Chapter 13
Gazetteers [#]
...neurobiologists still go on openly studying reflexes and looking under the hood, not huddling passively in the trenches. Many of them still keep wondering: how does the inner life arise? Ever puzzled, they oscillate between two major fictions: (1) The brain can be understood; (2) We will never come close. Meanwhile they keep pursuing brain mechanisms, partly from habit, partly out of faith. Their premise: The brain is the organ of the mind. Clearly, this three-pound lump of tissue is the source of our ‘insight information’ about our very being. Somewhere in it there might be a few hidden guidelines for better ways to lead our lives.
Zen and the Brain, James H. Austin, 1998 (p. 6).
13.1 Introduction to Gazetteers [#]
A gazetteer consists of a set of lists containing names of entities such as cities, organisations, days of the week, etc. These lists are used to find occurrences of these names in text, e.g. for the task of named entity recognition. The word ‘gazetteer’ is often used interchangeably for both the set of entity lists and for the processing resource that makes use of those lists to find occurrences of the names in text.
When a gazetteer processing resource is run on a document, annotations of type Lookup are created for each matching string in the text. Gazetteers usually do not depend on Tokens or on any other annotation and instead find matches based on the textual content of the document. (the Flexible Gazetteer, described in section 13.7, being the exception to the rule). This means that an entry may span more than one word and may start or end within a word. If a gazetteer that directly works on text does respect word boundaries, the way how word boundaries are found might differ from the way the GATE tokeniser finds word boundaries. A Lookup annotation will only be created if the entire gazetteer entry is matched in the text. The details of how gazetteer entries match text depend on the gazetteer processing resource and its parameters. In this chapter, we will cover several gazetteers.
13.2 ANNIE Gazetteer [#]
The rest of this introductory section describes the ANNIE Gazetteer which is part of ANNIE and also described in section 6.3. The ANNIE gazetteer is part of and proved by the ANNIE plugin.
Each individual gazetteer list is a plain text file, with one entry per line.
Below is a section of the list for units of currency:
European Currency Units
FFr
Fr
German mark
German marks
New Taiwan dollar
New Taiwan dollars
NT dollar
NT dollars
An index file (usually called lists.def) is used to describe all such gazetteer list files that belong together. Each gazetteer list should reside in the same directory as the index file.
The gazetteer index files describes for each list the major type and optionally, a minor type and a language, separated by colons. In the example below, the first column refers to the list name, the second column to the major type, and the third to the minor type. These lists are compiled into finite state machines. Any text strings matched by these machines will be annotated with features specifying the major and minor types.
currency_unit.lst:currency_unit:post_amount
date.lst:date:specific_date
day.lst:date:day
monthen.lst:date:month:en
monthde.lst:date:month:de
season.lst:date:season
The major and minor type as well as the language will be added as features to only Lookup annotation generated from a matching entry from the respective list. For example, if an entry from the currency_unit.lst gazetteer list matches some text in a document, the gazetteer processing resource will generate a Lookup annotation spanning the matching text and assign the features major="currency_unit" and minor="post_amount" to that annotation.
Grammar rules (JAPE rules) can specify the types to be identified in particular circumstances. The major and minor types enable this identification to take place, by giving access to items stored in particular lists or combinations of lists.
For example, if a day needs to be identified, the minor type ‘day’ would be specified in the grammar, in order to match only information about specific days. If any kind of date needs to be identified, the major type ‘date’ would be specified. This might include weeks, months, years etc. as well as days of the week, and would give access to all the items stored in day.lst, month.lst, season.lst, and date.lst in the example shown.
13.2.1 Creating and Modifying Gazetteer Lists
Gazetteer lists can be modified using any text editor or an editor inside GATE when you double-click on the gazetteer in the resources tree. Use of an editor that can edit Unicode UTF-8 files (e.g. the GATE Unicode editor) is advised, however, in order to ensure that the lists are stored as UTF-8, which will minimise any language encoding problems, particularly if e.g. accents, umlauts or characters from non-Latin scripts are present.
To create a new list, simply add an entry for that list to the definitions file and add the new list in the same directory as the existing lists.
After any modifications have been made in an external editor, ensure that you reinitialise the gazetteer PR in GATE, if one is already loaded, before rerunning your application.
