Chapter 16
Tools for Alignment Tasks [#]
16.1 Introduction
This chapter introduces a new plugin called ‘Alignment’ that comprises of tools to perform text alignment at various level (e.g word, phrase, sentence etc). It allows users to integrate other tools that can be useful for speeding up the alignment process.
Text alignment can be achieved at a document, section, paragraph, sentence and a word level. Given two parallel corpora, where the first corpus contains documents in a source language and the other in a target language, the first task is to find out the parallel documents and align them at the document level. For these tasks one would need to refer to more than one document at the same time. Hence, a need arises for Processing Resources (PRs) which can accept more than one document as parameters. For example given two documents, a source and a target, a Sentence Alignment PR would need to refer to both of them to identify which sentence of the source document aligns with which sentence of the target document. However, the problem occurs when such a PR is part of a corpus pipeline. In a corpus pipeline, only one document from the selected corpus at a time is set on the member PRs. Once the PRs have completed their execution, the next document in the corpus is taken and set on the member PRs. Thus it is not possible to use a corpus pipeline and at the same time supply for than one document to the underlying PRs.
16.2 The Tools [#]
We have introduced a few new resources in GATE that allows processing parallel data. These include resources such as CompoundDocument, CompositeDocument, and a new AlignmentEditor to name a few. Below we describe these components. Please note that all these resorces are distributed as part of the ‘Alignment’ plugin and therefore the users should load the plugin first in order to use these resources.
16.2.1 Compound Document [#]
A new Language Resource (LR), called CompoundDocument, is introduced which is a collection of documents and allow various documents to be grouped together under a single document. The CompoundDocument allows adding more documents to it and removing them if required. It implements the gate.Document interface allowing users to carry out all operations that can be done on a normal gate document. For example, if a PR such as Sentence Aligner needs access to two documents (e.g. source and target documents), these documents can be grouped under a single compound document and supplied to the Sentence Alignment PR.
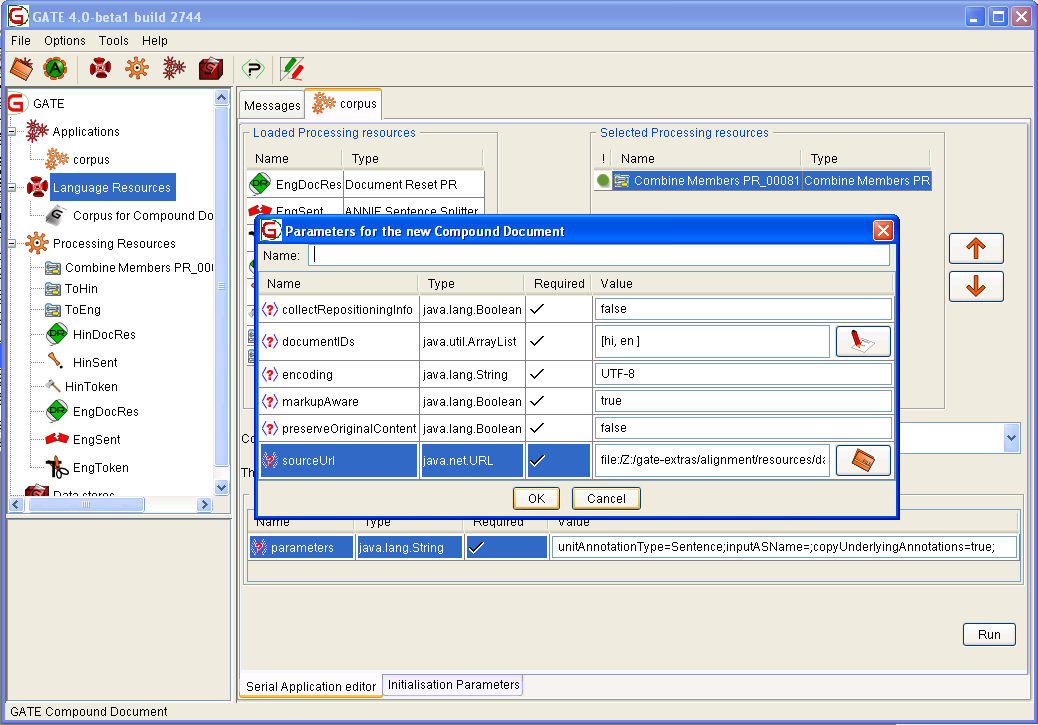
To instantiate CompoundDocument user needs to provide the following parameters.
