SVM Light when it is run from the command line. When a model is saved, a file will be created which contains information about the state of the SVM Light Wrapper, and which is needed to restore it when the model is loaded again. This file does not, however, contain any information about the SVM Light model itself. If an SVM Light model exists at the time of saving, and that model is up to date with respect to the current state of the training data, then it will be saved as a separate file, with the same name as the file containing information about the state of the wrapper, but with .NativePart appended to the filename. These files are in the standard SVM Light model format, and can be used with SVM Light when it is run from the command line. When a model is reloaded by GATE, both of these files must be available, and in the same directory, otherwise an error will result. However, if an up to date trained model does not exist at the time the model is saved, then only one file will be created upon saving, and only that file is required when the model is reloaded. So long as at least one training instance exists, it is possible to bring the model up to date at any point simply by classifying one or more instances (i.e. running the model with the training parameter set to false).
Options for the SVM Light Engine
Only one <OPTIONS> subelement is currently supported:
- <CLASSIFIER-OPTIONS> a string of options to be passed to svm_learn on the command line. The only difference is that the user should not specify whether regression or classification is to be used, as the wrapper will detect this automatically, based on the type of the class attribute, and set the option accordingly.
15.3.6 Example Configuration File [#]
<ML-CONFIG>
<DATASET>
<!-- The type of annotation used as instance -->
<INSTANCE-TYPE>Token</INSTANCE-TYPE>
<ATTRIBUTE>
<!-- The name given to the attribute -->
<NAME>Lookup(0)</NAME>
<!-- The type of annotation used as attribute -->
<TYPE>Lookup</TYPE>
<!-- The position relative to the instance annotation -->
<POSITION>0</POSITION>
</ATTRIBUTE>
<ATTRIBUTE>
<!-- The name given to the attribute -->
<NAME>Lookup_MT(-1)</NAME>
<!-- The type of annotation used as attribute -->
<TYPE>Lookup</TYPE>
<!-- Optional: the feature name for the feature used to extract values
for the attribute -->
<FEATURE>majorType</FEATURE>
<!-- The position relative to the instance annotation -->
<POSITION>-1</POSITION>
<!-- The list of permitted values.
if present, marks a nominal attribute;
if absent, the attribute is numeric (double) -->
<VALUES>
<!-- One permitted value -->
<VALUE>address</VALUE>
<VALUE>cdg</VALUE>
<VALUE>country_adj</VALUE>
<VALUE>currency_unit</VALUE>
<VALUE>date</VALUE>
<VALUE>date_key</VALUE>
<VALUE>date_unit</VALUE>
<VALUE>facility</VALUE>
<VALUE>facility_key</VALUE>
<VALUE>facility_key_ext</VALUE>
<VALUE>govern_key</VALUE>
<VALUE>greeting</VALUE>
<VALUE>ident_key</VALUE>
<VALUE>jobtitle</VALUE>
<VALUE>loc_general_key</VALUE>
<VALUE>loc_key</VALUE>
<VALUE>location</VALUE>
<VALUE>number</VALUE>
<VALUE>org_base</VALUE>
<VALUE>org_ending</VALUE>
<VALUE>org_key</VALUE>
<VALUE>org_pre</VALUE>
<VALUE>organization</VALUE>
<VALUE>organization_noun</VALUE>
<VALUE>percent</VALUE>
<VALUE>person_ending</VALUE>
<VALUE>person_first</VALUE>
<VALUE>person_full</VALUE>
<VALUE>phone_prefix</VALUE>
<VALUE>sport</VALUE>
<VALUE>spur</VALUE>
<VALUE>spur_ident</VALUE>
<VALUE>stop</VALUE>
<VALUE>surname</VALUE>
<VALUE>time</VALUE>
<VALUE>time_modifier</VALUE>
<VALUE>time_unit</VALUE>
<VALUE>title</VALUE>
<VALUE>year</VALUE>
</VALUES>
<!-- Optional: if present marks the attribute used as CLASS
Only one attribute can be marked as class -->
</ATTRIBUTE>
<ATTRIBUTE>
<!-- The name given to the attribute -->
<NAME>Lookup_MT(0)</NAME>
<!-- The type of annotation used as attribute -->
<TYPE>Lookup</TYPE>
<!-- Optional: the feature name for the feature used to extract values
for the attribute -->
<FEATURE>majorType</FEATURE>
<!-- The position relative to the instance annotation -->
<POSITION>0</POSITION>
<!-- The list of permitted values.
