Topic and sentiment analysis: What are the politicians talking about?
The GATE team at the University of Sheffield are working with Nesta to create the Political Futures Tracker, a tool providing near-real time analysis of political texts in the run-up to the 2015 UK General Election. It hones in on key topics, future thinking and sentiment, as they unfold on Twitter, party websites and manifestos, and in political speeches and other relevant web material.
The Political Futures Tracker enables us to analyse the levels of future thinking and sentiment in texts, as well as to identify key content and themes that politicians are writing and speaking about. In a previous blog post, we have introduced the idea behind the tracker. In this post, we describe some of the key technical language analysis components behind the tool.
The toolkit is developed in GATE, a widely used and open source framework for natural language processing. Within GATE, we have created tools for text analytics of social media, namely the automatic recognition of named entities (people, places, organisations, dates etc.), topics (general themes, e.g. "the EU", "climate change", "economy" and so on), and sentiment analysis (detecting opinions and other related information). Once the texts have been analysed, we can search the entire data collection for queries such as “give me all documents where a Welsh MP is being negative about Scotland”.
Topic Detection
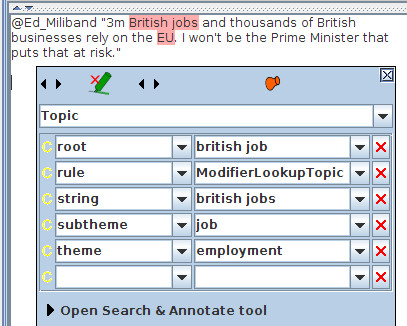
The named entities are detected using GATE's core information extraction tools ANNIE and TwitIE. Topic detection is performed by classifying terms according to the set of key themes used on the .gov.uk web pages, such as “borders and immigration”, “UK economy”, “environment”, etc. To classify the terms, we first created sets of gazetteer lists - one for each theme - and performed direct matching against these keywords. We extended this via a set of JAPE rules in order to also match terms which were Noun Phrases and matched a head or modifier word in a list. For example, if we have the term “jobs” in a list as a head word, and we find the string “British jobs” in the text, annotated as a noun phrase, we can perform a match, as shown below. This means that we do not have to pre-specify every possible keyword in the text in advance, as this matching can be done on the fly. Each topic matched gets allocated not only a theme (the topic matched) but also a sub-theme which is based on the root form of the term. This enables variations of terms to be collected together (i.e. in our example, all variations of “job” would be grouped together - this is useful for later visualisations of important topics and themes).
Sentiment detection
The idea behind the sentiment detection component is to find out what kinds of opinions the MPs and candidates are expressing about the topics described above. This is in contrast with most of the existing pre-election social media analysis tools, which are focusing on public sentiment and which parties are becoming more or less favourable (and ultimately attempting to predict the election results themselves).
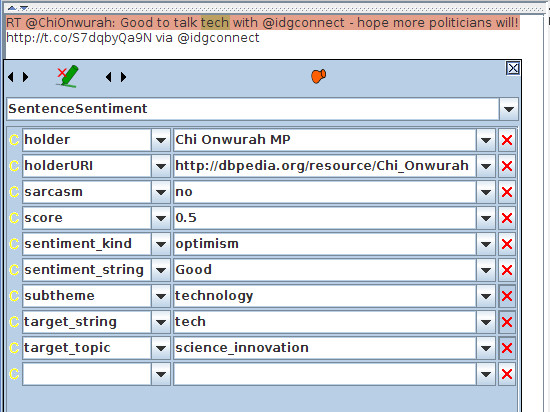
The sentiment detection component is based on an adaptation of our core rule-based sentiment analysis tools used in GATE. Adapted gazetteer lists of positive and negative words, as well as other indicators such as swear words, emoticons, sarcastic indicators and so on, are combined with a set of JAPE rules to determine the nature and strength of the sentiment (positive or negative), who the opinion holder is, what topic the sentiment refers to, and whether it is sarcastic or not. The rules for sentiment strength and score combine a number of linguistic features such as adverbs, negation, conditional sentences, questions, swear words, sarcasm indicators and so on. Further rules then attempt to link the correct opinion holder and topic with the sentiments found, if more than one exist within the same tweet or sentence. These essentially operate by chopping the tweet or sentence into phrases and preferring closest matches within phrases, but considering also the confines of any linguistic constraints such as conditionals. The image below shows a screenshot of an annotated tweet depicting positive sentiment towards the topic of technology by MP Chi Onwurah, the author of the tweet.
