John Hopkins University Summer Workshop 2003
John Hopkins University Summer Workshop 2003
Semantic Analysis Over Sparse Data
| Louise Guthrie |
Hamish Cunningham |
Roberto Basili |
| Kalina Bontcheva |
David Guthrie |
Fabio Zanzotto |
Klaus Machery |
Jia Cui |
| Martin Holub | Kristiyan Haralambiev | Cassia Faria |
Jerry Cheng-Chieh Liu | Marco Cammisa |
| Frederick Jelinek | Diana Maynard | Valentin Tablan |
Contents
Where?
This page describes the 2003 Summer Workshop at John Hopkins University Centre for Language and Speech Processing. There's also a workshop page at JHU.
Introduction: Semantic Analysis Over Sparse Data.
The aim of the task is to verify the feasibility of a machine learning-based semantic approach to the data sparseness problem that is encountered in many areas of natural language processing such as language modeling, text classification, question answering and information extraction.
The suggested approach takes advantage of several technologies for supervised and unsupervised sense disambiguation that have been developed in the last decade and of several resources that have been made available.
The task is motivated by the fact that current language processing models are considerably affected by sparseness of training data, and current solutions, like class-based approaches, do not elicit appropriate information: the semantic nature and linguistic expressiveness of automatically derived word classes is unclear. Many of these limitations originate from the fact that fine-grained automatic sense disambiguation is not applicable on a large scale.
The workshop will develop a weakly supervised method for sense modeling (i.e. reduction of possible word senses in corpora according to their genre) and apply it to a huge corpus in order to coarsely sense-disambiguate it. This can be viewed as an incremental step towards fine-grained sense disambiguation. The created semantic repository as well as the developed techniques will be made available as resources for future work on language modeling, semantic acquisition for text extraction, question answering, summarization, and most other natural language processing tasks.
What?
The project will produce two things:
- a methodology for performing this type of tagging, with quanitative evaluation results and backed up by open source software that can be used to replicate our experiments at other sites (based partly on GATE);
- a resource of semantic tags applied to the British National Corpus, a widely-used resource of English language usage.
We chose the BNC because it is a very diverse set of texts, as is the Web. The next section discusses some of the motivation of the project relating partly to information processing in the age of the Web.
Why?
Gartner reported in 2002 that for at least the next decade more than 95% of human-to-computer information input will involve textual language. They also report that by 2012 taxonomic and hierachical knowledge mapping and indexing will be prevalent in almost all information-rich applications. The web revolution has been based largely on human language materials, and in making the shift to the next generation knowledge-based web, human language will remain key.
The Semantic Web (SW) is adding a machine-tractable layer to the natural language web of HTML. The Grid initiative is constructing infrastructure for distributed collaborative science, or e-science. Web Services are driving the decomposition of monolithic software into flexible component sets that can be reconfigured to keep ahead in rapidly changing markets. The three areas are closely linked: web technology is essential to the Grid; the Semantic Web and the Grid are co-penetrating to form the Semantic Grid; Web Services underpin the next generation of the Grid in the Open Grid Services Architecture; Semantic Web Services (SWSs) allow dynamic construction of applications from component services, and better service description and discovery.
In each case the use of formal data enables automatic processing, for example by conceptual search engines or personal assistance agents, and it also leads to a certain amount of future-proofing: formal data is more easily repurposed than natural language data.
Together these developments represent the next stage of evolution for the web, distributed computing and collaborative science. Key to the success of the enterprise is the production and maintenance of formal data. The SW and SWSs rely on formal semantics in the shape of ontologies and related instance sets, or knowledge bases. Whereas the simplicity of HTML and the ubiquity of natural language led to the organic growth of the hypertext web, semantic data is harder to create and maintain. HLT provides the missing link between language and formal data, the glue to fix web services to their user constituency and enable easier enterprise integration.
As a practical example, experiments by Bertelsmann's Empolis knowledge technology arm indicate that using IE for semi-automatic indexing of documents can double throughput, e.g. for one client they reduced the average time spent on each document from 9 minutes to 4 minutes.
The web revolution has been based largely on human language materials, and in making the shift to the next generation knowledge-based web, human language will remain key.
The problem is that these are contradictory tendencies: the formal structures that are needed for semantics-based systems are quite different from human language, with all its ambiguity, messy and chaotic nature: how do we tackle this contradiction? A number of NLE techniques are relevant:
- Information Extraction (IE): from NL to formal data
- Adaptive IE: learning by example
- Ontology-based IE: annotate to user-supplied ontology
- Controlled-Language IE: simplify the interface
- (Multilingual) Natural Language Generation: documentation
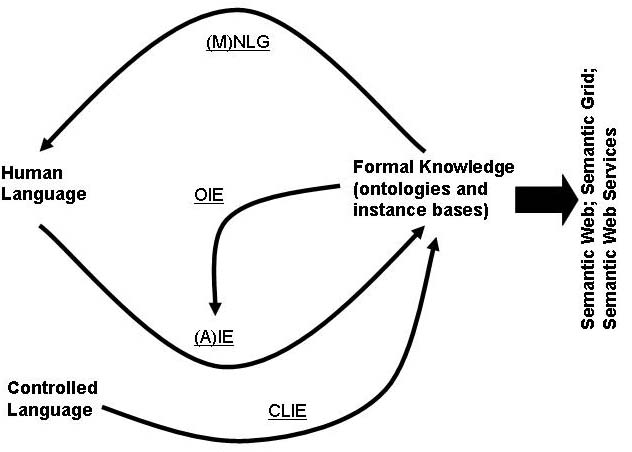
In each case, a corpus of semantically tagged-data will improve the efficiency and portability of the technology.