- encoding - encoding of the member documents. All document members must have the same encoding (e.g. Unicode, UTF-8, UTF-16).
- collectRepositioningInfo - this parameter indicates whether the underlying documents should collect the repositioning information in case the contents of these documents change.
- preserveOriginalContent - if the original content of the underlying documents should be preserved.
- documentIDs - users need to provide a unique ID for each document member. These ids are used to locate the appropriate documents.
- sourceUrl - given a URL of one of the member documents, the instance of CompoundDocument
searches for other members in the same folder based on the ids provided in the documentIDs
parameter. Following document name conventions are followed to search other member
documents:
- FileName.id.extension (filename followed by id followed the extension and all of these separated by a ‘.’ (dot)).
- For example if user provides three document IDs (e.g. ‘en’, ‘hi’ and ‘gu’) and selects a file with name ‘File.en.xml’, the CompoundDocument will search for rest of the documents (i.e. ‘File.hi.xml’ and ‘File.gu.xml’). The file name (i.e. ‘File’) and the extension (i.e. ‘xml’) remain common for all three members of the compound document.
Figure 16.1 shows a snapshot for instantiating a compound document from GATE Developer.
Compound document provides various methods that help in accessing their individual members.
public Document getDocument(String docid);
|
The following method returns a map of documents where the key is a document ID and the value is its respective document.
public Map getDocuments();
|
Please note that only one member document in a compound document can have focus set on it. Then all the standard document methods of gate.Document interface apply to the document with focus set on it. For example, if there are two documents, ‘hi’ and ‘en’, and the focus is set on the document ‘hi’ then the getAnnotations() method will return a default annotation set of the ‘hi’ document. One can use the following method to switch the focus of a compound document to a different document:
public void setCurrentDocument(String documentID);
public Document getCurrentDocument(); |
As explained above, new documents can be added to or removed from the compound document using the following method:
public void addDocument(String documentID, Document document);
public void removeDocument(String documentID); |
The following code snippet demonstrates how to create a new compound document using GATE Embedded:
1
2// step 1: initialize GATE
3Gate.init();
4
5// step 2: load the Alignment plugin
6File alignmentHome = new File(Gate.getPluginsHome(),‘Alignment’);
7Gate.getCreoleRegister().addDirectory(ontoHome.toURL());
8
9// step 3: set the parameters
10FeatureMap fm = Factory.newFeatureMap();
11
12// for example you want to create a compound document for
13// File.id1.xml and File.id2.xml
14List docIDs = new ArrayList();
15docIDs.add(‘id1’);
16doicIDs.add(‘id2’);
17fm.put(‘documentIDs’, docIDs);
18fm.ptu(‘sourceURL’, new URL(‘file://z:/data/File.id1.xml’));
19
20// step 4: finally create an instance of compound document
21Document aDocument = (gate.compound.CompoundDocument)
22 Factory.createResource(‘gate.compound.impl.CompoundDocumentImpl’, fm);
16.2.2 Compound Document Editor [#]
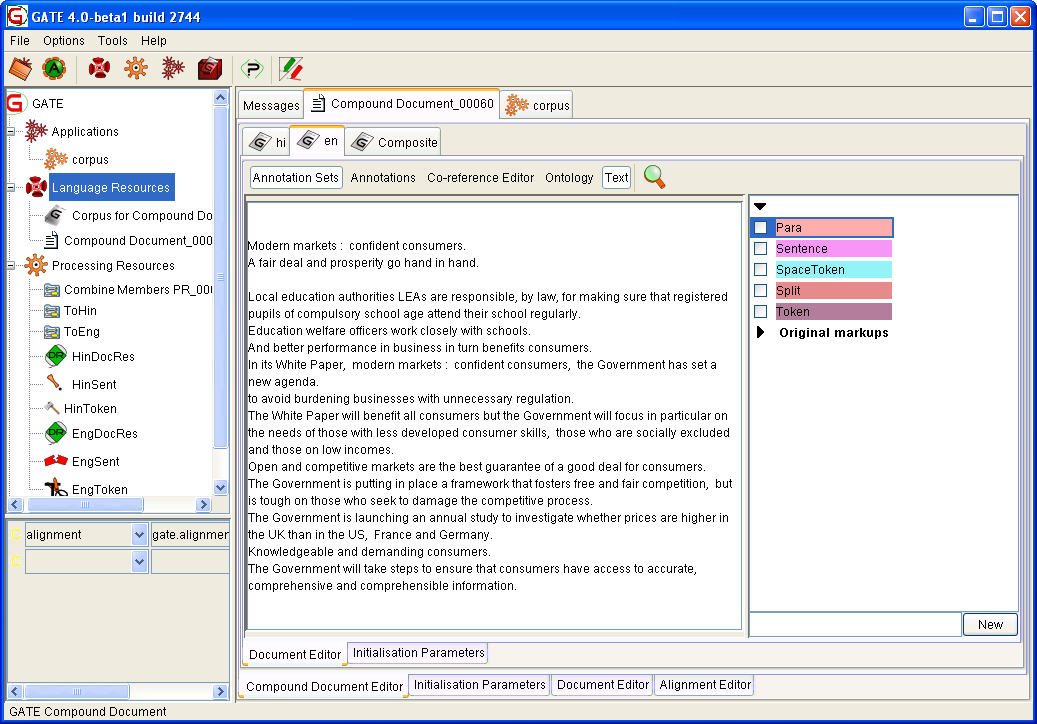