13.2.2 ANNIE Gazetteer Editor [#]
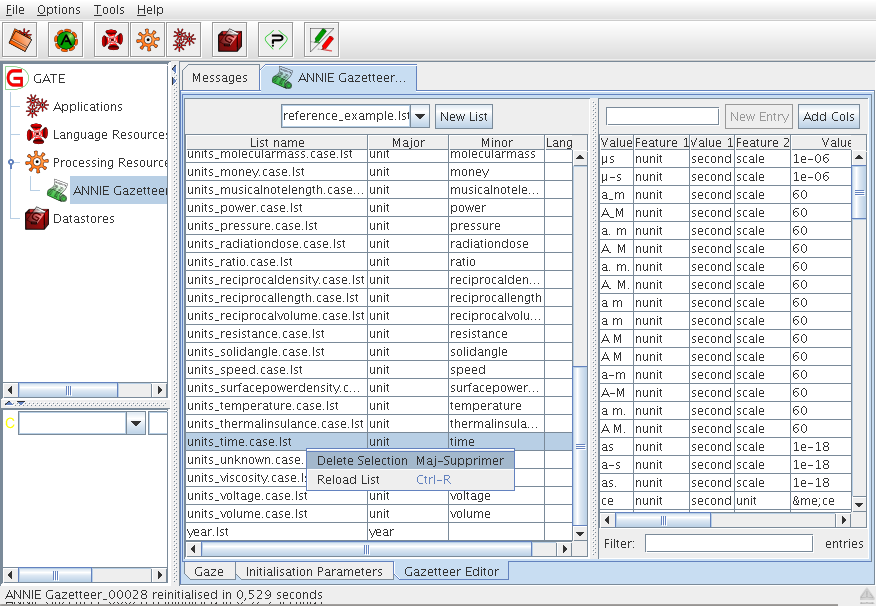
This editor is similar to GAZE editor but aims at being simpler by restricting itself to ANNIE Gazetteers. To open it, double-click on the gazetteer in the resources tree.
It is composed of two tables:
- a left table with 4 columns (List name, Major, Minor, Language) for the index, usually a .def file
- a right table with 1+2*n columns (Value, Feature 1, Value 1...Feature n, Value n) for the lists, usually .lst files
When selecting a list in the left table you get its content displayed in the right table.
You can sort both tables by clicking on their column headers. A text field ‘Filter’ at the bottom of the right table allows to display only the rows that contain the expression you typed.
To edit a value in a table, double click on a cell or press F2 then press Enter when finished editing the cell. To add a new row in both tables use the text field at the top and press Enter or use the ‘New’ button next to it. When adding a new list you can select from the list of existing gazetteer lists in the current directory or type a new file name. To delete a row, press Shift+Delete or use the context menu. To delete more than one row select them before.
You can reload a modified list by selecting it and right-clicking for the context menu item ‘Reload List’ or by pressing Control+R. When a list is modified its name in the left table is coloured in red.
If you have set ‘gazetteerFeatureSeparator’ parameter then the right table will show a ‘Feature’ and ‘Value’ columns for each feature. To add a new couple of columns use the button ‘Add Cols’.
Note that in the left table, you can only select one row at a time.
The gazetteer like other language resource has a context menu in the resources tree to ‘Reinitialise’, ‘Save’ or ‘Save as...’ the resource.
The right table has a context menu for the current selection to help you creating new gazetteer. It is similar with the actions found in a spreadsheet application like ‘Fill Down Selection’, ‘Clear Selection’, ‘Copy Selection’, ‘Paste Selection’, etc.
13.3 Gazetteer Visual Resource - GAZE [#]
Gaze is a tool for editing the gazetteer lists , definitions and mapping to ontology. It is suitable for use both for Plain/Linear Gazetteers (Default and Hash Gazetteers) and Ontology-enabled Gazetteers (OntoGazetteer). The Gazetteer PR associated with the viewer is reinitialised every time a save operation is performed. Note that GAZE does not scale up to very large lists (we suggest not using it to view over 40,000 entries and not to copy inside more than 10, 000 entries).
Gaze is part of and provided by the ANNIE plugin. To make it possible to visualize gazetteers with the Gaze visualizer, the ANNIE plugin must be loaded first. Double clicking on a gazetteer PR that uses a gazetteer definition (index) file will display the contents of the gazetteer in the main window. The first pane will display the definition file, while the right pane will display whichever gazetteer list has been selected from it.
A gazetteer list can be modified simply by typing in it. it can be saved by clicking the Save button. When a list is saved, the whole gazetteer is automatically reinitialised (and will be ready for use in GATE immediately).
To edit the definition file, right click inside the pane and choose from the options (Inset, Edit, Remove). A pop-up menu will appear to guide you through the remaining process. Save the definition file by selecting Save. Again, the gazetteer will be reinitialised automatically.
13.3.1 Display Modes
The display mode depends on the type of gazetteer loaded in the VR. The mode in which Linear/Plain Gazetteers are loaded is called Linear/Plain Mode. In this mode, the Linear Definition is displayed in the left pane, and the Gazetteer List is displayed in the right pane. The Ontology/Extended mode is on when the displayed gazetteer is ontology-aware, which means that there exists a mapping between classes in the ontology and lists of phrases. Two more panes are displayed when in this mode. On the top in the left-most pane there is a tree view of the ontology hierarchy, and at the bottom the mapping definition is displayed. This section describes the Linear/Plain display mode, the Ontology/Extended mode is described in section 13.5.
Whenever a gazetteer PR that uses a gazetteer definition (index) file is loaded, the Gaze gazetteer visualisation will appear on double-click over the gazetteer in the Processing Resources branch of the Resources Tree.