if present, marks a nominal attribute;
if absent, the attribute is numeric (double) -->
<VALUES>
<!-- One permitted value -->
<VALUE>address</VALUE>
<VALUE>cdg</VALUE>
<VALUE>country_adj</VALUE>
<VALUE>currency_unit</VALUE>
<VALUE>date</VALUE>
<VALUE>date_key</VALUE>
<VALUE>date_unit</VALUE>
<VALUE>facility</VALUE>
<VALUE>facility_key</VALUE>
<VALUE>facility_key_ext</VALUE>
<VALUE>govern_key</VALUE>
<VALUE>greeting</VALUE>
<VALUE>ident_key</VALUE>
<VALUE>jobtitle</VALUE>
<VALUE>loc_general_key</VALUE>
<VALUE>loc_key</VALUE>
<VALUE>location</VALUE>
<VALUE>number</VALUE>
<VALUE>org_base</VALUE>
<VALUE>org_ending</VALUE>
<VALUE>org_key</VALUE>
<VALUE>org_pre</VALUE>
<VALUE>organization</VALUE>
<VALUE>organization_noun</VALUE>
<VALUE>percent</VALUE>
<VALUE>person_ending</VALUE>
<VALUE>person_first</VALUE>
<VALUE>person_full</VALUE>
<VALUE>phone_prefix</VALUE>
<VALUE>sport</VALUE>
<VALUE>spur</VALUE>
<VALUE>spur_ident</VALUE>
<VALUE>stop</VALUE>
<VALUE>surname</VALUE>
<VALUE>time</VALUE>
<VALUE>time_modifier</VALUE>
<VALUE>time_unit</VALUE>
<VALUE>title</VALUE>
<VALUE>year</VALUE>
</VALUES>
<!-- Optional: if present marks the attribute used as CLASS
Only one attribute can be marked as class -->
</ATTRIBUTE>
<ATTRIBUTE>
<!-- The name given to the attribute -->
<NAME>Lookup_MT(1)</NAME>
<!-- The type of annotation used as attribute -->
<TYPE>Lookup</TYPE>
<!-- Optional: the feature name for the feature used to extract values
for the attribute -->
<FEATURE>majorType</FEATURE>
<!-- The position relative to the instance annotation -->
<POSITION>1</POSITION>
<!-- The list of permitted values.
if present, marks a nominal attribute;
if absent, the attribute is numeric (double) -->
<VALUES>
<!-- One permitted value -->
<VALUE>address</VALUE>
<VALUE>cdg</VALUE>
<VALUE>country_adj</VALUE>
<VALUE>currency_unit</VALUE>
<VALUE>date</VALUE>
<VALUE>date_key</VALUE>
<VALUE>date_unit</VALUE>
<VALUE>facility</VALUE>
<VALUE>facility_key</VALUE>
<VALUE>facility_key_ext</VALUE>
<VALUE>govern_key</VALUE>
<VALUE>greeting</VALUE>
<VALUE>ident_key</VALUE>
<VALUE>jobtitle</VALUE>
<VALUE>loc_general_key</VALUE>
<VALUE>loc_key</VALUE>
<VALUE>location</VALUE>
<VALUE>number</VALUE>
<VALUE>org_base</VALUE>
<VALUE>org_ending</VALUE>
<VALUE>org_key</VALUE>
<VALUE>org_pre</VALUE>
<VALUE>organization</VALUE>
<VALUE>organization_noun</VALUE>
<VALUE>percent</VALUE>
<VALUE>person_ending</VALUE>
<VALUE>person_first</VALUE>
<VALUE>person_full</VALUE>
<VALUE>phone_prefix</VALUE>
<VALUE>sport</VALUE>
<VALUE>spur</VALUE>
<VALUE>spur_ident</VALUE>
<VALUE>stop</VALUE>
<VALUE>surname</VALUE>
<VALUE>time</VALUE>
<VALUE>time_modifier</VALUE>
<VALUE>time_unit</VALUE>
<VALUE>title</VALUE>
<VALUE>year</VALUE>
</VALUES>
<!-- Optional: if present marks the attribute used as CLASS
Only one attribute can be marked as class -->
</ATTRIBUTE>
<ATTRIBUTE>
<!-- The name given to the attribute -->
<NAME>POS_category(-1)</NAME>
<!-- The type of annotation used as attribute -->
<TYPE>Token</TYPE>
<!-- Optional: the feature name for the feature used to extract values
for the attribute -->
<FEATURE>category</FEATURE>
<!-- The position relative to the instance annotation -->
<POSITION>-1</POSITION>
<!-- The list of permitted values.