The compound document editor is a visual resource (VR) associated with the compound document. The VR contains several tabs - each representing a different member of the compound document. All standard functionalities such as GATE document editor, with all its add-on plugins such as AnnotationSetView, AnnotationsList, coreference editor etc., are available to be used with each individual member.
Figure 16.2 shows a compound document editor with English and Hindi documents as members of the compound document.
16.2.3 Composite Document [#]
The composite document allows users to merge the texts of member documents and keep the merged text linked with their respective member documents. In other words, if users make any change to the composite document (e.g. add new annotations or remove any existing annotations), the relevant effect is made to their respective documents.
A PR called CombineMembersPR allows creation of a new composite document. It asks for a class name that implements the CombiningMethod interface. The CombiningMethod tells the CombineMembersPR how to combine texts and create a new composite document.
For example, a default implementation of the CombiningMethod, called DefaultCombiningMethod, takes the following parameters and puts the text of the compound document’s members into a new composite document.
unitAnnotationType=Sentence
inputASName=Key copyUnderlyingAnnotations=true; |
The first parameter tells the combining method that it is the ‘Sentence’ annotation type whose text needs to be merged and it should be taken from the ‘Key’ annotation set (second parameter) and finally all the underlying annotations of every Sentence annotation must be copied in the composite document.
If there are two members of a compound document (e.g. ‘hi’ and ‘en’), given the above parameters, the combining method finds out all the annotations of type Sentence from each document and sorts them in ascending order, and one annotation from each document is put one after another in a composite document. This operation continues until all the annotations have been traversed.
Document en Document hi
Sen1 Shi1 Sen2 Shi2 Sen3 Shi3 Document Composite Sen1 Shi1 Sen2 Shi2 Sen3 Shi3 |
The composite document also maintains a mapping of text offsets such that if someone adds a new annotation to or removes any annotation from the composite document, they are added to or removed from their respective documents. Finally the newly created composite document becomes a member of the same compound document.
16.2.4 DeleteMembersPR [#]
This PR allows deletion of a specific member of the compound document. It takes a parameter called ‘documentID’ and deletes a document with this name.
16.2.5 SwitchMembersPR [#]
As described above, only one member of the compound document can have focus set on it. PRs trying to use the getDocument() method get a pointer to the compound document; however all the other methods of the compound document give access to the information of the document member with the focus set on it. So if user wants to process a particular member of the compound document with some PRs, s/he should use the SwitchMembersPR that takes one parameter called documentID and sets focus to the document with that specific id.
16.2.6 Saving as XML [#]
Calling the toXml() method on a compound document returns the XML representation of the member which has focus. However, GATE Developer provides an option to save all member documents in different files. This option appears in the options menu when the user right-clicks on the compound document. The user is asked to provide a name for the directory in which all the members of the compound document will be saved in separate files.