13.3.2 Linear Definition Pane
This pane displays the nodes of the linear definition, and allows manipulation of the whole definition as a file, as well as the single nodes. Whenever a gazetteer list is modified, its node in the linear definition is coloured in red.
13.3.3 Linear Definition Toolbar
All the functionality explained in this section (New, Load, Save, Save As) is accessible also via File — Linear Definition in the menu bar of Gaze.
New – Pressing New invokes a file dialog where the location of the new definition is specified.
Load – Pressing Load invokes a file dialog, and after locating the new definition it is loaded by pressing Open.
Save – Pressing Save saves the definition to the location from which it has been read.
Save As – Pressing Save As allows another location to be chosen, and the definition saved there.
13.3.4 Operations on Linear Definition Nodes
Double-click node – Double-clicking on a definition node forces the displaying of the gazetteer list of the node in the right-most pane of the viewer.
Insert – On right-click over a node and choosing Insert, a dialog is displayed, requesting List, Major Type, Minor Type and Languages. The mandatory fields are List and Major Type. After pressing OK, a new linear node is added to the definition.
Remove – On right-click over a node and choosing Remove, the selected linear node is removed from the definition.
Edit – On right-click over a node and choosing Edit a dialog is displayed allowing changes of the fields List, Major Type, Minor Type and Languages.
13.3.5 Gazetteer List Pane
The gazetteer list pane has a toolbar with similar to the linear definition’s buttons (New, Load, Save, Save As). They work as predicted by their names and as explained in the Linear Definition Pane section, and are also accessible from File / Gazetteer List in the menu bar of Gaze. The only addition is Save All which saves all modified gazetteer lists. The editing of the gazetteer list is as simple as editing a text file. One could use Ctrl+A to select the whole list, Ctrl+C to copy the selected, Ctrl+V to paste it, Del to delete the selected text or a single character, etc.
13.3.6 Mapping Definition Pane
The mapping definition is displayed one mapping node per row. It consists of a gazetteer list, ontology URL, and class id. The content of the gazetteer list in the node is accessible through double-clicking. It is displayed in the Gazetteer List Pane. The toolbar allows the creation of a new definition (New), the loading of an existing one (Load), saving to the same or new location (Save/Save As). The functionality of the toolbar buttons is also available via File.
13.4 OntoGazetteer [#]
The Ontogazetteer, or Hierarchical Gazetteer, is a processing resource which can associate the entities from a specific gazetteer list with a class in a GATE ontology language resource. The OntoGazetteer assigns classes rather than major or minor types, and is aware of mappings between lists and class IDs. The Gaze visual resource can display the lists, ontology mappings and the class hierarchy of the ontology for a OntoGazetteer processing resource and provides ways of editing these components.
13.5 Gaze Ontology Gazetteer Editor [#]
This section describes the Gaze gazetteer editor when it displays an OntoGazetteer processing resource. The editor consists of two parts: one for the editing of the lists and the mapping of lists and one for editing the ontology. These two parts are described in the following subsections.
13.5.1 The Gaze Gazetteer List and Mapping Editor
This is a VR for editing the gazetteer lists, and mapping them to classes in an ontology. It provides load/store/edit for the lists, load/store/edit for the mapping information, loading of ontologies, load/store/edit for the linear definition file, and mapping of the lists file to the major type, minor type and language.
Left pane: A single ontology is visualized in the left pane of the VR. The mapping between a list and a class is displayed by showing the list as a subclass with a different icon. The mapping is specified by drag and drop from the linear definition pane (in the middle) and/or by right click menu.
Middle pane: The middle pane displays the nodes/lines in the linear definition file. By double clicking on a node the corresponding list is opened. Editing of the line/node is done by right clicking and choosing edit: a dialogue appears (lower part of the scheme) allowing the modification of the members of the node.
Right pane: In the right pane a single gazetteer list is displayed. It can be edited and parts of it can be cut/copied/pasted.
13.5.2 The Gaze Ontology Editor
Note: to edit ontologies within gate, the more recent ontology viewer editor provided by the Ontology_Tools which provides many more features can be used, see section 14.5.
This is a VR for editing the class hierarchy of an ontology. it provides storing to and loading from RDF/RDFS, and provides load/edit/store of the class hierarchy of an ontology.
Left pane: The various ontologies loaded are listed here. On double click or right click and edit from the menu the ontology is visualized in the Right pane.
Right pane: Besides the visualization of the class hierarchy of the ontology the following operations are allowed:
- expanding/collapsing parts of the ontology
- adding a class in the hierarchy: by right clicking on the intended parent of the new class and choosing add sub class.
- removing a class: via right clicking on the class and choosing remove.
As a result of this VR, the ontology definition file is affected/altered.