if present, marks a nominal attribute;
if absent, the attribute is numeric (double) -->
<VALUES>
<!-- One permitted value -->
<VALUE>NN</VALUE>
<VALUE>NNP</VALUE>
<VALUE>NNPS</VALUE>
<VALUE>NNS</VALUE>
<VALUE>NP</VALUE>
<VALUE>NPS</VALUE>
<VALUE>JJ</VALUE>
<VALUE>JJR</VALUE>
<VALUE>JJS</VALUE>
<VALUE>JJSS</VALUE>
<VALUE>RB</VALUE>
<VALUE>RBR</VALUE>
<VALUE>RBS</VALUE>
<VALUE>VB</VALUE>
<VALUE>VBD</VALUE>
<VALUE>VBG</VALUE>
<VALUE>VBN</VALUE>
<VALUE>VBP</VALUE>
<VALUE>VBZ</VALUE>
<VALUE>FW</VALUE>
<VALUE>CD</VALUE>
<VALUE>CC</VALUE>
<VALUE>DT</VALUE>
<VALUE>EX</VALUE>
<VALUE>IN</VALUE>
<VALUE>LS</VALUE>
<VALUE>MD</VALUE>
<VALUE>PDT</VALUE>
<VALUE>POS</VALUE>
<VALUE>PP</VALUE>
<VALUE>PRP</VALUE>
<VALUE>PRP$</VALUE>
<VALUE>PRPR$</VALUE>
<VALUE>RP</VALUE>
<VALUE>TO</VALUE>
<VALUE>UH</VALUE>
<VALUE>WDT</VALUE>
<VALUE>WP</VALUE>
<VALUE>WP$</VALUE>
<VALUE>WRB</VALUE>
<VALUE>SYM</VALUE>
<VALUE>\"</VALUE>
<VALUE>#</VALUE>
<VALUE>$</VALUE>
<VALUE>’</VALUE>
<VALUE>(</VALUE>
<VALUE>)</VALUE>
<VALUE>,</VALUE>
<VALUE>--</VALUE>
<VALUE>-LRB-</VALUE>
<VALUE>.</VALUE>
<VALUE>’’</VALUE>
<VALUE>:</VALUE>
<VALUE>::</VALUE>
<VALUE>‘</VALUE>
</VALUES>
<!-- Optional: if present marks the attribute used as CLASS
Only one attribute can be marked as class -->
</ATTRIBUTE>
<ATTRIBUTE>
<!-- The name given to the attribute -->
<NAME>POS_category(0)</NAME>
<!-- The type of annotation used as attribute -->
<TYPE>Token</TYPE>
<!-- Optional: the feature name for the feature used to extract values
for the attribute -->
<FEATURE>category</FEATURE>
<!-- The position relative to the instance annotation -->
<POSITION>0</POSITION>
<!-- The list of permitted values.
if present, marks a nominal attribute;
if absent, the attribute is numeric (double) -->
<VALUES>
<!-- One permitted value -->
<VALUE>NN</VALUE>
<VALUE>NNP</VALUE>
<VALUE>NNPS</VALUE>
<VALUE>NNS</VALUE>
<VALUE>NP</VALUE>
<VALUE>NPS</VALUE>
<VALUE>JJ</VALUE>
<VALUE>JJR</VALUE>
<VALUE>JJS</VALUE>
<VALUE>JJSS</VALUE>
<VALUE>RB</VALUE>
<VALUE>RBR</VALUE>
<VALUE>RBS</VALUE>
<VALUE>VB</VALUE>
<VALUE>VBD</VALUE>
<VALUE>VBG</VALUE>
<VALUE>VBN</VALUE>
<VALUE>VBP</VALUE>
<VALUE>VBZ</VALUE>
<VALUE>FW</VALUE>
<VALUE>CD</VALUE>
<VALUE>CC</VALUE>
<VALUE>DT</VALUE>
<VALUE>EX</VALUE>
<VALUE>IN</VALUE>
<VALUE>LS</VALUE>
<VALUE>MD</VALUE>
<VALUE>PDT</VALUE>
<VALUE>POS</VALUE>
<VALUE>PP</VALUE>
<VALUE>PRP</VALUE>
<VALUE>PRP$</VALUE>
<VALUE>PRPR$</VALUE>
<VALUE>RP</VALUE>
<VALUE>TO</VALUE>
<VALUE>UH</VALUE>
<VALUE>WDT</VALUE>
<VALUE>WP</VALUE>
<VALUE>WP$</VALUE>
<VALUE>WRB</VALUE>
<VALUE>SYM</VALUE>
<VALUE>\"</VALUE>
<VALUE>#</VALUE>
<VALUE>$</VALUE>
<VALUE>’</VALUE>
<VALUE>(</VALUE>
<VALUE>)</VALUE>
<VALUE>,</VALUE>
<VALUE>--</VALUE>
<VALUE>-LRB-</VALUE>
<VALUE>.</VALUE>
<VALUE>’’</VALUE>
<VALUE>:</VALUE>
<VALUE>::</VALUE>
<VALUE>‘</VALUE>
</VALUES>
<!-- Optional: if present marks the attribute used as CLASS
Only one attribute can be marked as class -->
</ATTRIBUTE>
<ATTRIBUTE>
<!-- The name given to the attribute -->
<NAME>POS_category(1)</NAME>
<!-- The type of annotation used as attribute -->
<TYPE>Token</TYPE>
<!-- Optional: the feature name for the feature used to extract values
for the attribute -->
<FEATURE>category</FEATURE>
<!-- The position relative to the instance annotation -->
<POSITION>1</POSITION>
<!-- The list of permitted values.