It is also possible to save all members of the compound document in a single XML file. The option, ‘Save in a single XML Document’, also appears in the options menu. After saving it in a single XML document, the user can use the option ‘Compound Document from XML’ to load the document back into GATE Developer.
16.2.7 Alignment Editor [#]
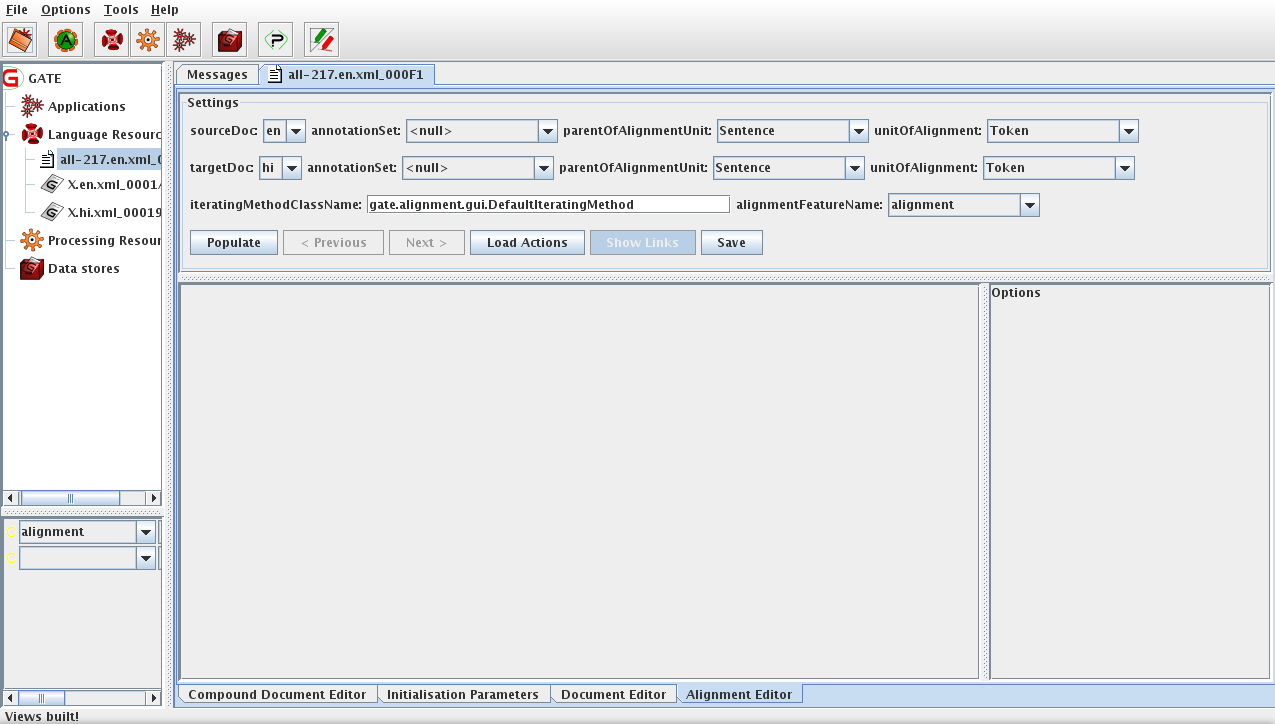
A new Visual Resource (VR) called AlignmentEditor has been implemented (Figure 16.3 and 16.4) and is attached with every compound document. As the name suggest, the purpose of the AlignmentEditor is to allow users to align texts from different members of the compound document at the section, paragraph, sentence and word level. It provides a user-friendly interface in which to perform manual text alignment.
The user is asked to provide certain parameters based on the requirements of the task. Once the task has been set up, the user is shown some text and is asked to align it. An instance of the gate.alignment.Alignment class is created and stored as a document feature on the compound document. This object is then used for storing all the alignment information such as which annotation is aligned with which annotations of what document and so on.
The parameters needed for setting up a new alignment task are as follows:
- Source and Target Documents: The user is asked to choose one of the members of the compound document as a source document and an another one as a target document.
- Annotation Sets: Users are also asked to choose relevant annotation sets in both the source and the target documents that need to be aligned.