13.6 Hash Gazetteer [#]
The Hash Gazetteer is a gazetteer implemented by the OntoText Lab (http://www.ontotext.com/). Its implementation is based on simple lookup in several java.util.HashMap objects, and is inspired by the strange idea of Atanas Kiryakov, that searching in HashMaps will be faster than a search in a Finite State Machine (FSM). The Hash Gazetteer processing resource is part of the ANNIE plugin.
This gazetteer processing resource is implemented in the following way: Every phrase i.e. every list entry is separated into several parts. The parts are determined by the whitespaces lying among them. e.g. the phrase : ”form is emptiness” has three parts : “form”, “is”, and “emptiness”. There is also a list of HashMaps: mapsList which has as many elements as the longest (in terms of ‘count of parts’) phrase in the lists. So the first part of a phrase is placed in the first map. The first part + space + second part is placed in the second map, etc. The full phrase is placed in the appropriate map, and a reference to a Lookup object is attached to it.
On first sight it seems that this algorithm is certainly much more memory-consuming than a finite state machine (FSM) with the parts of the phrases as transitions, but this is actually not so important since the average length of the phrases (in parts) in the lists is 1.1. On the other hand, one advantage of the algorithm is that, although unconventional, on average it takes four times less memory and works three times faster than an optimized FSM implementation.
13.6.1 Prerequisites
The phrases to be recognised should be listed in a set of files, one for each type of occurrence (as for the standard gazetteer).
The gazetteer is built with the information from a file that contains the set of lists (which are files as well) and the associated type for each list. The file defining the set of lists should have the following syntax: each list definition should be written on its own line and should contain:
- the file name (required)
- the major type (required)
- the minor type (optional)
- the language(s) (optional)
The elements of each definition are separated by ‘:’. The following is an example of a valid definition:
Each file named in the lists definition file is just a list containing one entry per line.
When this gazetteer is run over some input text (a GATE document) it will generate annotations of type Lookup having the attributes specified in the definition file.
13.6.2 Parameters
The Hash Gazetteer processing resource allows the specification of the following parameters when it is created:
- caseSensitive:
- this can be switched between true and false to indicate if matches should be done in a case-sensitive way.
- encoding:
- the encoding of the gazetteer lists
- listsURL:
- the URL of the list definitions (index) file, i.e. the file that contains the filenames, major types and optionally minor types and languages of all the list files.
There is one run-time parameter, annotationSetName that allows the specification of the annotation set in which the Lookup annotations will be created. If nothing is specified the default annotation set will be used.
13.7 Flexible Gazetteer [#]
The Flexible Gazetteer provides users with the flexibility to choose their own customized input and an external Gazetteer. For example, the user might want to replace words in the text with their base forms (which is an output of the Morphological Analyser) or to segment a Chinese text (using the Chinese Tokeniser) before running the Gazetteer on the Chinese text.
The Flexible Gazetteer performs lookup over a document based on the values of an arbitrary feature of an arbitrary annotation type, by using an externally provided gazetteer. It is important to use an external gazetteer as this allows the use of any type of gazetteer (e.g. an Ontological gazetteer).
Input to the Flexible Gazetteer:
Runtime parameters:
- Document – the document to be processed
- inputAnnotationSetName The annotationSet where the Flexible Gazetteer should search for the AnnotationType.feature specified in the inputFeatureNames.
- outputAnnotationSetName The AnnotationSet where Lookup annotations should
be placed.
Creation time parameters:
- inputFeatureNames – when selected, these feature values are used to replace the corresponding original text. A temporary document is created from the values of the specified features on the specified annotation types. For example: for Token.string the temporary document will have the same content as the original one but all the SpaceToken annotations will have been replaced by single spaces.
- gazetteerInst – the actual gazetteer instance, which should run over a temporary document. This generates the Lookup annotations with features. This must be an instance of gate.creole.gazetteer.Gazetteer which has already been created. All such instances will be shown in the dropdown menu for this parameter in GATE Developer.
Once the external gazetteer has annotated text with Lookup annotations, Lookup annotations on the temporary document are converted to Lookup annotations on the original document. Finally the temporary document is deleted.
13.8 Gazetteer List Collector [#]
The gazetteer list collector collects occurrences of entities directly from a set of annotated training texts, and populates gazetteer lists with the entities. The entity types and structure of the gazetteer lists are defined as necessary by the user. Once the lists have been collected, a semantic grammar can be used to find the same entities in new texts.
An empty list must be created first for each annotation type, if no list exists already. The set of lists must be loaded into GATE before the PR can be run. If a list already exists, the list will simply be augmented with any new entries. The list collector will only collect one occurrence of each entry: it first checks that the entry is not present already before adding a new one.
There are 4 runtime parameters:
- annotationTypes: a list of the annotation types that should be collected
- gazetteer: the gazetteer where the results will be stored (this must be already loaded in GATE)
- markupASname: the annotation set from which the annotation types should be collected
- theLanguage: sets the language feature of the gazetteer lists to be created to the appropriate language (in the case where lists are collected for different languages)
Figure 13.2 shows a screenshot of a set of lists collected automatically for the Hindi language. It contains 4 lists: Person, Organisation, Location and a list of stopwords. Each list has a majorType whose value is the type of list, a minorType ‘inferred’ (since the lists have been inferred from the text), and the language ‘Hindi’.