if present, marks a nominal attribute;
if absent, the attribute is numeric (double) -->
<VALUES>
<!-- One permitted value -->
<VALUE>NN</VALUE>
<VALUE>NNP</VALUE>
<VALUE>NNPS</VALUE>
<VALUE>NNS</VALUE>
<VALUE>NP</VALUE>
<VALUE>NPS</VALUE>
<VALUE>JJ</VALUE>
<VALUE>JJR</VALUE>
<VALUE>JJS</VALUE>
<VALUE>JJSS</VALUE>
<VALUE>RB</VALUE>
<VALUE>RBR</VALUE>
<VALUE>RBS</VALUE>
<VALUE>VB</VALUE>
<VALUE>VBD</VALUE>
<VALUE>VBG</VALUE>
<VALUE>VBN</VALUE>
<VALUE>VBP</VALUE>
<VALUE>VBZ</VALUE>
<VALUE>FW</VALUE>
<VALUE>CD</VALUE>
<VALUE>CC</VALUE>
<VALUE>DT</VALUE>
<VALUE>EX</VALUE>
<VALUE>IN</VALUE>
<VALUE>LS</VALUE>
<VALUE>MD</VALUE>
<VALUE>PDT</VALUE>
<VALUE>POS</VALUE>
<VALUE>PP</VALUE>
<VALUE>PRP</VALUE>
<VALUE>PRP$</VALUE>
<VALUE>PRPR$</VALUE>
<VALUE>RP</VALUE>
<VALUE>TO</VALUE>
<VALUE>UH</VALUE>
<VALUE>WDT</VALUE>
<VALUE>WP</VALUE>
<VALUE>WP$</VALUE>
<VALUE>WRB</VALUE>
<VALUE>SYM</VALUE>
<VALUE>\"</VALUE>
<VALUE>#</VALUE>
<VALUE>$</VALUE>
<VALUE>’</VALUE>
<VALUE>(</VALUE>
<VALUE>)</VALUE>
<VALUE>,</VALUE>
<VALUE>--</VALUE>
<VALUE>-LRB-</VALUE>
<VALUE>.</VALUE>
<VALUE>’’</VALUE>
<VALUE>:</VALUE>
<VALUE>::</VALUE>
<VALUE>‘</VALUE>
</VALUES>
<!-- Optional: if present marks the attribute used as CLASS
Only one attribute can be marked as class -->
</ATTRIBUTE>
<ATTRIBUTE>
<!-- The name given to the attribute -->
<NAME>Entity(0)</NAME>
<!-- The type of annotation used as attribute -->
<TYPE>Entity</TYPE>
<!-- The position relative to the instance annotation -->
<POSITION>0</POSITION>
<CLASS/>
<!-- Optional: if present marks the attribute used as CLASS
Only one attribute can be marked as class -->
</ATTRIBUTE>
</DATASET>
<ENGINE>
<WRAPPER>gate.creole.ml.weka.Wrapper</WRAPPER>
<OPTIONS>
<CLASSIFIER OPTIONS="-S -C 0.25 -B -M 2">weka.classifiers.trees.J48</CLASSIFIER>
<CONFIDENCE-THRESHOLD>0.85</CONFIDENCE-THRESHOLD>
</OPTIONS>
</ENGINE>
</ML-CONFIG>
1This is only true for GATE 5.2 or later; in earlier versions all modes were unsafe for multiple instances of the PR.
2The SVM package SV Mlight can be downloaded from http://svmlight.joachims.org/.