- Unit Of Alignment: This is the annotation type that users want to perform alignment on. For example, if users want to align the text at a word level, they will need to process their documents with a tokenizer (e.g. ANNIE English Tokenizer) to generate tokens and provide Token as a unit of alignment.
- Parent Of Unit Of Alignment: Generally, if performing a word alignment task, people consider a pair of aligned sentences, one in a source language and the other one in the target language. Thus, the ‘Sentence’ is a parent of unit of alignment. In other words, users should also process their documents with a sentence splitter (e.g. ANNIE Sentence Splitter) that identifies the boundaries of the sentences and creates an annotation for each sentence in the text.
- Iterating Method: If the parent of the unit of alignment is Sentence, it is essential to know the order in which sentences from the source and the target documents should be paired together. For example, one could simply specify to pair one sentence from the source document with one sentence from the target document in the order in which they appear in their documents. However, it is possible that the sentences in both documents are not in the correct order or one sentence from the source document refers to more than one sentence in the target document or vice versa. To make it customizable, this parameter allows users to specify a class that implements the gate.alignment.gui.IteratingMethod interface. The implementing class is seen as an iterator with a next() method that returns an object of gate.alignment.gui.Pair, one at a time. One such default implementation, gate.alignment.gui.DefaultIteratingMethod, is provided that takes two annotations (of type parent of unit of alignment), one from each, the source and the target documents, in their order of appearance, and forms a pair.
- Alignment Feature Name: Information about the alignment (i.e. which annotation is aligned with what annotation) is stored as a document feature. Using this parameter, user can specify the name of the feature that should be used to store the alignment information.
Document en Document hi
Sen1 Shi1 Sen2 Shi2 Sen3 Shi3 |
Given a compound document with two members (en and hi) as shown above, if the user selects ‘en’ as a source document, ‘hi’ as a target document, ‘Key’ as an input annotation set, ‘Sentence’ as a parent of unit of alignment, ‘Token’ as a value for unit of alignment and ‘gate.alignment.gui.DefaultIteratingMethod’ as an iterating method, pairs will be created in the following manner.
Pair1 Sen1 Shi1
Pair2 Sen2 Shi2 Pair3 Sen3 Sen3 |
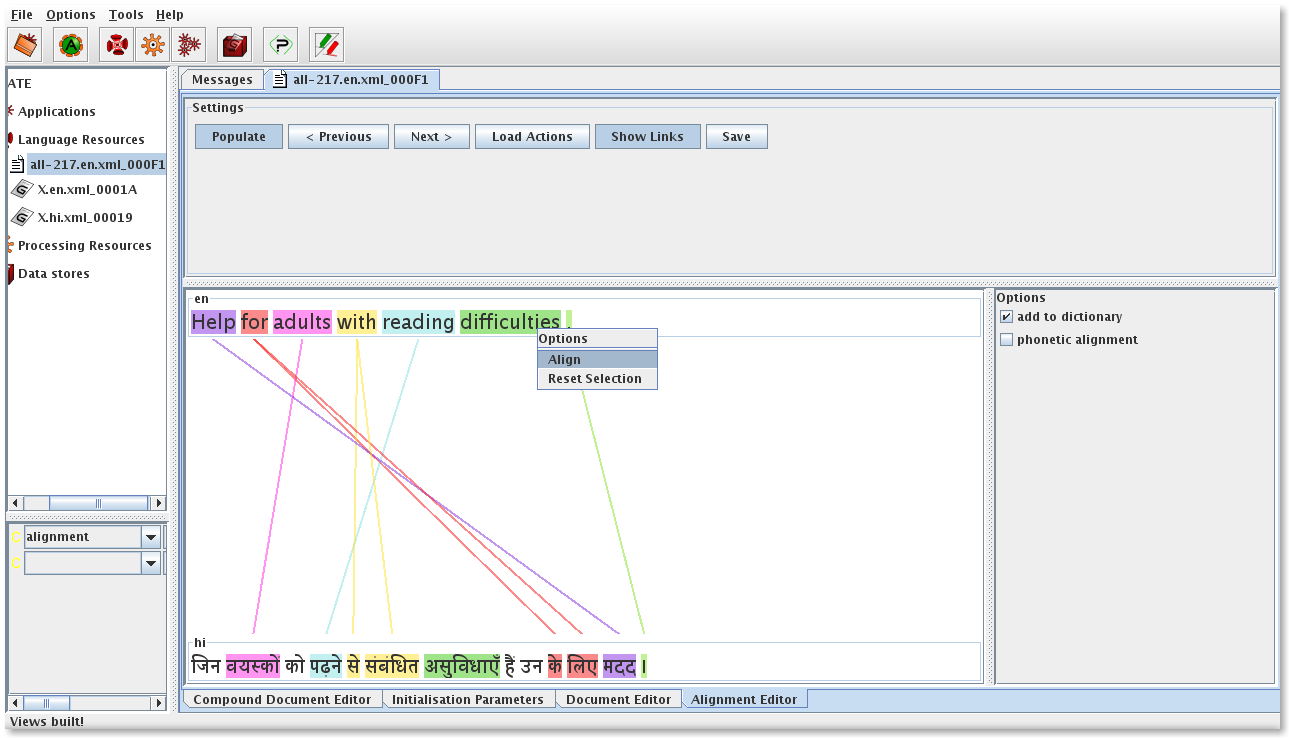
Each of these pairs is shown one at a time. If the user clicks on the next button, the next pair of sentences is shown. Similarly clicking on the previous button brings up the previous pair. In each of these sentences, the individual tokens are highlighted with a default colour (to mark the boundary for each unit of alignment). In order to align one or more units in the source language with one or more units in the target language, the user needs to select them by clicking on them individually. Clicking on units highlights them with an identical colour. Right-clicking on any of the