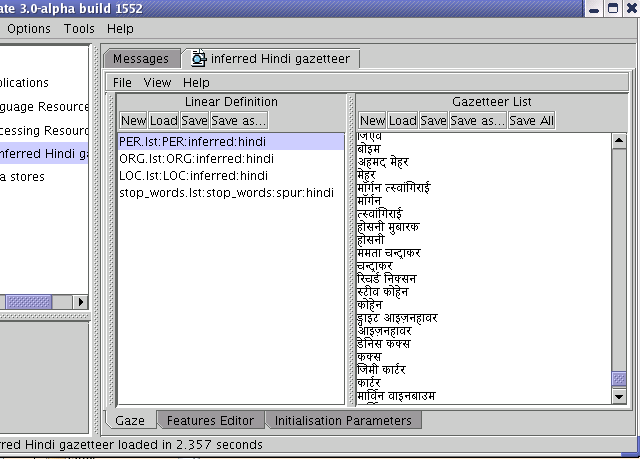
The list collector also has a facility to split the Person names that it collects into their individual tokens, so that it adds both the entire name to the list, and adds each of the tokens to the list (i.e. each of the first names, and the surname) as a separate entry. When the grammar annotates Persons, it can require them to be at least 2 tokens or 2 consecutive Person Lookups. In this way, new Person names can be recognised by combining a known first name with a known surname, even if they were not in the training corpus. Where only a single token is found that matches, an Unknown entity is generated, which can later be matched with an existing longer name via the orthomatcher component which performs orthographic coreference between named entities. This same procedure can also be used for other entity types. For example, parts of Organisation names can be combined together in different ways. The facility for splitting Person names is hardcoded in the file gate/src/gate/creole/GazetteerListsCollector.java and is commented.
13.9 OntoRoot Gazetteer [#]
OntoRoot Gazetteer is a type of a dynamically created gazetteer that is, in combination with few other generic GATE resources, capable of producing ontology-based annotations over the given content with regards to the given ontology. This gazetteer is a part of ‘Gazetteer_Ontology_Based’ plugin that has been developed as a part of the TAO project.
13.9.1 How Does it Work? [#]
To produce ontology-based annotations i.e. annotations that link to the specific concepts or relations from the ontology, it is essential to pre-process the Ontology Resources (e.g., Classes, Instances, Properties) and extract their human-understandable lexicalisations.
As a precondition for extracting human-understandable content from the ontology, first a list of the following is being created:
- names of all ontology resources i.e. fragment identifiers 1 and
- assigned property values for all ontology resources (e.g., label and datatype property values)
Each item from the list is further processed so that:
- any name containing dash ("-") or underline ("_") character(s) is processed so that each of these characters is replaced by a blank space. For example, Project_Name or Project-Name would become a Project Name.
- any name that is written in camelCase style is actually split into its constituent words, so that ProjectName becomes a Project Name (optional).
- any name that is a compound name such as ‘POS Tagger for Spanish’ is split so that both ‘POS Tagger’ and ‘Tagger’ are added to the list for processing. In this example, ‘for’ is a stop word, and any words after it are ignored (optional).
Each item from this list is analysed separately by the Onto Root Application (ORA) on execution (see figure 13.3). The Onto Root Application first tokenises each linguistic term, then assigns part-of-speech and lemma information to each token.
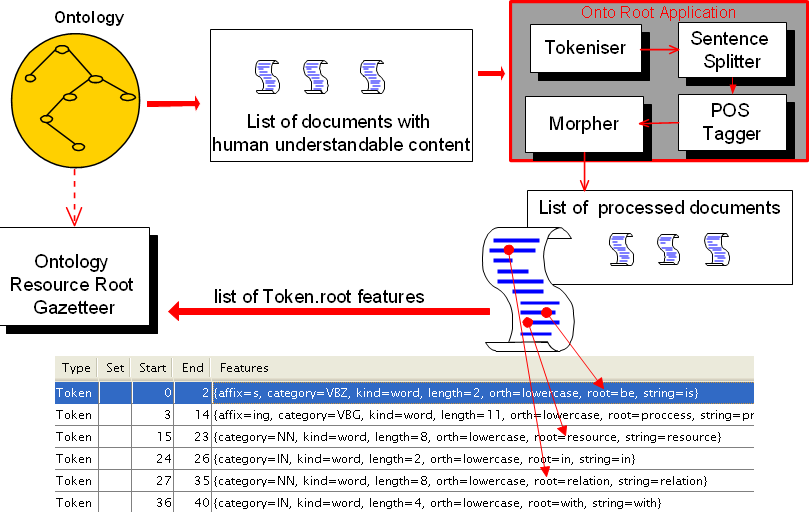
As a result of that pre-processing, each token in the terms will have additional feature named ‘root’, which contains the lemma as created by the morphological analyser. It is this lemma or a set of lemmas which are then added to the dynamic gazetteer list, created from the ontology.