Making sense of the information
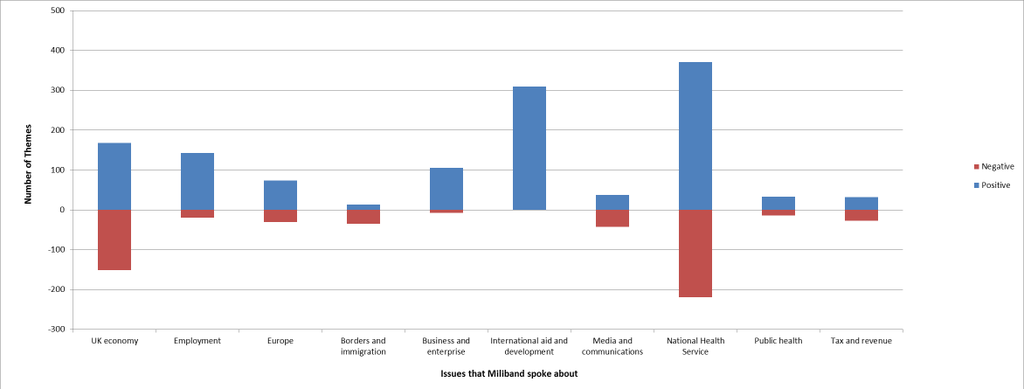
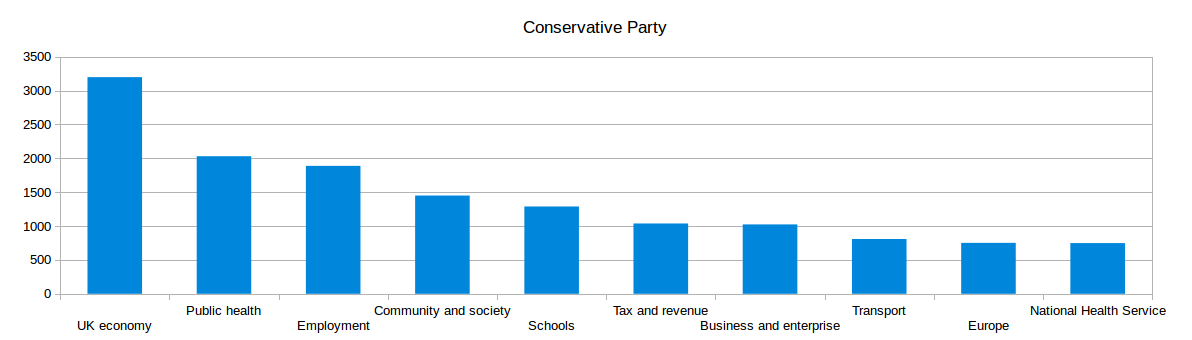
Information about individual tweets and their sentiments is not particularly useful on its own; however, it can provide valuable insight when combined with powerful search and visualisation tools and when large volumes of social media are analysed. For example, if we look at the top 10 topics mentioned by politicians from different parties, patterns start to emerge. The graphs below show, for instance, that the Labour party talk about the NHS more than the Conservative party does, but less about schools.
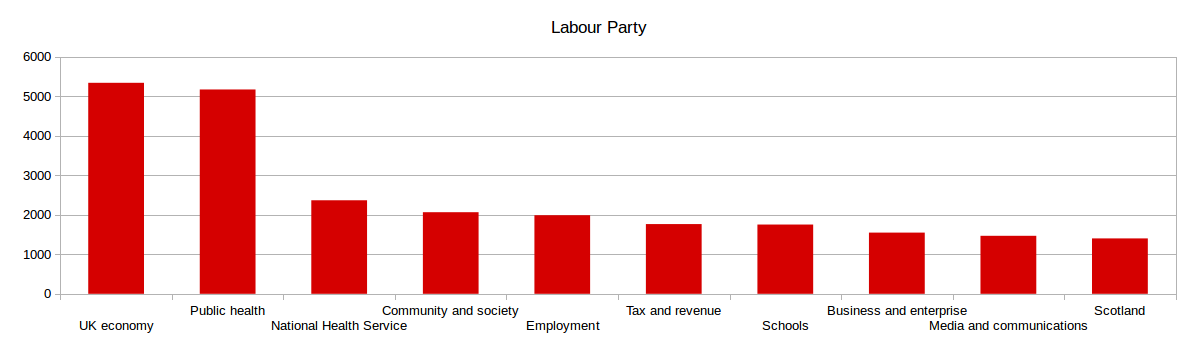
Similarly, we can aggregate sentiment about tweets on each topic to get interesting perspectives. During the television debates, we analysed sentiment of the public (via their tweets) about the major topics discussed by each political leader - here we see that sentiment was broadly positive for Ed Milliband, but that when he talked about the NHS and the economy, the public reaction was more negative about these topics.