selected units brings up a menu with ‘Align’ and ‘Reset Selection’ options. The user can select ‘Align’ to align the selected units or can select the ‘Reset Selection’ option to reset the selection. If the annotations are unaligned, they are highlighted with the same color and a link (a line with the same color) between them is shown. In order to unalign them, the user needs to right-click on the aligned annotation and click on the ‘Remove Alignment’ option. If the annotation is part of a one-to-one alignment, both the annotations (i.e. the source and the target annotations) are unaligned. However, if there is another annotation in the same pair and the same document that is aligned with the same annotations in the target document, the annotation on which the user right-clicks is taken out of the alignment leaving the rest of the annotations still aligned.
Currently there is no implementation provided to export this alignment information, but one could easily write a PR that reads the information and export it to his/her desired format.
Advanced Features [#]
The editor also allows adding more actions to the editor. There are in total three different types of actions:
- PreDisplayAction
- AlignmentAction
- FinishAlignmentAction
When users click on the next or previous button, the editor obtains a pair to be shown in the editor. Before it is displayed, the editor calls the registered instances of the PreDisplayAction and passes them the pair object. This could be helpful in allowing a pair to be preprocessed before it is displayed in the editor. For example, a wrapper could be written for a word alignment algorithm that identifies word alignments in the given sentence pair. More information on the methods of the PreDisplayAction interface can be found in the javadoc.
In the case of the word alignment scenario, when a sentence pair is displayed, users can align new words and delete existing ones if needed. This can be achieved by clicking on the relevant buttons in the options menu. All buttons that appear in the options menu are instances of the AlignmentAction. As explained earlier, ‘Align’, ‘Reset Selection’ and ‘Remove Alignments’ are the three default buttons that are available to users. The editor also has an ‘options tab’ where users are allowed to add new actions. Users wishing to add new options to this tab or to the options menu need to provide their own implementations of the AlignmentAction interface. Below we list some of the methods of the AlignmentAction interface.
- public boolean invokeForAlignedAnnotation()
- public boolean invokeForHighlightedUnalignedAnnotation()
- public boolean invokeForUnhighlightedUnalignedAnnotation()
- public boolean invokeWithAlignAction()
- public boolean invokeWithRemoveAction()
- getCaption()
Users may make the visibility of these buttons conditional. For example, the ‘Align’ button appears only when users select unaligned units. The ‘Remove Alignments’ button appears only when users right- click on any of the aligned units. This can be controlled with the help of first three methods as specified above. For example the method ‘invokeForAlignedAnnotation()’ indicates that the button should only appear when users right-click on any of the unaligned units.