For instance, if there is a resource with a short name (i.e., fragment identifier) ProjectName, without any assigned properties the created list before executing the OntoRoot gazetteer collection will contain the following strings:
- ‘ProjectName’,
- ‘Project Name’ after separating camelCased word and
- ‘Name’ after applying heuristic rules.
Each of the item from the list is then analysed separately and the results would be the same as the input strings, as all of entries are nouns given in singular form.
13.9.2 Initialisation of OntoRoot Gazetteer [#]
To initialise the gazetteer there are few mandatory parameters:
- Ontology to be processed;
- Tokeniser, POS Tagger and GATE Morphological Analyser to be used during processing.
and few optional ones:
- useResourceUri, default is set to true - should this gazetteer analyse resource URIs or not;
- considerProperties, default is set to true - should this gazetteer consider properties or not;
- propertiesToInclude - checked only if considerProperties is set to true - this parameter contains the list of property names (URIs) to be included, comma separated;
- propertiesToExclude - checked only if considerProperties is set to true - this parameter contains the list of property names to be excluded, comma separated;
- caseSensitive, default set to be false -should this gazetteer differentiate on case;
- separateCamelCasedWords, default set to true - should this gazetteer separate emphcamelCased words, e.g. ‘ProjectName’ into ‘Project Name’;
- considerHeuristicRules, default set to false - should this gazetteer consider several heuristic rules or not. Rules include splitting the words containing spaces, and using prepositions as stop words; for example, if ’pos tagger for Spanish’ would be analysed, ‘for’ would be considered as a stop word; heuristically derived would be ‘pos tagger’ and this would be further used to add ‘pos tagger’ to the gazetteer list, with a feature emphheuristical level set to be 0, and ‘tagger’ with emphheuristical level 1; at runtime lower heuristical level should be preferred. NOTE: setting considerHeuristicRules to true can cause a lot of noise for some ontologies and is likely to require implementing an additional filtering resource that will prefer the annotations with the lower heuristic level;
13.9.3 Simple steps to run OntoRoot Gazetteer [#]
OntoRoot Gazetteer is a part of the Gazetteer_Ontology_Based plugin.
Easy way [#]
For a quick start with the OntoRoot Gazetteer, consider running it from the GATE Developer (GATE GUI):
- Start GATE
- Load a sample application from resources folder (exampleApp.xgapp). This will load CAT App application.
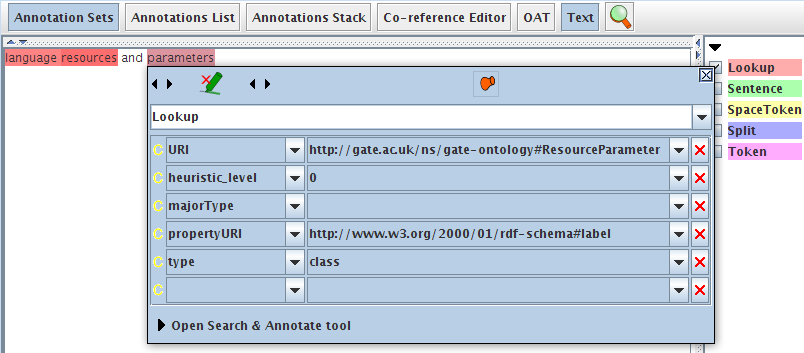
- Run CAT App application and open query-doc to see a set of Lookup annotations generated as a result (see Figure 13.4).
Hard way [#]
OntoRoot Gazetteer can easily be set up to be used with any ontology. To generate a GATE application which demonstrates the use of the OntoRoot Gazetteer, follow these steps:
- Start GATE
- Load necessary plugins: Click on Manage CREOLE plugins and check the following:
- Tools
- Ontology
- Ontology_Based_Gazetteer
- Ontology_Tools (optional); this parameter is required in order to view ontology using the GATE Ontology Editor.
- ANNIE.
Make sure that these plugins are loaded from GATE/plugins/[plugin_name] folder.
- Load an ontology. Right click on Language Resource, and select the last option to create an OWLIM Ontology LR. Specify the format of the ontology, for example rdfXmlURL, and give the correct path to the ontology: either the absolute path on your local machine such as c:/myOntology.owl or the URL such as http://gate.ac.uk/ns/gate-ontology. Specify the name such as myOntology (this is optional).
- Create Processing Resources: Right click on the Processing Resource and create the following
PRs (with default parameters):
- Document Reset PR
- ANNIE English Tokeniser
- ANNIE POS Tagger
- GATE Morphological Analyser
- RegEx Sentence Splitter (or ANNIE Sentence Splitter)
- Create an Onto Root Gazetteer and set the init parameters. Mandatory ones are:
- Ontology: select previously created myOntology;
- Tokeniser: select previously created Tokeniser;
- POS Tagger: select previously created POS Tagger;
- Morpher: select previously created Morpher.