It is also possible that users might want to perform additional tasks when they click on any of the ‘Align’ or the ‘Remove Alignment’ buttons. For example, users can build a dictionary with new entries while aligning word pairs. In this case, an additional task of adding new entries to the dictionary can be performed when the ‘Align’ button is clicked. On the other hand, not all entries that users align should be included in the dictionary. For the ones which aligners think should go in dictionary, they might want to ask the editor to add them explicitly. All these issues can be controlled by returning appropriate values for the last two methods of the AlignmentAction interface (i.e. invokeWithAlignAction() and invokeWithRemoveAction()).
It is important to note that the new option is added either to the options tab or to the options menu. Users wishing to add it as a button to the options menu must return ‘false’ for the invokeWithAlignAction() and invokeWithRemoveAction() methods. Users wishing to add it to the options tab, must return true for at least one of these two methods. In case of the latter, the getCaption() method is used for obtaining a string that is used for creating a checkbox which is then added to the options tab. When users click on the ‘Align’ or ‘Remove Alignment’ button, the editor also calls the respective actions for the checked checkboxes.
Last of the three types of actions is FinishedAlignmentAction. Before users click on the ‘next’ button, they are asked if the pair they were aligning has been aligned completely; in other words, if there is any alignment unit left that still needs to be aligned. If the alignment is complete, the registered instances of the FinishedAlignmentAction interface are called. This could be helpful in writing an alignment exporter that takes an aligned pair as input and exports it in an appropriate format.
How to register actions? Having implemented various actions, users need to register them with the alignment editor. In order to do so, users can click on the ‘Load Actions’ button. The user is prompted to provide a configuration file. A configuration file is a simple text file with fully-qualified class names specified in it. After the class name, users can specify any necessary parameters (delimited by a comma sign) that they wish to pass to respective actions classes when they are initialized. Below, we give an example of such an entry in the actions configuration file.
#use the class DictionaryBuilder and pass the ‘/user-home/dictionary.txt’ and
‘root’ as two parameters to the init method of the class. gate.alignment.actions.DictionaryBuilder,/user-home/dictionary.txt,root |
16.2.8 Section-by-Section Processing [#]
In this section, we describe a component that allows processing documents section-by-section. Processing documents this way is useful for many reasons:
For example, a patent document has several different sections but user is interested in processing only the ‘claims’ section or the ‘technical details section’. This is also useful for processing a large document where processing it as a single document is not possible and the only alternative is to divide it in several small documents to process them independently. However, doing so would need another process that merges all the small documents and their annotations back into the original document. On the other hand, a webpage may contain profiles of different people. If the document has more than one person with similar names, running the ‘Orthomatcher PR’ on such a document would produce incorrect coreference chains.
All such problems can be solved by using a PR called ‘Segment Processing PR’. This PR is distributed as part of the ‘Alignment’ plugin. User needs to provide the following four parameters to run this PR.
- document: This is the document to be processed.
- controller: This is a corpus controller that needs to be used for processing the segments of the document.
- segmentAnnotationType: Sections of the documents (that need to be processed) should be annotated with some annotation type and the type of such annotation should be provided as the value to this parameter.
- inputASName: This is the name of the annotation set that contains the segment annotations.
Given these parameters, each span in the document that is annotated as the type specified by the segmentAnnotationType is processed independently.
Given a corpus of publications, if you just want to process the abstract section with the ANNIE application, please follow the following steps. It is assumed that the boundaries of abstracts in all these publications are already identified. If not, you would have to do some processing to identify them prior to using the following steps. In the following example, we assume that the abstract boundaries have been annotated as ‘Abstract’ annotations and stored under the ‘Original markups’ annotation set.
Steps:
- Create a new corpus and populate it with a set of publications that you would like to process with ANNIE.
- Load the ANNIE application.
- Load the ‘Alignment’ plugin.
- Create an instance of the ‘Segment Processing PR’ by selecting it from the list of processing resources.
- Create a corpus pipeline.
- Add the ‘Segment Processing PR’ into the pipeline and provide the following
parameters:
- Provide the corpus with publication documents in it as a parameter to the corpus controller.
- Select the ‘ANNIE’ controller for the ‘controller’ parameter.
- Type ‘Abstract’ in the ‘segmentAnnotationType’ parameter.
- Type ‘Original markups’ in the ‘inputASName’ parameter.
- Run the application.
Now, you should see that the ANNIE application has only processed the text in each document that was annotated as ‘Abstract’.