OntoRoot gazetteer is quite flexible in that it can be configured using the optional parameters. List of all parameters is detailed in Section 13.9.2.
When all parameters are set click OK. It can take some time to initialise OntoRoot Gazetteer. For example, loading GATE knowledge base from http://gate.ac.uk/ns/gate-kb takes around 6-15 seconds. Larger ontologies can take much longer.
- Create another PR which is a Flexible Gazetteer. As init parameters it is mandatory to select previously created OntoRoot Gazetteer for gazetteerInst. For another parameter, inputFeatureNames, click on the button on the right and when prompt with a window, add ’Token.root’ in the provided textbox, then click Add button. Click OK, give name to the new PR (optional) and then click OK.
- Create an application. Right click on Application, then New Pipeline (or Corpus Pipeline).
Add the following PRs to the application in this particular order:
- Document Reset PR
- RegEx Sentence Splitter (or ANNIE Sentence Splitter)
- ANNIE English Tokeniser
- ANNIE POS Tagger
- GATE Morphological Analyser
- Flexible Gazetteer
- Create a document to process with the new application; for example, if the ontology was http://gate.ac.uk/ns/gate-kb, then the document could be the GATE home page: http://gate.ac.uk. Run application and then investigate the results further. All annotations are of type Lookup, with additional features that give details about the resources they are referring to in the given ontology.
13.10 Large KB Gazetteer [#]
The large KB gazetteer provides support for ontology-aware NLP. You can load any ontology from RDF and then use the gazetteer to obtain lookup annotations that have both instance and class URI.
The large KB gazetteer is available as the plugin Gazetteer_LKB.
The current version of the large KB gazetteer does not use GATE ontology language resources. Instead, it uses its own mechanism to load and process ontologies. The current version is likely to change significantly in the near future.
The Large KB gazetteer grew from a component in the semantic search platform Ontotext KIM. The gazetteer is developed by people from the KIM team (see http://nmwiki.ontotext.com/lkb_gazetteer/team-list.html). You may find the name kim left in several places in the source code, documentation or source files.
13.10.1 Quick usage overview
- To use the Large KB gazetteer, set up your dictionary first. The dictionary is a folder with some configuration files. Use the samples at GATE_HOME/plugins/Gazetteer_LKB/samples as a guide or download a prebuilt dictionary from http://ontotext.com/kim/lkb_gazetteer/dictionaries.
- Load GATE_HOME/plugins/Gazetteer_LKB as a CREOLE plugin. See Section 3.5 for details.
- Create a new ‘Large KB Gazetteer’ processing resource (PR). Put the folder of the dictionary you created in the ‘dictionaryPath’ parameter. You can leave the rest of the parameters as defaults.
- Add the PR to your GATE application. The gazetteer doesn’t require a tokenizer or the output of any other processing resources.
- The gazetteer will create annotations with type ‘Lookup’ and two features; ‘inst’, which contains the URI of the ontology instance, and ‘class’ which contains the URI of the ontology class that instance belongs to.
13.10.2 Dictionary setup
The dictionary is a folder with some configuration files. You can find samples at GATE_HOME/plugins/Gazetteer_LKB/samples.
Setting up your own dictionary is easy. You need to define your RDF ontology and then specify a SPARQL or SERQL query that will retrieve a subset of that ontology as a dictionary.
config.ttl is a Turtle RDF file which configures a local RDF ontology or connection to a remote Sesame RDF database.
If you want to see examples of how to use local RDF files, please check samples/dictionary_from_local_ontology/config.ttl. The Sesame repository configuration section configures a local Ontotext SwiftOWLIM database that loads a list of RDF files. Simply create a list of your RDF files and reuse the rest of the configuration. The sample configuration support datasets with 10,000,000 triples with acceptable performance. For working with larger datasets, advanced users can substitute SwiftOWLIM with another Sesame RDF engine. In that case, make sure you add the necessary JARs to the list in GATE_HOME/plugins/Gazetteer_LKB/creole.xml. For example, Ontotext BigOWL is a Sesame RDF engine that can load billions of triples on desktop hardware.
Since any Sesame repository can be configured in config.ttl, the Large KB Gazetteer can extract dictionaries from all significant RDF databases. See the page on database compatibility for more information.
query.txt contains a SPARQL query. You can write any query you like, as long as its projection contains at least two columns in the following order: label and instance. As an option, you can also add a third column for the ontology class of the RDF entity. Below you can see a sample query, which creates a dictionary from the names and the unique identifiers of 10,000 entertainers in DbPedia.
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?Name ?Person WHERE {
?Person a opencyc:Entertainer ; rdfs:label ?Name .
FILTER (lang(?Name) = "en")
} LIMIT 10000
Try this query at the Linked Data Semantic Repository.
When you load the dictionary configuration in GATE for the first time, it creates a binary snapshot of the dictionary. Thereafter it will load only this binary snapshot. If the dictionary configuration is changed, the snapshot will be reinitialized automatically. For more information, please see the dictionary lifecycle specification.
13.10.3 Additional dictionary configuration
The config.ttl may contain additional dictionary configuration. Such configuration concerns only the initial loading of the dictionary from the RDF database. The options are still being determined and more will appear in future versions. They must be placed below the repository configuration section as attributes of a dictionary configuration. Here is a sample config.ttl file with additional configuration.
#
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>.
@prefix rep: <http://www.openrdf.org/config/repository#>.
@prefix hr: <http://www.openrdf.org/config/repository/http#>.
@prefix lkbg: <http://www.ontotext.com/lkb_gazetteer#>.
[] a rep:Repository ;
rep:repositoryImpl [
rep:repositoryType "openrdf:HTTPRepository" ;
hr:repositoryURL <http://ldsr.ontotext.com/openrdf-sesame/repositories/owlim>
];
rep:repositoryID "owlim" ;
rdfs:label "LDSR" .
[] a lkbg:DictionaryConfiguration ;
lkbg:caseSensitivity "CASE_INSENSITIVE" .
13.10.4 Processing Resource Configuration
The following options can be set when the gazetteer PR is initialized:
- dictionaryPath; the dictionary folder described above.
- forceCaseSensitive; whether the gazetteer should return case-sensitive matches regardless of the loaded dictionary.
13.10.5 Runtime configuration
- annotationSetName - The annotation set, which will receive the generated lookup annotations.
- annotationLimit - The maximum number of the generated annotations. NULL or 0 for no limit. Setting limit of the number of the created annotations will reduce the memory consumption of GATE on large documents. Note that GATE documents consume gigabytes of memory if there are tens of thousands of annotations in the document. All PRs that create large number of annotations like the gazetteers and tokenizers may cause an Out Of Memory error on large texts. Setting that options limits the amount of memory that the gazetteer will use.
13.10.6 Semantic Enrichment PR
The Semantic Enrichment PR allows adding new data to semantic annotations by querying external RDF (Linked Data) repositories. It is a companion to the large KB gazetteer that showcases the usefulness of using Linked Data URI as identifiers.
Here a semantic annotation is an annotation that is linked to an RDF entity by having the URI of the entity in the ‘inst’ feature of the annotation. For all such annotation of a given type, this PR runs a SPARQL query against the defined repository and puts a comma-separated list of the values mentioned in the query output in the ‘connections’ feature of the same annotation.
There is a sample pipeline that features the Semantic Enrichment PR.
Parameters
- inputASName; the annotation set, which annotation will be processed.
- server; the URL of the Sesame 2 HTTP repository. Support for generic SPARQL endpoints can be implemented if required.
- repositoryId; the ID of the Sesame repository.
- annotationTypes; a list of types of annotation that will be processed.
- query; a SPARQL query pattern. The query will be processed like this - String.format(query, uriFromAnnotation), so you can use parameters like %s or %1$s.
- deleteOnNoRelations; whether we want to delete the annotation that weren’t enriched. Helps to clean up the input annotations.
13.11 The Shared Gazetteer for multithreaded processing [#]
The DefaultGazetteer (and its subclasses such as the OntoRootGazetteer) compiles its gazetteer data into a finite state matcher at initialization time. For large gazetteers this FSM requires a considerable amount of memory. However, once the FSM has been built then (as long as you do not modify it dynamically using Gaze) it is accessed in a read-only manner at runtime. For a multi-threaded application that requires several identical copies of its processing resources (see section 7.13), GATE provides a mechanism whereby a single compiled FSM can be shared between several gazetteer PRs that can then be executed concurrently in different threads, saving the memory that would otherwise be required to load the lists several times.
This feature is not available in the GATE Developer GUI, as it is only intended for use in embedded code. To make use of it, first create a single instance of the regular DefaultGazetteer or OntoRootGazetteer:
params.put("listsUrl", listsDefLocation);
LanguageAnalyser mainGazetteer = (LanguageAnalyser)Factory.createResource(
"gate.creole.gazetteer.DefaultGazetteer", params);
Then create any number of SharedDefaultGazetteer instances, passing this regular gazetteer as a parameter:
params.put("bootstrapGazetteer", mainGazetteer);
LanguageAnalyser sharedGazetteer = (LanguageAnalyser)Factory.createResource(
"gate.creole.gazetteer.SharedDefaultGazetteer", params);
The SharedDefaultGazetteer instance will re-use the FSM that was built by the mainGazetteer instead of loading its own.
1An ontology resource is usually identified by an URI concatenated with a set of characters starting with ‘#’. This set of characters is called fragment identifier. For example, if the URI of a class representing GATE POS Tagger is: ’http://gate.ac.uk/ns/gate-ontology#POSTagger’, the fragment identifier will be ’POSTagger’.
